PeopleSegNet
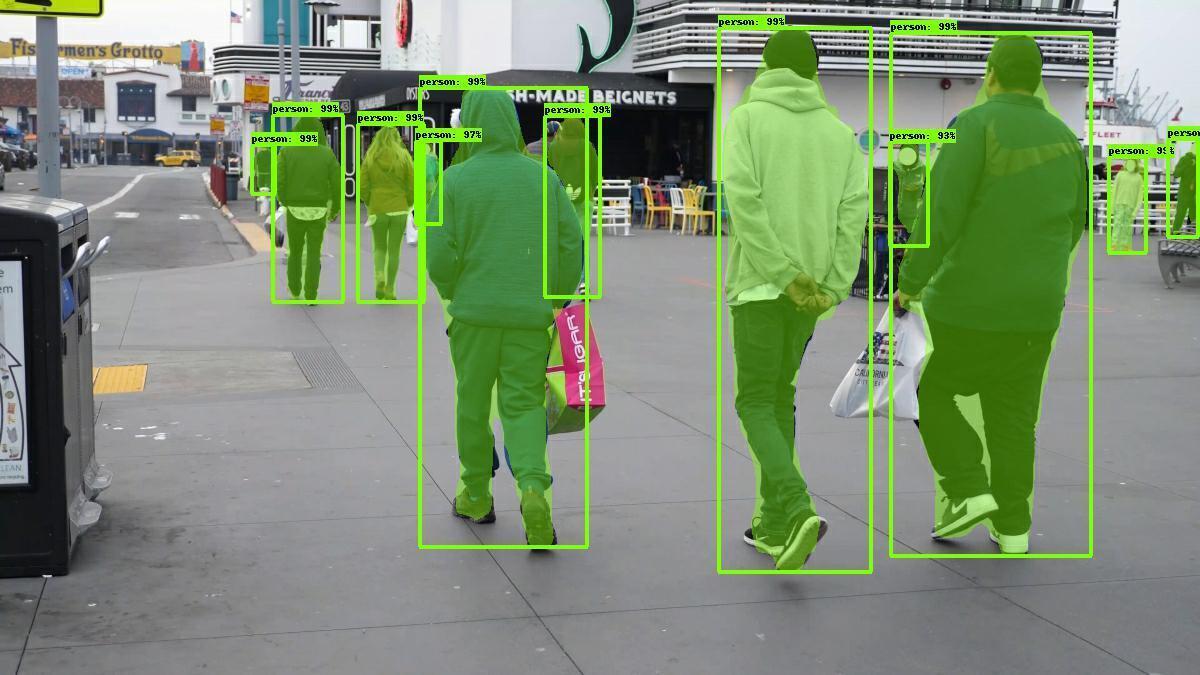
The model described in this card detects one or more “person” objects within an image and returns a box around each object, as well as a segmentation mask for each object.
This model is based on MaskRCNN with ResNet50 as its feature extractor. MaskRCNN is a widely adopted two-stage architecture, which uses Region Proposal Network (RPN) to generate object proposals and various prediction heads to predict object categories, refine bounding boxes and generate instance masks.
The training algorithm optimizes the network to minimize the mask, localization and confidence loss for the objects.
Primary use case intended for the model is detecting and segmenting people in a color (RGB) image. The model can be used to detect and segment people from photos and videos by using appropriate video or image decoding and pre-processing.
The datasheet for the model is captured in it’s model card hosted at NGC.