PeopleNet Transformer
The PeopleNet Transformer model detects one or more physical objects from three categories within an image and returns a bounding box around each object, as well as a category label for each object. Three categories of objects detected by these models are:
persons
bags
faces
This model is based on the Deformable DETR object detector with ResNet50 as a feature extractor. This architecture utilizes the attention modules that only attend to a small set of key sampling points around a reference to optimize training and inference speed. PeopleNet-Transformer was modified from the original Deformable DETR by reducing the number of features from the backbone from 4 to 2 for optimized performance on Deformable-DETR object detector.
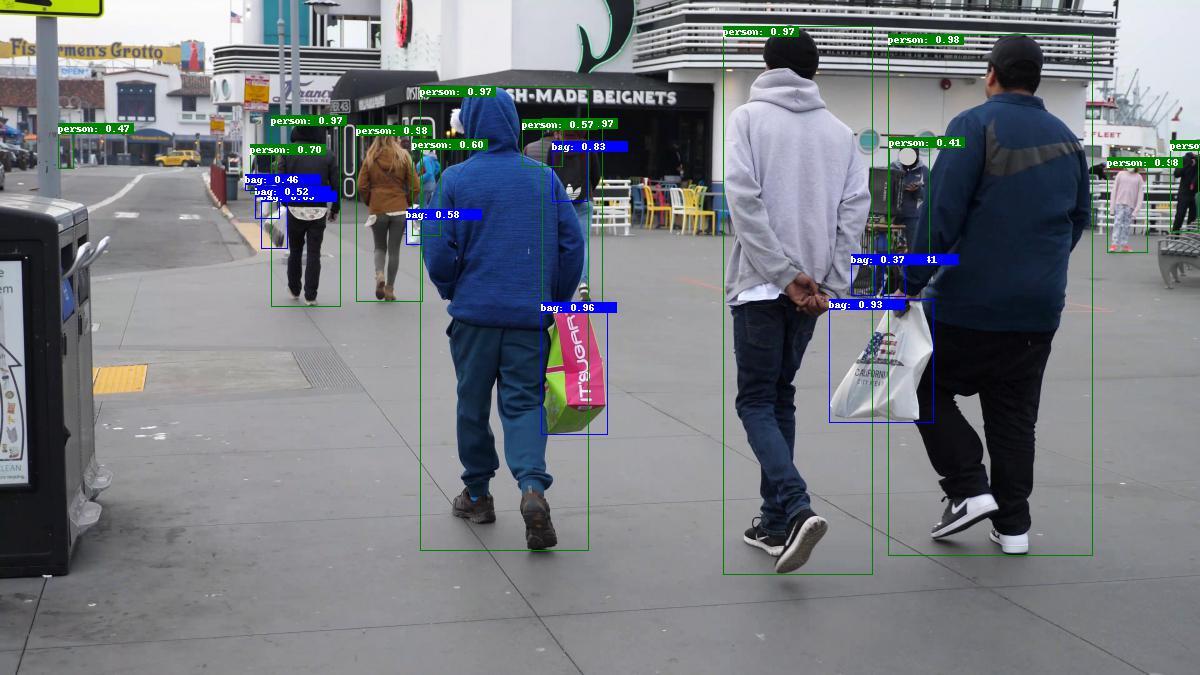
PeopleNet-Transformer use case
The training algorithm optimizes the network to minimize the localization and confidence loss for the objects.
The primary use case intended for these models is detecting people in a color (RGB) image. The model can be used to detect people from photos and videos by using appropriate video or image decoding and pre-processing. As a secondary use case, the model can also be used to detect bags and faces from images or videos. However, these additional classes are not the main intended use for these models.
The datasheet for the model is captured in its model card hosted at NGC.