Image Classification (TF2)
See the Data Annotation Format page for more information about the data format for image classification.
Below is a sample for the classification spec file. It has 8 major components:
data, model, train, evaluate, inference,
augment, prune and export config as well as mandatory parameters for the encryption key (key)
and results directory (results_dir).
results_dir: '/workspace/results_dir'
key: 'nvidia_tlt'
data:
train_dataset_path: "/workspace/tao-experiments/data/split/train"
val_dataset_path: "/workspace/tao-experiments/data/split/val"
preprocess_mode: 'torch'
augment:
enable_color_augmentation: True
enable_center_crop: True
train:
qat: False
checkpoint_interval: 1
pretrained_model_path: 'PRUNEDMODEL'
batch_size_per_gpu: 64
num_epochs: 80
optim_config:
optimizer: 'sgd'
lr_config:
scheduler: 'cosine'
learning_rate: 0.05
soft_start: 0.05
reg_config:
type: 'L2'
scope: ['conv2d', 'dense']
weight_decay: 0.00005
model:
arch: 'efficientnet-b0'
input_image_size: [3,256,256]
input_image_depth: 8
evaluate:
dataset_path: '/workspace/tao-experiments/data/split/test'
model_path: 'EVALMODEL'
top_k: 3
batch_size: 256
n_workers: 8
inference:
model_path: 'EVALMODEL'
image_dir: '/workspace/tao-experiments/data/split/test/aeroplane'
classmap: 'RESULTSDIR/classmap.json'
export:
model_path: 'EVALMODEL'
output_path: 'EXPORTDIR/efficientnet-b0.etlt'
data_type: 'fp32'
The format of the spec file is YAML. The top level structure of the spec file is summarized in the table below:
Field |
Description |
data |
Configuration related to data sources and dataloader |
model |
Configuration related to model construction |
augment |
Configuration related to data augmentation during training |
train |
Configuration related to the training process |
evaluate |
Configuration related to the standalone evaluation process |
prune |
Configuration for pruning a trained model |
inference |
Configuration for running model inference |
export |
Configuration for exporting a trained model |
key |
Global encryption key |
results_dir |
Directory where experiment results and status logging are saved |
Model Config
The table below describes the parameters in the model config.
Parameter |
Datatype |
Typical value |
Description |
Supported Values |
|
string |
|
This defines the architecture of the backbone feature extractor to be used to train. |
efficientnet-b0 to efficientnet-b5 |
|
Boolean |
|
Choose between using strided convolutions or MaxPooling while downsampling. When True, MaxPooling is used to down sample, however for the object detection network, NVIDIA recommends setting this to False and using strided convolutions. |
True or False |
|
Boolean |
|
Boolean variable to use batch normalization layers or not. |
True or False |
|
float (repeated) |
– |
This parameter defines which blocks may be frozen from the instantiated feature extractor template, and is different for different feature extractor templates. |
|
|
Boolean |
|
You can choose to freeze the Batch Normalization layers in the model during training. |
True or False |
|
string |
|
The dimension of the input layer of the model. Images in the dataset will be resized to this shape by the dataloader when fed to the model for training. |
C,X,Y, where C=1 or C=3 and X,Y >=16 and X,Y are integers. |
|
enum |
|
The interpolation method for resizing the input images. |
BILINEAR, BICUBIC |
|
Boolean |
|
Regular TAO models: whether or not to use the header layers as in the original implementation on ImageNet. Set this to True to reproduce the accuracy on ImageNet as in the literature. If set to False, a Dense layer will be used for header, which can be different from the literature. BYOM models: whether or not to use the header layers as in the original ONNX model. Set this to True to reproduce the accuracy on the original dataset. If set to False, Dense layer will be used for header, which can be different from the original implementation. |
True or False |
|
float |
|
Dropout rate for Dropout layers in the model. This is only valid for VGG and SqueezeNet. |
Float in the interval [0, 1) |
|
string |
– |
UNIX format path to the BYOM model in |
UNIX format path. |
Dataset Parameters
The table below describes the parameters in the data config.
+———————————–+——————————-+———————+——————————————————————————————————————————————+—————————————————————————————-+
| Parameter | Datatype | Default | Description | Supported Values |
+———————————–+——————————-+———————+——————————————————————————————————————————————+—————————————————————————————-+
| val_dataset_path | string | | UNIX format path to the root directory of the validation dataset. | UNIX format path. |
+———————————–+——————————-+———————+——————————————————————————————————————————————+—————————————————————————————-+
| train_dataset_path | string | | UNIX format path to the root directory of the training dataset. | UNIX format path. |
+———————————–+——————————-+———————+——————————————————————————————————————————————+—————————————————————————————-+
| image_mean | list | | A list of image mean values in BGR order. It’s only applicable when preprocess_mode is caffe. | – |
+———————————–+——————————-+———————+——————————————————————————————————————————————+—————————————————————————————-+
| preprocess_mode | string | 'torch' | Mode for input image preprocessing. Defaults to ‘caffe’. | ‘caffe’, ‘torch’, ‘tf’ |
+———————————–+——————————-+———————+——————————————————————————————————————————————+—————————————————————————————-+
Augmentation Parameters
The table below describes the parameters in the augment config.
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
Boolean |
|
A flag to enable random crop during training. |
True or False |
|
Boolean |
|
A flag to enable center crop during validation. |
True or False |
|
Boolean |
|
A flag to enable color augmentation during training. |
True or False |
|
Boolean |
|
A flag to disable horizontal flip. |
True or False |
|
float |
|
A factor used for mixup augmentation. |
in the interval (0, 1) |
Evaluation Config
The table below defines the configurable parameters for evaluating a classification model.
Parameter |
Datatype |
Typical value |
Description |
Supported Values |
|
string |
UNIX format path to the root directory of the evaluation dataset. |
UNIX format path. |
|
|
string |
UNIX format path to the root directory of the model file you would like to evaluate. |
UNIX format path. |
|
|
int |
|
The number elements to look at when calculating the top-K classification categorical accuracy metric. |
1, 3, 5 |
|
int |
|
Number of images per batch when evaluating the model. |
>1 (bound by the number of images that can be fit in the GPU memory) |
|
int |
|
Number of workers fetching batches of images in the evaluation dataloader. |
>1 |
Training Config
This section defines the configurable parameters for the classification model trainer.
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
string |
UNIX format path to the model file containing the pretrained weights to initialize the model from. |
UNIX format path. |
|
|
int |
|
This parameter defines the number of images per batch per gpu. |
>1 |
|
int |
|
This parameter defines the total number of epochs to run the experiment. |
>1 |
|
int |
|
This parameter defines the frequency to save the checkpoints. |
>1 |
|
int |
|
Number of workers fetching batches of images in the training/validation dataloader. |
>1 |
|
int |
– |
Random seed for training. |
– |
|
float |
|
A factor used for label smoothing. |
in the interval (0, 1) |
|
learning rate config |
– |
The parameters for learning rate scheduler. |
– |
|
regularizer config |
– |
The parameters for regularizers. |
– |
|
optimizer config |
– |
This parameter defines which optimizer to use for training. Can be chosen from |
– |
|
BatchNorm config |
– |
This parameter for batch normalization layers |
– |
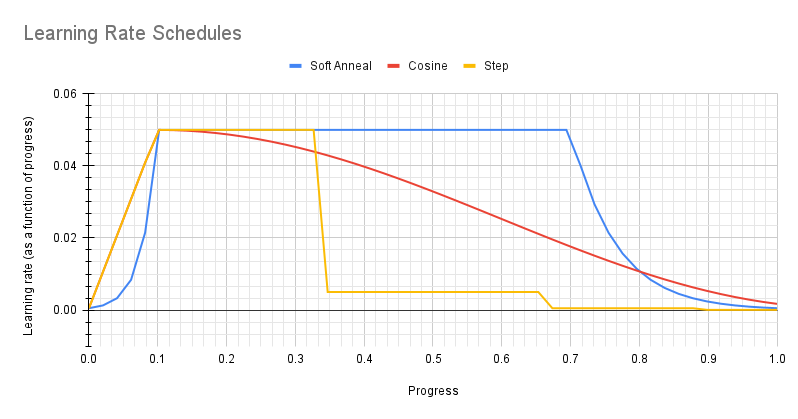
Learning Rate Scheduler
The parameter lr_config defines the parameters for learning rate scheduler
The learning rate scheduler can be either step, soft_anneal or cosine.
Step
The parameter step defines the step learning rate scheduler.
Parameter |
Datatype |
Typical value |
Description |
Supported Values |
|
float |
– |
The base(maximum) learning rate value. |
Positive, usually in the interval (0, 1). |
|
int |
– |
The progress (percentage of the entire training duration) after which the learning rate will be decreased. |
Less than 100. |
|
float |
– |
The multiplicative factor used to decrease the learning rate. |
In the interval (0, 1). |
The learning rate is automatically scaled with the number of GPUs used during training, or the effective learning rate is learning_rate * n_gpu.
Soft Annealing
The parameter soft_anneal defines the soft annealing learning rate scheduler.
Parameter |
Datatype |
Typical value |
Description |
Supported Values |
|
float |
– |
The base (maximum) learning rate value. |
Positive, usually in the interval (0, 1). |
|
float |
– |
The progress at which learning rate achieves the base learning rate. |
In the interval (0, 1). |
|
float |
– |
The divider by which the learning rate will be scaled down. |
Greater than 1.0. |
|
repeated float |
– |
Points of progress at which the learning rate will be decreased. |
List of floats. Each will be in the interval (0, 1). |
Cosine
The parameter cosine defines the cosine learning rate scheduler.
Parameter |
Datatype |
Typical value |
Description |
Supported Values |
|
float |
– |
The base (maximum) learning rate. |
Usually less than 1.0 |
|
float |
– |
The ratio of minimum learning rate to the base learning rate. |
Less than 1.0 |
|
float |
– |
The progress at which learning rate achieves the base learning rate. |
In the interval (0, 1). |
Optimizer Config
Three types of optimizers are supported: Adam, SGD and RMSProp. Only one type should be specified in
the spec file using optimizer
The Adam optimizer parameters are summarized in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The learning rate. This parameter is overridden by the learning rate scheduler and hence not useful. |
float |
|
|
The momentum for the means of the model parameters |
float |
|
|
The momentum for the variances of the model parameters |
float |
|
|
Th decay factor for the learning rate. This parameter is not useful. |
float |
|
|
A small constant for numerical stability |
float |
|
The SGD optimizer parameters are summarized in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The learning rate. This parameter is overridden by the learning rate scheduler and hence not useful. |
float |
|
|
The momentum of SGD |
float |
|
|
The decay factor of the learning rate. This parameter is not useful because it is overridden by the learning rate scheduler. |
float |
|
|
A flag to enable Nesterov momentum for SGD |
Boolean |
|
The RMSProp optimizer parameters are summarized in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The learning rate. This parameter is overridden by the learning rate scheduler and hence not useful. |
float |
|
BatchNorm Config
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
Momentum for the moving average |
float |
|
|
Small float added to variance to avoid dividing by zero |
float |
|
Pruning Config
The prune configuration defines the pruning process for a trained model. A detailed description is summarized in the table
below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
normalizer |
Normalization method. Specify |
String |
max |
equalization_criterion |
The criteria to equalize the stats of inputs to an element-wise op
layer or depth-wise conv layer. Options are |
String |
union |
granularity |
The number of filters to remove at a time |
Integer |
8 |
threshold |
Pruning threshold |
Float |
– |
min_num_filters |
The minimum number of filters to keep per layer. Default: 16 |
Integer |
16 |
excluded_layers |
A list of layers to be excluded from pruning |
List |
– |
Export Config
The export configuration contains the parameters of exporting a .tlt model to .etlt model, which can be used for deployment.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
model_path |
The path to the |
String |
– |
output_path |
The path to save the exported |
String |
False |
Use the tao classification_tf2 train command to tune a pre-trained model:
tao classification_tf2 train [-h] -e <spec file>
[--gpus <num GPUs>]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments
-e, --experiment_spec_file: Path to the experiment spec file.
Optional Arguments
--gpus: Number of GPUs to use and processes to launch for training. The default value is 1.--gpu_index: The GPU indices used to run the training. We can specify the GPU indices used to run training when the machine has multiple GPUs installed.--log_file: Path to the log file. Defaults to stdout.-h, --help: Print the help message.
See the Specification File for Classification section for more details.
Input Requirement
Input size: 3 * H * W (W, H >= 32)
Input format: JPG, JPEG, PNG
Classification input images do not need to be manually resized. The input dataloader
automatically resizes images to input size.
Sample Usage
Here’s an example of using the tao classification_tf2 train command:
tao classification_tf2 train -e /workspace/spec.yaml --gpus 2
After the model has been trained, using the experiment config file, and by following the steps to train a model, the next step is to evaluate this model on a test set to measure the accuracy of the model.
The classification app computes evaluation loss, Top-k accuracy, precision, and recall as metrics.
Evaluate a model using the tao classification_tf2 evaluate command:
tao classification_tf2 evaluate [-h] -e <experiment_spec_file>
[--gpu_index <gpu_index>]
[--log_file <log_file>]
Required Arguments
-e, --experiment_spec_file: Path to the experiment spec file.
Optional Arguments
-h, --help: Show this help message and exit.--gpu_index: The GPU indices used to run the training. We can specify the GPU indices used to run training when the machine has multiple GPUs installed.--log_file: Path to the log file. Defaults to stdout.
If you followed the example in training a classification model, run the evaluation:
tao classification_tf2 evaluate -e classification_spec.yaml
TAO evaluates for classification and produces the following metrics:
Loss
Top-K accuracy
Precision (P): TP / (TP + FP)
Recall (R): TP / (TP + FN)
Confusion Matrix
The tao classification_tf2 inference command runs the inference on a specified set of input images.
For classification, tao classification_tf2 inference provides class label output over
the command-line for a single image or a csv file containing the image path and the corresponding labels for multiple
images. TensorRT Python inference can also be enabled.
Execute tao classification_tf2 inference on a classification model trained on TAO Toolkit.
tao classification_tf2 inference [-h] -e <experiment_spec_file>
[--gpu_index <gpu_index>]
[--log_file <log_file>]
Here are the arguments of the tao classification_tf2 inference tool:
Required arguments
-e, --experiment_spec_file: Path to the experiment spec file.
Optional arguments
-h, --help: Show this help message and exit.--gpu_index: The GPU indices used to run the training. We can specify the GPU indices used to run training when the machine has multiple GPUs installed.--log_file: Path to the log file. Defaults to stdout.
Pruning removes parameters from the model to reduce the model size without compromising the
integrity of the model itself using the tao classification_tf2 prune command.
The tao classification_tf2 prune command includes these parameters:
tao classification_tf2 prune [-h] -e <experiment_spec_file>
Required Arguments
-e, --experiment_spec_file: Path to the experiment spec file.
Optional Arguments
-h, --help: Show this help message and exit.--gpu_index: The GPU indices used to run the training. We can specify the GPU indices used to run training when the machine has multiple GPUs installed.--log_file: Path to the log file. Defaults to stdout.
After pruning, the model needs to be retrained. See Re-training the Pruned Model for more details.
Using the Prune Command
Here’s an example of using the tao classification_tf2 prune command:
tao classification_tf2 prune -e /workspace/spec.yaml
After the model has been pruned, there might be a slight decrease in accuracy. This happens
because some previously useful weights may have been removed. In order to regain the accuracy,
NVIDIA recommends that you retrain this pruned model over the same dataset. To do this, use
the tao classification_tf2 train command as documented in Training the model, with
an updated spec file that points to the newly pruned model as the pretrained model file.
Users are advised to turn off the regularizer in the train config for classification to recover
the accuracy when retraining a pruned model. You may do this by setting the regularizer type
to NO_REG. All the other parameters may be retained in the spec file from the previous training.
Exporting the model decouples the training process from inference and allows conversion to
TensorRT engines outside the TAO environment. TensorRT engines are specific to each hardware
configuration and should be generated for each unique inference environment.
The exported model may be used universally across training and deployment hardware.
The exported model format is referred to as .etlt. Like .tlt, the .etlt model
format is also a encrypted model format with the same key of the .tlt model that it is
exported from. This key is required when deploying this model.
Here’s an example of the tao classification_tf2 export command:
tao classification_tf2 export [-h] [-e <experiment_spec_file>] [--gpu_index <gpu_index>]
Required Arguments
-e, --experiment_spec: Path to the spec file.
Optional Arguments
--gpu_index: The index of (discrete) GPUs used for exporting the model. We can specify the GPU index to run export if the machine has multiple GPUs installed. Note that export can only run on a single GPU.
Sample Usage
Here’s a sample command.
tao classification_tf2 export -e /workspace/spec.yaml
For TensorRT engine generation, validation, and int8 calibration, refer to the TAO Deploy documentation.
Refer to the Integrating a Classification (TF1/TF2) Model page for more information about deploying a classification model with DeepStream.