Gaze Estimation
GazeNet is an NVIDIA developed gaze estimation model which is included in the TAO Toolkit as one of the models supported. With GazeNet the following tasks are supported:
dataset_converttrainevaluateinferenceexport
These tasks may be invoked from the TAO Toolkit Launcher by following the below mentioned convention from command line:
tao gazenet <sub_task> <args_per_subtask>
where args_per_subtask are the command line arguments required for a given subtask. Each of these sub-tasks are explained
in detail below.
As described in the Data Annotation Format section, the GazeNet app
requires a defined JSON format data to be converted to TFRecords. This can be done using the
dataset_convert subtask under GazeNet.
The dataset_convert tool takes in a defined json format data and convert it to the TFRecords that the
GazeNet model ingests. See the following sections for the sample usage examples.
Sample Usage of the Dataset Converter Tool
The labeling json data format is the accepted dataset format for GazeNet. The labeling json data
format must be converted to the TFRecord file format for ingestion. The sampe usage for the
dataset_convert tool is as mentioned below.
tao gazenet dataset_convert [-h] -folder-suffix TFRECORDS_FOLDER_SUFFIX
-norm_folder_name NORM_DATA_FOLDER_NAME
-sets DATASET_NAME
-data_root_path DATASET_ROOT_PATH
You can use these optional arguments:
-h, --help: Show this help message and exit.-folder-suffix, --ground_truth_experiment_folder_suffix: suffix of folder including generated.tfrecordsfiles.-norm_folder_name --norm_folder_name: Folder to generate normalized.-data_root_path, –-data_root_path: root path to the dataset.-sets --set_ids: name of the dataset.
Here’s an example of using the command with the dataset:
tao gazenet dataset_convert -folder-suffix <tfrecord_folder_suffix> -norm_folder_name <norm data folder name>> \
-sets sample-set <dataset name> -data_root_path <root path to the dataset>
Output log from executing tao gazenet dataset_convert:
Using TensorFlow backend.
Test ['p01-1']
Validation ['p01-0']
Train ['p01-4', 'p01-3', 'p01-2']
Test ['p01-1']
Validation ['p01-0']
Train ['p01-4', 'p01-3', 'p01-2']
To do training, evaluation, and inference for GazeNet, several components need to be configured, each with
their own parameters. The train, evaluate, and inference tasks for a GazeNet
experiment share the same configuration file.
The specification file for GazeNet training configures the following components of training pipeline:
Trainer/Evaluator
Model
Loss
Optimizer
Dataloader
Augmentation
Trainer/Ealuator
GazeNet trainer and evaluator share the same configurations.
Here’s a sample example to config GazeNet trainer.
__class_name__: GazeNetTrainer
checkpoint_dir: null
checkpoint_n_epoch: 1
dataloader:
...
evaluation_metric: rmse
network_inputs: face_and_eyes_and_fgrid
infrequent_summary_every_n_steps: 0
log_every_n_secs: 10
model_selection_metric: logcosh
num_epoch: 2
random_seed: 42
hooks: null
enable_visualization: false
loss:
...
model:
...
optimizer:
...
visualize_bins_2d: 5
visualize_bins_3d: 100
visualize_num_images: 3
The following table describes the parameters used to config the trainer:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
__class_name__ |
string |
GazeNetTrainer |
Name for the trainer specification |
GazeNetTrainer |
|
string |
|
Path to the checkpoint. If not specified, will save all checkpoints in the output folder |
NA |
|
int |
|
Save checkpoint per n number of epochs |
1 to num_epoch |
|
structure |
|
Dataloader specification |
1 to num_epoch |
|
string |
|
Metric used during KPI testing |
rmse |
|
string |
|
Input type (only ‘face_and_eyes_and_fgrid’ is supported) |
face_and_eyes_and_fgrid |
|
int |
|
Infrequent summary every n epoch |
0 to num_epoch |
|
int |
|
Log the training output for every n secs |
NA |
|
string |
|
Metric used to select final model |
logcosh |
|
int |
|
Number of epochs |
NA |
|
int |
|
Random seed used during the experiments |
NA |
|
boolean |
|
Toggle to enable visualization |
false/true |
|
int |
|
Resolution for 2D data distribution visualization |
NA |
|
int |
|
Resolution for 3D data distribution visualization |
NA |
|
int |
|
Number of data images to show on Tensorboard |
NA |
Model
GazeNet can be configured using the model option in the spec file.
Here’s a sample model config to instantiate a GazeNet model with pretrained weights and the number of freeze blocks.
model:
__class_name__: GazeNetBaseModel
model_parameters:
dropout_rate: 0.25
frozen_blocks: 5
num_outputs: 5
pretrained_model_path: /workspace/tao-experiments/gazenet/pretrain_models/model.tlt
regularizer_type: l2
regularizer_weight: 0.002
type: GazeNet_public
use_batch_norm: true
The following table describes the model parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
__class_name__ |
string |
GazeNetBaseModel |
Name for the model config |
GazeNetBaseModel |
|
float |
|
Probability for drop out |
0.0-1.0 |
|
int |
|
This parameter defines how many blocks that will be frozen during training. If the value for this variable is set to be larger than 0, provide a pretrain model. |
0,1,2,3,4,5,6 |
|
int |
|
Number of outputs (x, y, z point of regards amd theta, phi gaze vector) |
5 |
|
string |
|
Path to the pretrain model |
NA |
|
string |
|
Type of the regularization |
l1/l2/None |
|
float |
|
Factor of the regularization |
0.0-1.0 |
|
string |
|
Type of supported GazeNet model. Only “GazeNet_public” is currently supported. |
GazeNet_public |
|
boolean |
|
Boolean variable to use batch normalization layers or not |
true/false |
Loss
This section helps you configure the parameters for loss, optimizer, and learning rate scheduler for optimizer.
loss:
__class_name__: GazeLoss
loss_type: logcosh
The following table describes the loss parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
__class_name__ |
string |
GazeLoss |
Name of the loss config |
NA |
|
string |
logcosh |
Type of the loss function |
l1/rmse/cosine/l1_cosine_joint/l2_cosine_joint/logcosh l1: l1 loss rmse: root mean square error l1_cosine_joint: l1 loss for x, y, z point of regards cosine loss for theta and phi l2_cosine_joint: l2 loss for x, y, z point of regards cosine loss for theta and phi logcosh: log-cosh loss |
Optimizer
optimizer:
__class_name__: AdamOptimizer
beta1: 0.9
beta2: 0.999
epsilon: 1.0e-08
learning_rate_schedule:
__class_name__: SoftstartAnnealingLearningRateSchedule
annealing: 0.8
base_learning_rate: 0.003
last_step: 263000
min_learning_rate: 5.0e-07
soft_start: 0.2
The following table describes the optimizer parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
__class_name__ |
string |
AdamOptimizer |
Name of the optimizer config |
AdamOptimizer/AdadeltaOptimizer/GradientDescentOptimizer |
|
float |
|
The exponential decay rate for the 1st moment estimates |
0-1 |
|
float |
|
The exponential decay rate for the 2nd moment estimates |
0-1 |
|
float |
|
A small constant for numerical stability |
NA |
|
structure |
|
Type of learning rate schedule |
SoftstartAnnealingLearningRateSchedule ConstantLearningRateSchedule ExponentialDecayLearningRateSchedule |
The following table describes the learning_rate_schedule parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
__class_name__ |
string |
SoftstartAnnealingLearningRateSchedule |
Name of the learning rate schedule config |
SoftstartAnnealingLearningRateSchedule - This scheduling has soft starting and ending learning rate value ConstantLearningRateSchedule - This scheduling has constant learning rate value ExponentialDecayLearningRateSchedule - This scheduling has learning rate that are decay exponentially |
|
float |
|
Indicating the fraction of last_step that will be taken before reaching the base_learning rate |
0-1 |
|
float |
|
Indicating the fraction of last_step after which the learning rate ramps down from base_learning rate |
0-1 |
|
float |
|
Learning rate |
0-1 |
|
float |
|
Minimum value the learning rate will be set to |
0-1 |
|
int |
|
Last step the schedule is made for |
NA |
GazeNet currently supports the soft-start annealing learning rate schedule. The learning rate when plotted as a function of the training progress (0.0, 1.0) results in the following curve.
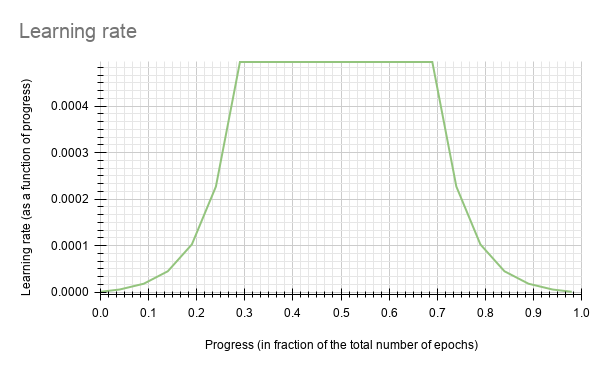
In this experiment, the soft start was set as 0.2 and annealing as 0.8 with minimum learning rate as 2.0e-07 and a maximum learning rate or base_lr as 0.0002.
Dataloader
The dataloader module provides parameters used for dataset pre-processing, some basic pre-processing, data and dataloader when training. Here
is a sample dataloader specification element:
dataloader:
__class_name__: GazeNetDataloaderAugV2
augmentation_info:
...
batch_size: 128
dataset_info:
...
eye_scale_factor: 1.8
face_scale_factor: 1.3
filter_phases:
- training
- testing
- validation
- kpi_testing
filter_info:
...
image_info:
facegrid:
channel: 1
height: 25
width: 25
image_face:
channel: 1
height: 224
width: 224
image_frame:
channel: 1
height: 480
width: 640
image_left:
channel: 1
height: 224
width: 224
image_right:
channel: 1
height: 224
width: 224
input_normalization_type: zero-one
kpiset_info:
...
learn_delta: false
use_head_norm: false
num_outputs: 5
theta_phi_degrees: false
use_narrow_eye: true
add_test_to: null
The following table describes the dataloader specification parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
__class_name__ |
string |
GazeNetDataloaderAugV2 |
Name of the dataloader specification |
GazeNetDataloaderAugV2 |
|
structure |
|
Augmentation specification |
NA |
|
int |
|
Batch size |
0-1 |
|
structure |
|
dataset specification |
0-1 |
|
float |
|
Scaling factor for eyes (if value is larger than 1, then eye crop is enlarged) |
NA |
|
float |
|
Scaling factor for the face (if value is larger than 1, then face crop is enlarged) |
NA |
|
structure |
|
Phase to apply the filter |
training/testing/validation/kpi_testing |
|
structure |
|
Data filter variables and criteria |
NA |
|
structure |
|
Input image information |
facegrid, image_face, image_frame, image_left, image_right |
|
int |
|
Input normalization type |
zero-one |
|
string |
|
Input normalization type |
zero-one |
|
structure |
|
KPI set information |
NA |
|
boolean |
|
Boolean values to enable/disable learning of variable difference |
false |
|
boolean |
|
Data filter variable and criteria |
false |
|
int |
|
Number of outputs (x, y, z point of regards amd theta, phi gaze vector) |
5 |
|
boolean |
|
Boolean values to enable/disable theta phi learning |
false |
|
boolean |
|
Boolean values to enable/disable tight eye input |
true/false |
|
string |
|
Testing dataset from dataio can be added to training or validation. By default, will keep testing dataset for KPI usage |
null/training/validation |
dataset_info:
ground_truth_folder_name:
- Ground_Truth_DataFactory_pipeline
image_extension: png
root_path: null
test_file_name: test.tfrecords
tfrecord_folder_name:
- TfRecords_joint_combined
tfrecords_directory_path:
- /workspace/tao-experiments/gazenet/data/MPIIFaceGaze/sample-dataset
tfrecords_set_id:
- p01-day03
train_file_name: train.tfrecords
validate_file_name: validate.tfrecords
The following table describes the dataset_info parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
|
string |
|
Ground truth folder name |
NA |
|
string |
|
Image extension |
NA |
|
string |
|
Root path |
null |
|
string |
|
File name for test tfrecords |
NA |
|
string |
|
Tfrecords folder name |
NA |
|
string |
|
Path to Tfrecords directory |
NA |
|
string |
|
Set ID |
NA |
|
string |
|
File name for train tfrecords |
NA |
|
string |
|
File name for validate tfrecords |
NA |
filter_info:
- desired_val_max: 400.0
desired_val_min: -400.0
feature_names:
- label/gaze_cam_x
- desired_val_max: 400.0
desired_val_min: -400.0
feature_names:
- label/gaze_cam_y
- desired_val_max: 300.0
desired_val_min: -300.0
feature_names:
- label/gaze_cam_z
The following table describes the filter_info parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
|
string |
|
Feature name |
label/gaze_cam_x, label/gaze_cam_y, label/gaze_cam_z |
|
float |
|
Maximum value for the feature |
NA |
|
float |
|
Minimum value for the feature |
NA |
kpiset_info:
ground_truth_folder_name_kpi:
- Ground_Truth_DataFactory_pipeline
kpi_file_name: test.tfrecords
kpi_root_path: null
kpi_tfrecords_directory_path:
- /workspace/tao-experiments/gazenet/data/MPIIFaceGaze/sample-dataset
tfrecord_folder_name_kpi:
- TfRecords_joint_combined
tfrecords_set_id_kpi:
- p01-day03
The following table describes the dataset_info parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
|
string |
|
Ground truth folder name for KPI dataset |
NA |
|
string |
|
File name for KPI tfrecords |
NA |
|
string |
|
KPI root path |
Reserved value, currently only null is supported |
|
string |
|
Path to KPI Tfrecords directory |
NA |
|
string |
|
KPI tfrecords folder name |
NA |
|
string |
|
KPI tfrecords set ID |
NA |
Augmentation
The augmentation module provides some basic pre-processing and augmentation when training. Here
is a sample augmentation element:
augmentation_info:
blur_augmentation:
blur_probability: 0.0
kernel_sizes:
- 1
- 3
- 5
- 7
- 9
enable_online_augmentation: true
gamma_augmentation:
gamma_max: 1.1
gamma_min: 0.9
gamma_probability: 0.1
gamma_type: uniform
modulus_color_augmentation:
contrast_center: 127.5
contrast_scale_max: 0.0
hue_rotation_max: 0.0
saturation_shift_max: 0.0
modulus_spatial_augmentation:
hflip_probability: 0.5
zoom_max: 1.0
zoom_min: 1.0
random_shift_bbx_augmentation:
shift_percent_max: 0.16
shift_probability: 0.9
The following table describes the augmentation parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
__class_name__ |
string |
GazeNetDataloaderAugV2 |
Name of the dataloader specification |
GazeNetDataloaderAugV2 |
|
structure |
|
Augmentation specification |
NA |
|
structure |
|
Blur augmentation specification |
NA |
|
float |
|
Probability of imgages to apply blur augmentation |
0.0 - 1.0 |
|
int |
|
Kernel size for the blur operation |
1, 3, 5, 7, 9 |
|
boolean |
|
Boolean values to enable/disable augmentation |
true/false |
|
structure |
|
Gamma augmentation specification |
NA |
|
float |
|
Maximum value of gamma variable |
1.0 - 1.4 |
|
float |
|
Minimum value of gamma variable |
0.7 - 1.0 |
|
float |
|
Probability of data to apply gamma augmentation |
uniform |
|
string |
|
Type of gamma augmentation |
true/false |
|
structure |
|
Color argumentation specification |
NA |
|
float |
|
Contrast center for color argumentation |
0 - 255 |
|
float |
|
Maximum scale of contrast change |
NA |
|
float |
|
Maximum hue rotation change |
NA |
|
float |
|
Maximum saturation shift change |
NA |
|
structure |
|
Spatial augmentation specification |
NA |
|
float |
|
Probability of data to apply horizontal flip |
0.0 - 1.0 |
|
float |
|
Maximum zoom scale |
NA |
|
float |
|
Minimum zoom scale |
NA |
|
structure |
|
Bounding box random ship augmentation |
NA |
|
float |
|
Maximum percent shift of the bounding box |
NA |
|
float |
|
Probability of data to apply random shift augmentation |
0.0 - 1.0 |
After following the steps to Pre-processing the Dataset to create TFRecords ingestible by the TAO training, and setting up a spec file. You are now ready to start training a gaze estimation network.
GazeNet training command:
tao gazenet train [-h] -e <spec_file>
-r <result directory>
-k <key>
Required Arguments
-r, --results_dir: Path to a folder where experiment outputs should be written.-k, –key: User specific encoding key to save or load a.tltmodel.-e, --experiment_spec_file: Path to spec file. Absolute path or relative to working directory.
Optional Arguments
-h, --help: To print help message.
Sample Usage
Here is an example of command for gazenet training:
tao gazenet train -e <path_to_spec_file>
-r <path_to_experiment_output>
-k <key_to_load_the_model>
The tao gazenet train tool can support training on images of different resolutions.
Face, left eye, and right eye crop is obtained online through dataloader. However,
it requires all input images to have the same resolution.
Execute evaluate on a GazeNet model.
tao gazenet evaluate [-h] -type <testing dataset type>
-m <model_file>
-e <experiment_spec>
-k <key>
Required Arguments
-e, --experiment_spec_file: Experiment spec file to set up the evaluation experiment. This should be the same as training spec file.-m, --model: Path to the model file to use for evaluation. This could be a.tltmodel file or a tensorrt engine generated using the export tool.-k, -–key: Provide the encryption key to decrypt the model. This is a required argument only with a.tltmodel file.
Optional Arguments
-h, --help: show this help message and exit.
If you have followed the example in Training the Model, you may now evaluate the model using the following command:
tao gazenet evaluate -type <testing data type>
-e <path to training spec file>
-m <path to the model>
-k <key to load the model>
This command runs evaluation on the testing/KPI dataset.
Use these steps to evaluate on a new test set with ground truth labeled:
Create tfrecords for this test set by following the steps listed in Pre-processing the Dataset section.
Update the dataloader configuration part of the training experiment spec file to update kpiset_info with newly generated tfrecords for the test set. For more information on the dataset config, refer to Creating an Experiment Specification File. The evaluate tool iterates through all the folds in the kpiset_info.
kpiset_info:
ground_truth_folder_name_kpi:
- Ground_Truth_Folder_Dataset1
- Ground_Truth_Folder_Dataset2
kpi_file_name: test.tfrecords
kpi_root_path: null
kpi_tfrecords_directory_path:
- /path_to_kpi_dataset1
- /path_to_kpi_dataset2
tfrecord_folder_name_kpi:
- TfRecords_joint_combined
- TfRecords_joint_combined
tfrecords_set_id_kpi:
- kpi_dataset1
- kpi_dataset2
The rest of the experiment spec file remains the same as the training spec file.
The inference task for gazenet may be used to visualize gaze vector. An
example of the command for this task is shown below:
tao gazenet inference [-h] -e </path/to/inference/spec/file> \
-i </path/to/inference/input> \
-m <model_file> \
-o </path/to/inference/output> \
-k <model key>
Required Parameters
-e, --inference_spec: Path to an inference spec file.-i, --inference_input: The directory of input images or a single image for inference.-o, --inference_output: The directory to the output images and labels.-k, --enc_key: Key to load model.
Sample usage for the inference sub-task
Here’s a sample command to run inference for a testing dataset.
tao gazenet inference -e $SPECS_DIR/gazenet_tlt_pretrain.yaml \
-i $DATA_DOWNLOAD_DIR/inference-set \
-m $USER_EXPERIMENT_DIR/experiment_result/exp1/model.tlt \
-o $USER_EXPERIMENT_DIR/experiment_result/exp1 \
-k $KEY
Exporting the GazeNet Model
Here’s an example of the command line arguments of the export command:
tao gazenet export [-h] -m <path to the .tlt model file generated by tao train>
-o <path to output file>
-t tfonnx
-k <key>
Required Arguments
-m, --model_filename: Path to the .tlt model file to be exported usingexport.-k, --output_filename: Key used to save the.tltmodel file.-o, --key: Key used to save the.tltmodel file.-t, --export_type: Model type to export to. Only ‘tfonnx’ is support in TAO Toolkit 3.0-21.08.
Sample usage for the export sub-task
Here’s a sample command to export a GazeNet model.
tao gazenet export -m $USER_EXPERIMENT_DIR/experiment_result/exp1/model.tlt
-o $USER_EXPERIMENT_DIR/experiment_dir_final/gazenet_onnx.etlt
-t tfonnx
-k $KEY
Deploying to DeepStream 6.0
The pretrained model for GazeNet provided through NGC is available by default with DeepStream 6.0.
For more details, refer to DeepStream TAO Integration for GazeNet.