PoseClassificationNet
PoseClassificationNet takes a sequence of skeletons (body poses) as network input and predicts the actions of one or more persons in those frames. The model supported in the current version is based on the spatial-temporal graph convolutional network (ST-GCN), which is the most commonly used baseline for skeleton-based action recognition due to its simplicity and computational efficiency. Unlike pixel-based action recognition, ST-GCN is able to exploit the local pattern and correlation from a spatial-temporal graph of human skeletons. This model can be used to train graph convolutional networks (GCNs) for other purposes through transfer learning. Newer architectures with state-of-the-art performance will be released in the future. TAO Toolkit provides the network backbone for 3D poses.
PoseClassificationNet requires a sequence of skeletons (body poses) for input. The coordinates need to be normalized. For example, 3D joints are produced relative to the root keypoint (i.e. pelvis) and normalized by the focal length (1200.0 for 1080P). The entrypoint for dataset conversion generates an array of spatio-temporal sequences based on the output JSON metadata from the deepstream-bodypose-3d app.
The input data for training or inference are formatted as a NumPy array in five dimensions
(N, C, T, V, M):
N: The number of sequencesC: The number of input channels, which is set to 3 in the NGC modelT: The maximum sequence length in frames, which is 300 (10 seconds for 30 FPS) in the NGC modelV: The number of joint points, set to 34 for the NVIDIA formatM: The number of persons. The pre-trained model assumes a single object, but it can also support multiple people
The output of model inference is an array of N elements that gives the predicted action class
for each sequence.
The labels used for training or evaluation are stored as a pickle file that consists of a list of two
lists, including N elements each. The first list contains N strings of sample names.
The second list contains the labeled action class ID of each sequence. The following is an example:
[["xl6vmD0XBS0.json", "OkLnSMGCWSw.json", "IBopZFDKfYk.json", "HpoFylcrYT4.json", "mlAtn_zi0bY.json", ...], [235, 388, 326, 306, 105, ...]]
The graph to model skeletons is defined by two configuration parameters:
graph_layout(string): Must be one the following candidates:nvidiaconsists of 34 joints. For more information, please refer to AR SDK Programming Guide.openposeconsists of 18 joints. For more information, please refer to OpenPose.human3.6mconsists of 17 joints. For more information, please refer to Human3.6M.ntu-rgb+dconsists of 25 joints. For more information, please refer to NTU RGB+D.ntu_edgeconsists of 24 joints. For more information, please refer to NTU RGB+D.cococonsists of 17 joints. For more information, please refer to COCO.
graph_strategy(string): Must be one of the following candidates (for more information, refer to the “Partition Strategies” section in this paper):uniform: Uniform Labelingdistance: Distance Partitioningspatial: Spatial Configuration
The spec file for PoseClassificationNet includes model_config, train_config, and
dataset_config parameters. Here is an example spec for training a 3D-pose-based model on
the NVIDIA dataset. It contains 6 classes: “sitting_down”, “getting_up”, “sitting”, “standing”,
“walking”, “jumping”:
model_config:
model_type: ST-GCN
in_channels: 3
num_class: 6
dropout: 0.5
graph_layout: "nvidia"
graph_strategy: "spatial"
edge_importance_weighting: True
train_config:
optim:
lr: 0.1
momentum: 0.9
nesterov: True
weight_decay: 0.0001
lr_scheduler: "MultiStep"
lr_steps:
- 10
- 60
lr_decay: 0.1
epochs: 70
checkpoint_interval: 5
dataset_config:
train_data_path: "/path/to/train_data.npy"
train_label_path: "/path/to/train_label.pkl"
val_data_path: "/path/to/val_data.npy"
val_label_path: "/path/to/val_label.pkl"
label_map:
sitting_down: 0
getting_up: 1
sitting: 2
standing: 3
walking: 4
jumping: 5
batch_size: 16
workers: 5
Parameter |
Data Type |
Default |
Description |
|
dict config |
– |
The configuration for the model architecture |
|
dict config |
– |
The configuration for the training process |
|
dict config |
– |
The configuration for the dataset |
model_config
The model_config parameter provides options to change the PoseClassificationNet architecture.
model_config:
model_type: ST-GCN
in_channels: 3
num_class: 6
dropout: 0.5
graph_layout: "nvidia"
graph_strategy: "spatial"
edge_importance_weighting: True
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
string |
ST-GCN |
The type of model, which can only be ST-GCN for now. Newer architectures will be supported in the future. |
ST-GCN |
|
unsigned int |
3 |
The number of input channels (dimension of body poses) |
>0 |
|
unsigned int |
6 |
The number of action classes |
>0 |
|
float |
0.5 |
The probability to drop hidden units |
0.0 ~ 1.0 |
|
string |
nvidia |
The layout of the graph for modeling skeletons. It can be nvidia, openpose, human3.6m, ntu-rgb+d, ntu_edge, or coco. |
nvidia/openpose/human3.6m/ntu-rgb+d/ntu_edge/coco |
|
string |
spatial |
The strategy of the graph for modeling skeletons. It can be uniform, distance, or spatial. |
uniform/distance/spatial |
|
bool |
True |
Specifies whether to enable edge importance weighting |
True/False |
train_config
The train_config parameter defines the hyperparameters of the training process.
train_config:
optim:
lr: 0.1
momentum: 0.9
nesterov: True
weight_decay: 0.0001
lr_scheduler: "MultiStep"
lr_steps:
- 10
- 60
lr_decay: 0.1
epochs: 70
checkpoint_interval: 5
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
dict config |
The configuration for the SGD optimizer, including the learning rate, learning scheduler, weight decay, etc. |
||
|
unsigned int |
70 |
The total number of epochs to run the experiment |
>0 |
|
unsigned int |
5 |
The interval at which the checkpoints are saved |
>0 |
|
float |
0.0 |
The amount to clip the gradient by the L2 norm. A value of 0.0 specifies no clipping. |
>=0 |
optim
The optim parameter defines the config for the SGD optimizer in training, including the
learning rate, learning scheduler, and weight decay.
optim:
lr: 0.1
momentum: 0.9
nesterov: True
weight_decay: 0.0001
lr_scheduler: "MultiStep"
lr_steps:
- 10
- 60
lr_decay: 0.1
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
|
float |
0.1 |
The initial learning rate for the training |
>0.0 |
|
float |
0.9 |
The momentum for the SGD optimizer |
>0.0 |
|
bool |
True |
Specifies whether to enable Nesterov momentum. |
True/False |
|
float |
1e-4 |
The weight decay coefficient |
>0.0 |
|
|
string |
MultiStep |
The learning scheduler. Two schedulers are provided: |
MultiStep/AutoReduce |
|
string |
val_loss |
The monitor value for the |
val_loss/train_loss |
|
unsigned int |
1 |
The number of epochs with no improvement, after which learning rate will be reduced |
>0 |
|
float |
1e-4 |
The minimum learning rate in the training |
>0.0 |
|
int list |
[10, 60] |
The steps to decrease the learning rate for the |
int list |
|
float |
0.1 |
The decreasing factor for the learning rate scheduler |
>0.0 |
dataset_config
The dataset_config parameter defines the dataset source, training batch size, and augmentation.
dataset_config:
train_data_path: "/path/to/train/data.npy"
train_label_path: "/path/to/train_label.pkl"
val_data_path: "/path/to/val_data.npy"
val_label_path: "/path/to/val_label.pkl"
label_map:
sitting_down: 0
getting_up: 1
sitting: 2
standing: 3
walking: 4
jumping: 5
batch_size: 16
workers: 5
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
string |
The path to the train data in a NumPy array |
||
|
string |
The path to the train labels in a pickle file |
||
|
string |
The path to the validation data in a NumPy array |
||
|
string |
The path to the validation labels in a pickle file |
||
|
dict |
A dict that maps the class names to indices |
||
|
bool |
False |
Specifies whether to randomly choose a portion of the input sequence. |
True/False |
|
bool |
False |
Specifies whether to randomly move the input sequence. |
True/False |
|
unsigned int |
-1 |
The length of the output sequence. -1 means the same as original length. |
|
|
unsigned int |
64 |
The batch size for training and validation |
>0 |
|
unsigned int |
1 |
The number of parallel workers processing data |
>0 |
The input layout is NCTVM, where N is the batch size, C is the number of
input channels, T is the sequence length, V is the number of keypoints, and
M is the number of people.
Use the following command to run PoseClassificationNet training:
tao pose_classification train -e <experiment_spec_file>
-r <results_dir>
-k <key>
[gpu_ids=<gpu id list>]
[resume_training_checkpoint_path=<absolute path to \*.tlt checkpoint>]
Required Arguments
-e, --experiment_spec_file: The path to the experiment spec file.-r, --results_dir: The path to a folder where the experiment outputs should be written.-k, --key: The user-specific encoding key to save or load a.tltmodel.
Optional Arguments
gpu_ids: The GPU indices list for training. If you set more than one GPU ID, multi-GPU training will be triggered automatically.resume_training_checkpoint_path: The path to a checkpoint to continue training.
Here’s an example of using the PoseClassificationNet training command:
tao pose_classification train -e $DEFAULT_SPEC -r $RESULTS_DIR -k $YOUR_KEY
The evaluation metric of PoseClassificationNet is the accuracy of action recognition.
Use the following command to run PoseClassificationNet evaluation:
tao pose_classification evaluate -e <experiment_spec_file>
-k <key>
model=<model to be evaluated>
data=<path to test data>
label=<path to test labels>
[gpu_id=<gpu index>]
Required Arguments
-e, --experiment_spec_file: The experiment spec file to set up the evaluation experiment.-k, --key: The encoding key for the.tltmodel.model: The.tltmodel.data: The path to the test data.label: The path to the test labels.
Optional Argument
gpu_id: The GPU index used to run the evaluation. You can specify the GPU index used to run evaluation when the machine has multiple GPUs installed. Note that evaluation can only run on a single GPU.
Here’s an example of using the PoseClassificationNet evaluation command:
tao pose_classification evaluate -e $DEFAULT_SPEC -k $YOUR_KEY model=$TRAINED_TLT_MODEL data=$TEST_DATA label=$TEST_LABEL
Use the following command to run inference on PoseClassificationNet with the .tlt model.
tao pose_classification inference -e <experiment_spec>
-k <key>
model=<inference model>
data=<path to inference data>
output_file=<path to output file>
[gpu_id=<gpu index>]
The output will be a text file, where each line corresponds to the predicted action class for an input sequence.
Required Arguments
-e, --experiment_spec: The experiment spec file to set up inference-k, --key: The encoding key for the.tltmodelmodel: The.tltmodel to perform inference withdata: The path to the test dataoutput_file: The path to the output text file
Optional Argument
gpu_id: The GPU index used to run the inference. You can specify the GPU index used to run inference when the machine has multiple GPUs installed. Note that inference can only run on a single GPU.
Here’s an example of using the PoseClassificationNet inference command:
tao pose_classification inference -e $DEFAULT_SPEC -k $KEY model=$TRAINED_TLT_MODEL data=$TEST_DATA output_file=$OUTPUT_FILE
The expected output for the NVIDIA test data would be as follows:
sit
sit
sit_down
...
Use the following command to export PoseClassificationNet to .etlt format for deployment:
tao pose_classification export -k <key>
-e <experiment_spec>
model=<tlt checkpoint to be exported>
[gpu_id=<gpu index>]
[output_file=<path to exported file>]
Required Arguments
-e, --experiment_spec: The experiment spec file to set up export.-k, --key: The encoding key for the.tltmodel.model: The.tltmodel to be exported.
Optional Arguments
gpu_id: The GPU index used to run the export. We can specify the GPU index used to run export when the machine has multiple GPUs installed. Note that export can only run on a single GPU.output_file: The path to save the exported model to. The default path is in the same directory as the\*.tltmodel.
Here’s an example of using the PoseClassificationNet export command:
tao pose_classification export -e $DEFAULT_SPEC -k $YOUR_KEY model=$TRAINED_TLT_MODEL
Use the following command to convert the output JSON metadata from the deepstream-bodypose-3d app and generate spatio-temporal sequences of body poses for inference:
tao pose_classification dataset_convert -k <key>
-e <experiment_spec>
data=<path to deepstream-bodypose-3d output data>
output_dir=<path to directory for output>
[pose_type=<pose type>]
[num_joints=<number of joints>]
[frame_width=<frame width>]
[frame_height=<frame height>]
[focal_length=<focal length>]
[sequence_length_max=<maximum sequence length>]
[sequence_length_min=<minimum sequence length>]
[sequence_length=<sequence length for sampling>]
[sequence_overlap=<sequence overlap for sampling>]
Required Arguments
-e, --experiment_spec: The experiment spec file to set up dataset conversion-k, --key: The encoding key for the.tltmodeldata: The output JSON data from the deepstream-bodypose-3d appoutput_dir: The directory for output
Optional Arguments
pose_type: The pose type can be chosen from 3dbp, 25dbp, 2dbpnum_joints: The number of joint points in the graph layoutframe_width: The width of frame images in pixels for normalizationframe_height: The height of frame images in pixels for normalizationfocal_length: The focal length of the camera for normalizationsequence_length_max: The maximum sequence length for defining array shapesequence_length_min: The minimum sequence length for filtering short sequencessequence_length: The general sequence length for samplingsequence_overlap: The overlap between sequences for sampling
Here’s an example of using the PoseClassificationNet dataset_convert command:
tao pose_classification dataset_convert -e $DEFAULT_SPEC -k $YOUR_KEY data=$3D_BODYPOSE_JSON output_dir=$OUTPUT_DIR
The expected output would be a sampled array for each individual tracked ID saved under the output directory.
You can deploy the trained deep learning and computer-vision models on edge devices,
such as a Jetson Xavier, Jetson Nano, Tesla, or in the cloud with NVIDIA GPUs. The exported
\*.etlt model can be used in the TAO Toolkit Triton Apps.
Running PoseClassificationNet Inference on the Triton Sample
The TAO Toolkit Triton Apps provide an inference sample for Pose Classification. It consumes a TensorRT engine and supports running with either (1) a NumPy array of skeleton series or (2) output JSON metadata from the deepstream-bodypose-3d app.
To use this sample, you need to generate the TensorRT engine from an \*.etlt model using
tao-converter.
Generating TensorRT Engine Using
tao-converter
The tao-converter tool is provided with the TAO Toolkit
to facilitate the deployment of TAO trained models on TensorRT and/or Deepstream.
This section elaborates on how to generate a TensorRT engine using tao-converter.
For deployment platforms with an x86-based CPU and discrete GPUs, the tao-converter
is distributed within the TAO docker. Therefore, we suggest using the docker to generate
the engine. However, this requires that the user adhere to the same minor version of
TensorRT as distributed with the docker. The TAO docker includes TensorRT version 8.0.
Instructions for x86
For an x86 platform with discrete GPUs, the default TAO package includes the tao-converter
built for TensorRT 8.2.5.1 with CUDA 11.4 and CUDNN 8.2. However, for any other version of CUDA and
TensorRT, please refer to the overview section for download. Once the
tao-converter is downloaded, follow the instructions below to generate a TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/x86_64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/x86_64-linux-gnu”
Run the
tao-converterusing the sample command below and generate the engine.Instructions to build TensorRT OSS on Jetson can be found in the TensorRT OSS on x86 section above or in this GitHub repo.
Make sure to follow the output node names as mentioned in the Exporting the Model section of the respective model.
Instructions for Jetson
For the Jetson platform, the tao-converter is available to download in the NVIDIA developer zone. You may choose
the version you wish to download as listed in the overview section.
Once the tao-converter is downloaded, please follow the instructions below to generate a
TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/aarch64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/aarch64-linux-gnu”
For Jetson devices, TensorRT comes pre-installed with Jetpack. If you are using older JetPack, upgrade to JetPack-5.0DP.
Instructions to build TensorRT OSS on Jetson can be found in the TensorRT OSS on Jetson (ARM64) section above or in this GitHub repo.
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Using the
tao-converter
Here is a sample command to generate the PoseClassificationNet engine through tao-converter:
#convert ST-GCN model with 3D poses, input sequence length of 300, and 34 keypoints:
tao-converter <etlt_model> \
-k <key_to_etlt_model> \
-d 3,300,34,1 \
-p input,1x3x300x34x1,4x3x300x34x1,16x3x300x34x1 \
-o fc_pred \
-t fp16 \
-m 16 \
-e <path_to_generated_trt_engine>
This command will generate an optimized TensorRT engine.
Running the Triton Inference Sample
You can generate the TensorRT engine when starting the Triton server using the following command:
bash scripts/start_server.sh
When the server is running, you can get results from a NumPy array of test data with the client using the command mentioned below:
python tao_client.py <path_to_test_data> \
-m pose_classification_tao \
-x 1 \
-b 1 \
--mode Pose_classification \
-i https \
-u localhost:8000 \
--async \
--output_path <path_to_output_directory>
The server will perform inference on the input test data. The results are saved as a text file
where each line is formatted as
[sequence_index], [rank1_pred_score]([rank1_class_index])=[rank1_class_name], [rank2_pred_score]([rank2_class_index])=[rank2_class_name], ..., [rankN_pred_score]([rankN_class_index])=[rankN_class_name].
The expected output for the NVIDIA test data would be as follows:
0, 27.6388(2)=sitting, 12.0806(3)=standing, 7.0409(1)=getting_up, -3.4164(0)=sitting_down, -16.4449(4)=walking, -26.9046(5)=jumping
1, 21.5809(2)=sitting, 8.4994(3)=standing, 5.1917(1)=getting_up, -2.3813(0)=sitting_down, -12.4322(4)=walking, -20.4436(5)=jumping
2, 5.6206(0)=sitting_down, 4.7264(4)=walking, -1.0996(5)=jumping, -2.3501(1)=getting_up, -3.2933(3)=standing, -3.5337(2)=sitting
....
You can also get inference results from the JSON output of the deepstream-bodypose-3d app using the following command:
python tao_client.py <path_to_json_file> \
--dataset_convert_config ../dataset_convert_specs/dataset_convert_config_pose_classification.yaml \
-m pose_classification_tao \
-x 1 \
-b 1 \
--mode Pose_classification \
-i https \
-u localhost:8000 \
--async \
--output_path <path_to_output_directory>
- The server will perform inference on the input JSON file. The results are also saved as a JSON
file, which follows the same format as the input and adds the predicted "action" to each
object at each frame. A sample of the JSON output would be as follows:
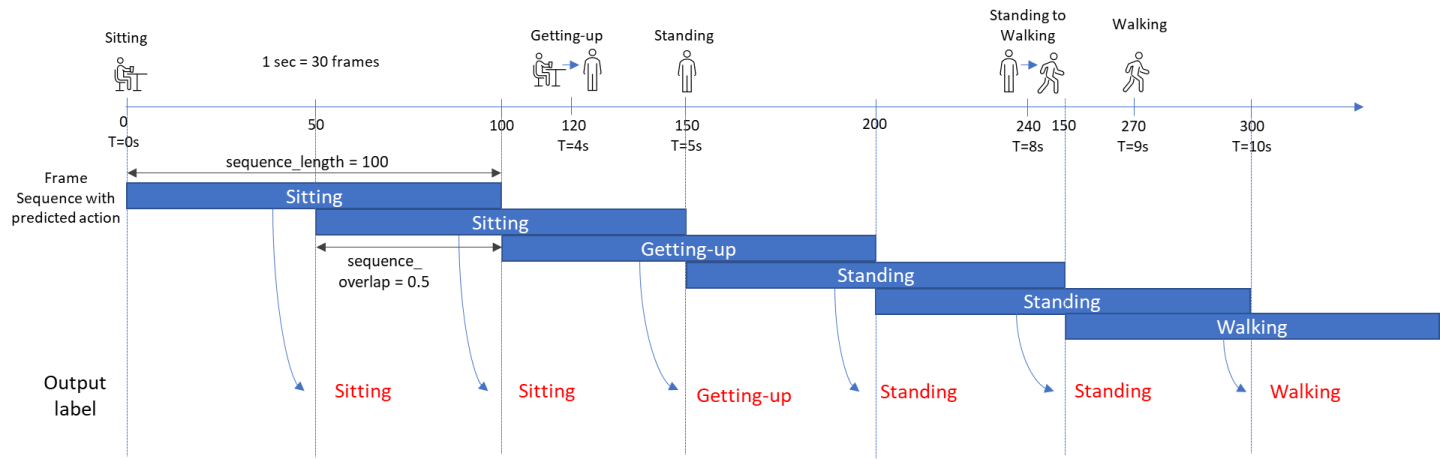
The skeleton sequence of each object is broken into segments by a dataset converter
(refer to the figure below). The sequence_length and sequence_overlap are
configurable in dataset_convert_config_pose_classification.yaml. The output labels are
assigned to frames after a certain period of time.
End-to-End Inference Using Triton
A sample for end-to-end inference from video is also provided in the TAO Toolkit Triton Apps. The sample runs deepstream-bodypose-3d to generate metadata of bounding boxes, tracked IDs, and 2D/3D poses that are saved in JSON format. The client implicitly converts the metadata into arrays of skeleton sequences and sends them to the Triton server. The predicted action for each sequence is returned and appended to the JSON metadata at corresponding frames. A video with overlaid metadata is also generated for visualization.
You can start the Triton server using the following command (only the Pose Classification model will be downloaded and converted into a TensorRT engine):
bash scripts/pose_cls_e2e_inference/start_server.sh
Once the Triton server has started, open up another terminal and run the following command to begin body pose estimation using DeepStream and run Pose Classification on the DeepStream output using the Triton server instance that you previously spun up:
bash scripts/pose_cls_e2e_inference/start_client.sh