Deploying to DeepStream for DetectNet_v2
The deep learning and computer vision models that you’ve trained can be deployed on edge devices, such as a Jetson Xavier or Jetson Nano, a discrete GPU, or in the cloud with NVIDIA GPUs. TAO Toolkit has been designed to integrate with DeepStream SDK, so models trained with TAO Toolkit will work out of the box with DeepStream SDK.
DeepStream SDK is a streaming analytic toolkit to accelerate building AI-based video analytic applications. This section will describe how to deploy your trained model to DeepStream SDK.
To deploy a model trained by TAO Toolkit to DeepStream we have two options:
Option 1: Integrate the
.etltmodel directly in the DeepStream app. The model file is generated by export.Option 2: Generate a device specific optimized TensorRT engine using
tao-deploy. The generated TensorRT engine file can also be ingested by DeepStream.Option 3: (Deprecated) Generate a device specific optimized TensorRT engine using
tao-converter.
Machine-specific optimizations are done as part of the engine creation process, so a distinct engine should be generated for each environment and hardware configuration. If the TensorRT or CUDA libraries of the inference environment are updated (including minor version updates), or if a new model is generated, new engines need to be generated. Running an engine that was generated with a different version of TensorRT and CUDA is not supported and will cause unknown behavior that affects inference speed, accuracy, and stability, or it may fail to run altogether.
Option 1 is very straightforward. The .etlt file and calibration cache are directly
used by DeepStream. DeepStream will automatically generate the TensorRT engine file and then run
inference. TensorRT engine generation can take some time depending on size of the model
and type of hardware. Engine generation can be done ahead of time with Option 2.
With option 2, the tao-deploy is used to convert the .etlt file to TensorRT; this
file is then provided directly to DeepStream. The tao-converter follows the similar workflow
as tao-deploy. This option is deprecated for 4.0.0 and will not be available in the future release.
See the Exporting the Model section for more details on how to export a TAO model.
The tao-converter tool is provided with the TAO Toolkit
to facilitate the deployment of TAO trained models on TensorRT and/or Deepstream.
This section elaborates on how to generate a TensorRT engine using tao-converter.
For deployment platforms with an x86-based CPU and discrete GPUs, the tao-converter
is distributed within the TAO docker. Therefore, we suggest using the docker to generate
the engine. However, this requires that the user adhere to the same minor version of
TensorRT as distributed with the docker. The TAO docker includes TensorRT version 8.0.
Instructions for x86
For an x86 platform with discrete GPUs, the default TAO package includes the tao-converter
built for TensorRT 8.2.5.1 with CUDA 11.4 and CUDNN 8.2. However, for any other version of CUDA and
TensorRT, please refer to the overview section for download. Once the
tao-converter is downloaded, follow the instructions below to generate a TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/x86_64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/x86_64-linux-gnu”
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Instructions for Jetson
For the Jetson platform, the tao-converter is available to download in the NVIDIA developer zone. You may choose
the version you wish to download as listed in the overview section.
Once the tao-converter is downloaded, please follow the instructions below to generate a
TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/aarch64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/aarch64-linux-gnu”
For Jetson devices, TensorRT comes pre-installed with Jetpack. If you are using older JetPack, upgrade to JetPack-5.0DP.
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Using the tao-converter
tao-converter [-h] -k <encryption_key>
-d <input_dimensions>
-o <comma separated output nodes>
[-c <path to calibration cache file>]
[-e <path to output engine>]
[-b <calibration batch size>]
[-m <maximum batch size of the TRT engine>]
[-t <engine datatype>]
[-w <maximum workspace size of the TRT Engine>]
[-i <input dimension ordering>]
[-p <optimization_profiles>]
[-s]
[-u <DLA_core>]
input_file
Required Arguments
input_file: The path to the.etltmodel exported usingexport.-k: The key used to encode the.tltmodel when training.-d: A comma-separated list of input dimensions that should match the dimensions used forexport. Unlikeexport, this cannot be inferred from calibration data.-o: A comma-separated list of output blob names that should match the output configuration used forexport. For DetectNet_v2, set this argument tooutput_cov/Sigmoid,output_bbox/BiasAdd.
Optional Arguments
-e: The path to save the engine to. The default path is./saved.engine.-t: The desired engine data type. This option generates a calibration cache if in INT8 mode. The default value isfp32. The options arefp32,fp16, andint8.-w: The maximum workspace size for the TensorRT engine. The default value is1073741824(1<<30).-i: The input dimension ordering. The default value isnchw. The options arenchw,nhwc, andnc. For detectnet_v2, you can omit this argument.-p: The optimization profiles for.etltmodels with dynamic shape. This argument takes a comma-separated list of optimization profile shapes in the format<input_name>,<min_shape>,<opt_shape>,<max_shape>, where each shape has the format<n>x<c>x<h>x<w>. This can be specified multiple times if there are multiple input tensors for the model. This argument is only useful for new models introduced since TLT 3.0.-s: A Boolean value specifying whether to apply TensorRT strict type constraints when building the TensorRT engine.-u: Specifies the DLA core index when building the TensorRT engine on Jetson devices.
INT8 Mode Arguments
-c: The path to the calibration cache file for INT8 mode. The default path is./cal.bin.-b: The batch size used during the export step for INT8 calibration cache generation (default:8).-m: The maximum batch size for the TensorRT engine. The default value is16. If you encounter out-of-memory issues, decrease the batch size accordingly.
Sample Output Log
The following is a sample log for exporting a DetectNet_v2 model:
tao-converter -d 3,544,960
-k nvidia_tlt
-o output_cov/Sigmoid,output_bbox/BiasAdd
/workspace/tao-experiments/detectnet_v2/resnet18_pruned.etlt
..
[INFO] Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[INFO] Detected 1 inputs and 2 output network tensors.
To use the default tao-converter available in the TAO Toolkit
package, append tao to the sample usage of the tao_converter as mentioned
here.
Once the model and/or TensorRT engine file has been generated, two extra files are required:
The Label file
The DS configuration file
The label file is a text file containing the names of the classes that the DetectNet_v2 model
is trained to detect. The order in which the classes are listed here must match the order
in which the model predicts the output. The export subtask in DetectNet_v2 generates this
file when run with the --gen_ds_config flag enabled.
The detection model is typically used as a primary inference engine. It can also be used as a
secondary inference engine. To run this model in the sample deepstream-app, you must modify
the existing config_infer_primary.txt file to point to this model.
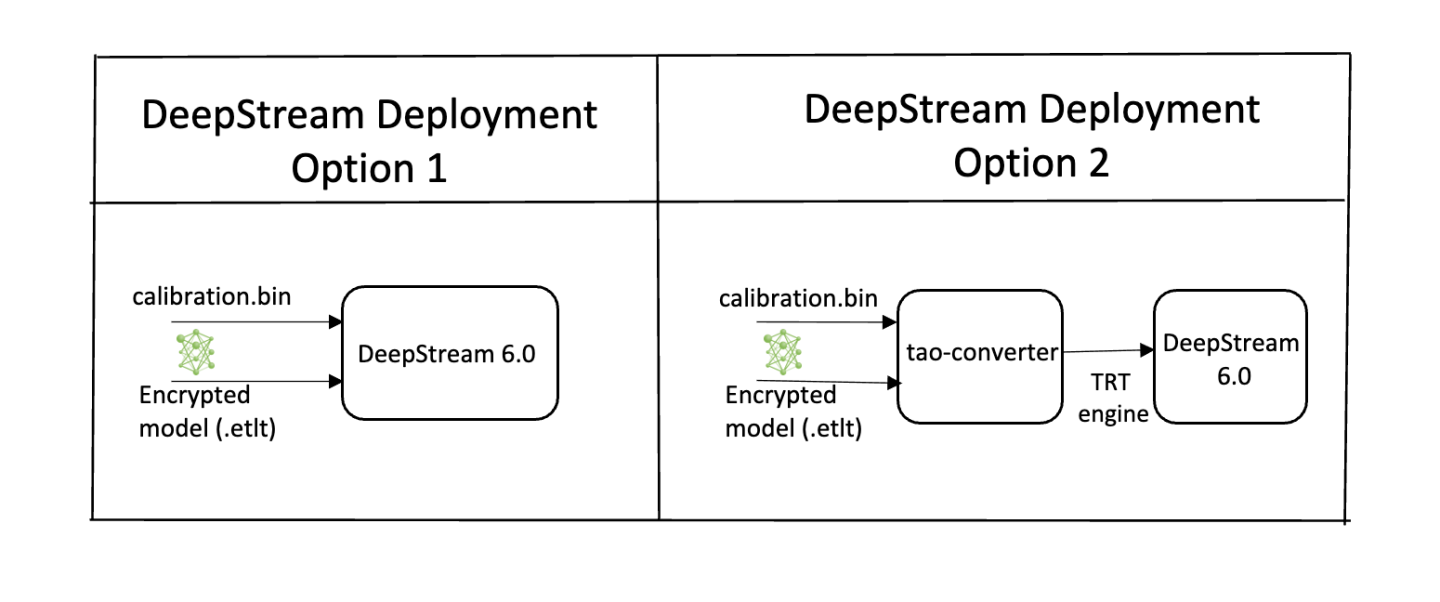
Option 1: Integrate the model (.etlt) directly in the DeepStream app.
For this option, you will need to add the following parameters in the configuration file.
The int8-calib-file is only required for INT8 precision.
tlt-encoded-model=<TLT exported .etlt>
tlt-model-key=<Model export key>
int8-calib-file=<Calibration cache file>
The tlt-encoded-model parameter points to the exported model (.etlt) from TAO Toolkit.
The tlt-model-key is the encryption key used during model export.
Option 2: Integrate the TensorRT engine file with the DeepStream app.
Generate the TensorRT engine using
tao-converter. Detailed instructions are provided in the Generating an engine using tao-converter section above.Modify the following parameters in the configuration file to use this engine with DeepStream.
model-engine-file=<PATH to generated TensorRT engine>
All other parameters are common between the two approaches. Update the label-file-path parameter
in the configuration file with the path to the labels.txt that was generated at
export.
labelfile-path=<Classification labels>
For all options, see the configuration file below. To learn more about all the parameters, refer to the DeepStream Development Guide under the GsT-nvinfer section.
[property]
gpu-id=0
# preprocessing parameters.
net-scale-factor=0.0039215697906911373
model-color-format=0
# model paths.
int8-calib-file=<Path to optional INT8 calibration cache>
labelfile-path=<Path to detectNet_v2_labels.txt>
tlt-encoded-model=<Path to DetectNet_v2 TLT model>
tlt-model-key=<Key to decrypt the model>
infer-dims=c;h;w # where c = number of channels, h = height of the model input, w = width of model input
uff-input-order=0 # 0 implies that the input blob is in chw order
uff-input-blob-name=input_1
batch-size=4
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=0
num-detected-classes=3
interval=0
gie-unique-id=1
is-classifier=0
output-blob-names=output_cov/Sigmoid;output_bbox/BiasAdd
#enable_dbscan=0
[class-attrs-all]
threshold=0.2
group-threshold=1
## Set eps=0.7 and minBoxes for enable-dbscan=1
eps=0.2
#minBoxes=3
roi-top-offset=0
roi-bottom-offset=0
detected-min-w=0
detected-min-h=0
detected-max-w=0
detected-max-h=0