Deploying to DeepStream for Classification TF1/TF2
The deep learning and computer vision models that you’ve trained can be deployed on edge devices, such as a Jetson Xavier or Jetson Nano, a discrete GPU, or in the cloud with NVIDIA GPUs. TAO Toolkit has been designed to integrate with DeepStream SDK, so models trained with TAO Toolkit will work out of the box with DeepStream SDK.
DeepStream SDK is a streaming analytic toolkit to accelerate building AI-based video analytic applications. This section will describe how to deploy your trained model to DeepStream SDK.
To deploy a model trained by TAO Toolkit to DeepStream we have two options:
Option 1: Integrate the
.etltmodel directly in the DeepStream app. The model file is generated by export.Option 2: Generate a device-specific optimized TensorRT engine using TAO Deploy. The generated TensorRT engine file can also be ingested by DeepStream.
Option 3 (Deprecated for x86 devices): Generate a device-specific optimized TensorRT engine using TAO Converter.
Machine-specific optimizations are done as part of the engine creation process, so a distinct engine should be generated for each environment and hardware configuration. If the TensorRT or CUDA libraries of the inference environment are updated (including minor version updates), or if a new model is generated, new engines need to be generated. Running an engine that was generated with a different version of TensorRT and CUDA is not supported and will cause unknown behavior that affects inference speed, accuracy, and stability, or it may fail to run altogether.
Option 1 is very straightforward. The .etlt file and calibration cache are directly
used by DeepStream. DeepStream will automatically generate the TensorRT engine file and then run
inference. TensorRT engine generation can take some time depending on size of the model
and type of hardware.
Engine generation can be done ahead of time with Option 2: TAO Deploy is used to convert the .etlt
file to TensorRT; this file is then provided directly to DeepStream. The TAO Deploy workflow is similar to
TAO Converter, which is deprecated for x86 devices in TAO version 4.0.0 but is still required for
deployment to Jetson devices.
See the Exporting the Model section for more details on how to export a TAO model.
In order to integrate the models with DeepStream, you need the following:
The DeepStream SDK. Installation instructions for DeepStream are provided in the DeepStream Development Guide.
An exported
.etltmodel file and optional calibration cache for INT8 precisionA
labels.txtfile containing the labels for classes in the order in which the networks produce outputs.A sample
config_infer_*.txtfile to configure the nvinfer element in DeepStream. The nvinfer element handles everything related to TensorRT optimization and engine creation in DeepStream.
The DeepStream SDK ships with an end-to-end reference application that is fully configurable. You
can configure the input sources, inference model, and output sinks. The app requires a primary object
detection model, followed by an optional secondary classification model. The reference
application is installed as deepstream-app. The graphic below shows the architecture of the
reference application.
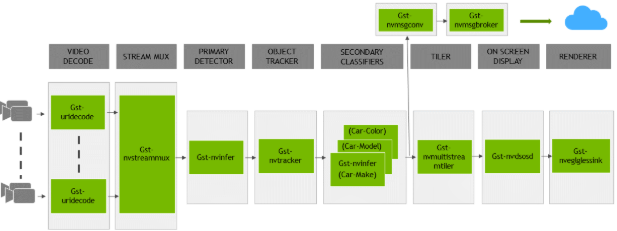
There are typically two or more configuration files that are used with this app. In the install
directory, the config files are located in samples/configs/deepstream-app or
sample/configs/tlt_pretrained_models. The main config file configures all the high level
parameters in the pipeline above, setting the input source and resolution, number of
inferences, tracker and output sinks. The supporting config files are for each individual
inference engine. The inference-specific config files are used to specify models, inference
resolution, batch size, number of classes and other customization. The main config file will call
all the supporting config files. Here are some config files in
samples/configs/deepstream-app for reference:
source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt: The main config fileconfig_infer_primary.txt: The supporting config file for the primary detector in the pipeline aboveconfig_infer_secondary_*.txt: The supporting config file for the secondary classifier in the pipeline above
The deepstream-app will only work with the main config file. This file will most likely
remain the same for all models and can be used directly from the DeepStream SDK with little to no
change. You will only need to modify or create config_infer_primary.txt and
config_infer_secondary_*.txt.
Integrating a Classification Model
See Exporting The Model for more details on how to export a TAO model. After the model has been generated, two extra files are required:
A label file
A DeepStream configuration file
Label File
The label file is a text file, containing the names of the classes that the TAO model is trained
to classify against. The order in which the classes are listed must match the order in which
the model predicts the output. This order may be deduced from the classmap.json file that is
generated by TAO. This file is a simple dictionary containing the ‘class_name’ to ‘index map’.
For example, in the sample classification sample notebook file included with the TAO Toolkit package,
the classmap.json file generated for Pascal Visual Object Classes (VOC) would look like this:
{"sheep": 16,"horse": 12,"bicycle": 1, "aeroplane": 0, "cow": 9,
"sofa": 17, "bus": 5, "dog": 11, "cat": 7, "person": 14, "train": 18,
"diningtable": 10, "bottle": 4, "car": 6, "pottedplant": 15,
"tvmonitor": 19, "chair": 8, "bird": 2, "boat": 3, "motorbike": 13}
The 0th index corresponds to aeroplane, the 1st index corresponds to bicycle,
up to 19, which corresponds to tvmonitor. Here is a sample
classification_labels.txt file, arranged in order of index:
aeroplane;bicycle;bird;boat;bottle;bus;....;tvmonitor
DeepStream Configuration File
A typical use case for video analytic is first to do an object detection and then crop the
detected object and send it further for classification. This is supported by deepstream-app
and the app architecture can be seen above. For example, to classify models of cars on the
road, first you will need to detect all the cars in a frame. Once you do detection, you perform
classification on the cropped image of the car. In the sample DeepStream app, the classifier
is configured as a secondary inference engine after the primary detection. If configured
appropriately, deepstream-app will automatically crop the detected image and send the frame
to the secondary classifier. The config_infer_secondary_*.txt is used to configure the
classification model.
Option 1: Integrate the model (.etlt) directly in the DeepStream app. For this option,
you will need to add the following parameters in the configuration file. The
int8-calib-file is only required for INT8 precision.
tlt-encoded-model=<TAO Toolkit exported .etlt>
tlt-model-key=<Model export key>
int8-calib-file=<Calibration cache file>
Option 2: Integrate the TensorRT engine file with the DeepStream app.
Generate the device-specific TensorRT engine using TAO Deploy.
After the engine file is generated, modify the following parameter to use this engine with DeepStream:
model-engine-file=<PATH to generated TensorRT engine>
<<<<<<< HEAD
All other parameters are common between the two approaches. The net-scale-factor, offsets, and
model-color-format parameters must be updated according to the preprocessing_mode in the training
spec file:
preprocessing_mode: "caffe":net-scale-factor=1.0 offsets=B;G;R model-color-format=1
Where
B;G;Rshoud be replaced by theimage_meanparameters. Ifimage_meanis not set, the default ImageNet mean (103.939;116.779;123.68) will be used.preprocessing_mode: "torch":net-scale-factor=0.017507 offsets=123.675;116.280;103.53 model-color-format=0
preprocessing_mode: "tf":net-scale-factor=0.0078 offsets=127.5;127.5;127.5 model-color-format=0
Add the label file generated above with the following:
labelfile-path=<Classification labels>
For all options, refer to the configuration file below. To learn more about all the parameters, refer to the DeepStream Development Guide.
[property]
gpu-id=0
# preprocessing parameters
net-scale-factor=1.0
offsets=103.939;116.779;123.68
model-color-format=1
batch-size=30
# Model specific paths. These need to be updated for every classification model.
int8-calib-file=<Path to optional INT8 calibration cache>
labelfile-path=<Path to classification_labels.txt>
tlt-encoded-model=<Path to Classification etlt model>
tlt-model-key=<Key to decrypt model>
infer-dims=c;h;w # where c = number of channels, h = height of the model input, w = width of model input
uff-input-blob-name=input_1
uff-input-order=0
output-blob-names=predictions/Softmax
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=0
# process-mode: 2 - inferences on crops from primary detector, 1 - inferences on whole frame
process-mode=2
interval=0
network-type=1 # defines that the model is a classifier.
gie-unique-id=1
classifier-threshold=0.2