Deploying to DeepStream for Multitask Classification
The deep learning and computer vision models that you’ve trained can be deployed on edge devices, such as a Jetson Xavier or Jetson Nano, a discrete GPU, or in the cloud with NVIDIA GPUs. TAO Toolkit has been designed to integrate with DeepStream SDK, so models trained with TAO Toolkit will work out of the box with DeepStream SDK.
DeepStream SDK is a streaming analytic toolkit to accelerate building AI-based video analytic applications. This section will describe how to deploy your trained model to DeepStream SDK.
To deploy a model trained by TAO Toolkit to DeepStream we have two options:
Option 1: Integrate the
.etltmodel directly in the DeepStream app. The model file is generated by export.Option 2: Generate a device specific optimized TensorRT engine using
tao-deploy. The generated TensorRT engine file can also be ingested by DeepStream.Option 3: (Deprecated) Generate a device specific optimized TensorRT engine using
tao-converter.
Machine-specific optimizations are done as part of the engine creation process, so a distinct engine should be generated for each environment and hardware configuration. If the TensorRT or CUDA libraries of the inference environment are updated (including minor version updates), or if a new model is generated, new engines need to be generated. Running an engine that was generated with a different version of TensorRT and CUDA is not supported and will cause unknown behavior that affects inference speed, accuracy, and stability, or it may fail to run altogether.
Option 1 is very straightforward. The .etlt file and calibration cache are directly
used by DeepStream. DeepStream will automatically generate the TensorRT engine file and then run
inference. TensorRT engine generation can take some time depending on size of the model
and type of hardware. Engine generation can be done ahead of time with Option 2.
With option 2, the tao-deploy is used to convert the .etlt file to TensorRT; this
file is then provided directly to DeepStream. The tao-converter follows the similar workflow
as tao-deploy. This option is deprecated for 4.0.0 and will not be available in the future release.
See the Exporting the Model section for more details on how to export a TAO model.
The tao-converter tool is provided with the TAO Toolkit
to facilitate the deployment of TAO trained models on TensorRT and/or Deepstream.
This section elaborates on how to generate a TensorRT engine using tao-converter.
For deployment platforms with an x86-based CPU and discrete GPUs, the tao-converter
is distributed within the TAO docker. Therefore, we suggest using the docker to generate
the engine. However, this requires that the user adhere to the same minor version of
TensorRT as distributed with the docker. The TAO docker includes TensorRT version 8.0.
Instructions for x86
For an x86 platform with discrete GPUs, the default TAO package includes the tao-converter
built for TensorRT 8.2.5.1 with CUDA 11.4 and CUDNN 8.2. However, for any other version of CUDA and
TensorRT, please refer to the overview section for download. Once the
tao-converter is downloaded, follow the instructions below to generate a TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/x86_64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/x86_64-linux-gnu”
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Instructions for Jetson
For the Jetson platform, the tao-converter is available to download in the NVIDIA developer zone. You may choose
the version you wish to download as listed in the overview section.
Once the tao-converter is downloaded, please follow the instructions below to generate a
TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/aarch64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/aarch64-linux-gnu”
For Jetson devices, TensorRT comes pre-installed with Jetpack. If you are using older JetPack, upgrade to JetPack-5.0DP.
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Using the tao-converter
tao converter -k <encryption_key>
-d <input_dimensions>
-o <comma separated output nodes>
[-c <path to calibration cache file>]
[-e <path to output engine>]
[-b <calibration batch size>]
[-m <maximum batch size of the TRT engine>]
[-t <engine datatype>]
[-w <maximum workspace size of the TRT Engine>]
[-i <input dimension ordering>]
[-p <optimization_profiles>]
[-s]
[-u <DLA_core>]
[-h]
input_file
Required Arguments
input_file: The path to the.etltmodel exported usingexport.-k: The key used to encode the.tltmodel when traning.-d: A comma-separated list of input dimensions that should match the dimensions used fortao multitask_classification export. Unliketao multitask_classification export, this cannot be inferred from the calibration data. This parameter is not required for new models introduced in TAO Toolkit v3.0 (e.g. LPRNet, UNet, GazeNet).-o: A comma-separated list of output blob names that should match the printout when usingtao multitask_classification export. The number of outputs is equal to the number of tasks.
Optional Arguments
-e: The path to save the engine to. The default value is./saved.engine.-t: The desired engine data type. This argument generates a calibration cache if in INT8 mode. The default value isfp32. The options are {fp32,fp16,int8}.-w: Maximum workspace size for the TensorRT engine. The default value is1073741824(1<<30).-i: The input dimension ordering; all other TAO commands use NCHW. The default value isnchw. The options are {nchw,nhwc,nc}. For classification, you can omit this argument since the default value isnchw.-p: Optimization profiles for.etltmodels with dynamic shape. The argument format is a comma-separated list of optimization profile shapes in the format<input_name>,<min_shape>,<opt_shape>,<max_shape>, where each shape has the format<n>x<c>x<h>x<w>. This argument can be specified multiple times if there are multiple input tensors for the model. This is only useful for new models introduced in TAO v3.0. This parameter is not required for models that existed in TAO v2.0.-s: A Boolean to apply TensorRT strict type constraints when building the TensorRT engine.-u: Specifies the DLA core index when building the TensorRT engine on Jetson devices.
INT8 Mode Arguments
-c: The path to the calibration cache file, which is only used in INT8 mode. The default value is./cal.bin.-b: The batch size used during the export step for INT8 calibration cache generation. The default value is8.-m: The maximum batch size for the TensorRT engine. The default value is16. If you encounter out-of-memory issues, decrease the batch size accordingly.
There are two options to integrate TAO models with DeepStream:
Option 1: Integrate the model (
.etlt) with the encrypted key directly in the DeepStream app. The model file is generated bytao multitask_classification export.Option 2: Generate a device-specific optimized TensorRT engine using tao-converter. The TensorRT engine file can also be ingested by DeepStream.
To integrate the models with DeepStream, you need the following:
Download and install DeepStream SDK. The installation instructions for DeepStream are provided in the DeepStream Development Guide.
An exported
.etltmodel file and optional calibration cache for INT8 precision.A
labels.txtfile containing the labels for classes in the order in which the networks produces outputs.A sample
config_infer_*.txtfile to configure the nvinfer element in DeepStream. The nvinfer element handles everything related to TensorRT optimization and engine creation in DeepStream.
DeepStream SDK ships with an end-to-end reference application that is fully configurable. You
can configure input sources, the inference model, and output sinks. The app requires a primary
object-detection model, followed by an optional secondary classification model. The reference
application is installed as deepstream-app. The graphic below shows the architecture of the
reference application:
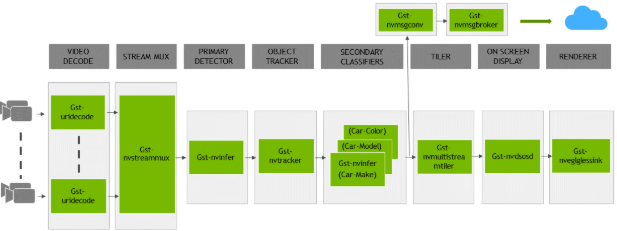
Typically, two or more configuration files are used with this app. In the install
directory, the config files are located in samples/configs/deepstream-app or
sample/configs/tlt_pretrained_models. The main config file configures all the high-level
parameters in the pipeline above. This will set the input source and resolution, number of
inferences, tracker, and output sinks. The other supporting config files are for each individual
inference engine. The inference-specific configuration files are used to specify the models,
inference resolution, batch size, number of classes, and other customizations. The main
configuration file will call all the supporting configuration files.
Here are some configuration files in samples/configs/deepstream-app for reference:
source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt: The main configuration fileconfig_infer_primary.txt: The supporting configuration file for the primary detector in the pipeline aboveconfig_infer_secondary_*.txt: The supporting configuration file for the secondary classifier in the pipeline above
The deepstream-app will only work with the main config file. This file will most likely
remain the same for all models and can be used directly from the DeepStream SDK with little to no
change. You will only need to modify or create config_infer_primary.txt and
config_infer_secondary_*.txt.
Integrating a Multitask Image Classification Model
See Exporting The Model for more details on how to export a TAO model. After the model has been generated, you can use the DeepStream sample app provided in GitHub repository to integrate the exported model. The GitHub repository also provides a README file for adjustments needed to integrate a custom model you trained on your own dataset.