Overview
The NVIDIA TAO Toolkit allows you to combine NVIDIA pre-trained models with your own data to create custom Computer Vision (CV) and Conversational AI models. With a basic understanding of deep learning and minimal to zero coding required, TAO Toolkit will allow you to:
Fine-tune models for CV use cases such as object detection, image classification, segmentation, and key-point estimation using NVIDIA pre-trained CV models.
Fine-tune models for Conversational AI use cases such as automatic speech recognition (ASR) or natural language processing (NLP) using NVIDIA pre-trained conversational AI models.
Add new classes to an existing pre-trained model.
Re-train a model to adapt to different use cases.
Use the model pruning capability on CV models to reduce the overall size of the model.
TAO Toolkit uses a simple Command Line Interface (CLI), which abstracts away AI framework complexity, enabling you to build production-quality AI models using just a spec file and one of the NVIDIA pre-trained models. This guide includes sample spec files and parameter definitions for all models supported by TAO Toolkit.
What is Transfer Learning?
Transfer learning is the process of transferring learned features from one application to
another. It is a commonly used training technique, where a model trained on one task is
re-trained for use on a different task. This works surprisingly well, as many of the early
layers in a neural network are the same for similar tasks. For example, early layers in a
convolutional neural network for CV are primarily used to identify outlines, curves, and other
features in an image. The learned features from these layers can be applied to similar tasks
carrying out the same identification in other domains. With transfer learning, less data is
required to accurately train a model compared to training that same model from scratch. To learn
more about transfer learning, read this blog.
TAO Toolkit is a Python package hosted on the NVIDIA Python Package Index. It interacts with lower-level TAO dockers available from the NVIDIA GPU Accelerated Container Registry (NGC); TAO containers come pre-installed with all dependencies required for training. The CLI is run from Jupyter notebooks packaged inside each docker container and consists of a few simple commands, such as train, evaluate, infer, prune, export, and augment (i.e. data augmentation). The output of the TAO workflow is a trained model that can be deployed for inference on NVIDIA devices using DeepStream, TensorRT, and Riva.
The TAO application layer is built on top of CUDA-X, which contains all the lower-level NVIDIA libraries, including NVIDIA Container Runtime for GPU acceleration, CUDA and cuDNN for deep learning (DL) operations, and TensorRT (the NVIDIA inference optimization and runtime engine) for optimizing models. Models that are generated with TAO Toolkit are completely compatible with and accelerated for TensorRT, which ensures maximum inference performance without any extra effort.

In a typical computer vision (CV) workflow, you start with a pre-trained model from NGC, either a highly accurate purpose-built model or just the pre-trained weights of an architecture, along with your own dataset.
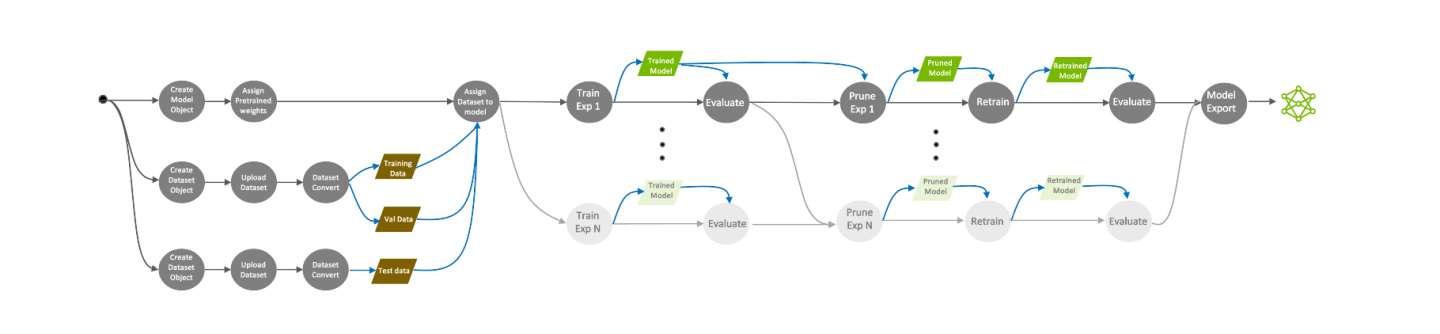
Data Augmentation
You first feed your dataset into the data converter, which can augment the data to introduce variations in the dataset. This is very important in training, as data variation improves the overall quality of the model and prevents overfitting.
You can also perform offline augmentation, where the dataset is augmented before training. See the Offline Data Augmentation section for more information.
Training
Once the dataset is prepared and augmented, the next step is to start training. You use a spec file to choose the training hyperparameters. Each model section in this user giude contains more information about available hyperparameters.
Evaluation
After the first training phase, you will evaluate the model against a test set to see how the model performs with data it has never seen before. If the model is accurate enough for your application, the next step is model pruning. If model accuracy is not sufficient, then you may need to tune some hyperparameters and re-train. Training is an iterative process, so you might need to try a few times before converging on the right model.
Pruning
When pruning the model, TAO will algorithmically remove neurons from the neural network that do not contribute significantly to the overall accuracy. Model pruning is only supported on CV models, so if you are training a Conv AI model, you can skip this step and go directly to model export.
Re-training
Pruning the model will reduce the accuracy of the model, so the next step is to re-train the model on the same dataset to recover the lost accuracy. After re-training, you will evaluate the model on the same test set. If the accuracy has been restored to what was before pruning, you can move on to the model export step.
At this point, you should feel confident in the accuracy and inference performance of the model.
Export
The exported model will be in .etlt format, which can be deployed
directly on any NVIDIA GPU using DeepStream and TensorRT. During the export step, you can
optionally generate an INT8 calibration cache that quantizes the floating-point weights to
integer values. Running inference at INT8 precision can more than double performance compared to
FP16 or FP32 precision, without sacrificing the accuracy of the model.
To learn more about model export and deployment, see the Exporting the model and Deploying to DeepStream sections for different object detection models.
Once exported, any computer vision model in TAO may be deployed to a TensorRT optimized engine using the TAO converter. Refer to this section for more information about the TAO converter and the TensorRT version matrix.

The TAO ConvAI workflow is very similar to the TAO computer vision workflow described above,
except that pruning is not available for ConvAI at this time and retraining has a specific command
called finetune.
The export of ConvAI is also slightly different: You can choose to export a .riva file, which
can be deployed to Riva, or .eonnx file, which can be used by the infer_onnx command.
Currently, exporting a ConvAI model to a TensorRT engine file is not supported.
Model pruning is one of the key differentiators for TAO Toolkit. Pruning involves removing from the neural network nodes that contribute less to the overall accuracy of the model, reducing the overall size of the model, significantly reducing the memory footprint, and increasing inference throughput–all factors that are very important for edge deployment.
Currently, pruning is supported on most CV models, but not on Conversational AI models. The following graph provides an example of performance gains achieved when going from an unpruned CV model to a pruned CV model (inference was run on an NVIDIA T4; TrafficCamNet, DashCamNet, and PeopleNet are three of the custom pre-trained models that are available on NGC).

Pruned vs Unpruned Performance
To learn more about using TAO Toolkit, read the technical blogs, which provide a step-by-step guide to training with TAO:
Learn how to train with PeopleNet and other pre-trained models using TAO Toolkit.
Learn how to train instance segmentation models using MaskRCNN with TAO Toolkit.
Learn how to improve INT8 accuracy using quantization aware training (QAT) with TAO Toolkit.
Learn how to create a real time license plate detection and recognition app
Learn how to prepare state of the art models for classification and object detection with TAO Toolkit
Learn more on building and deploying conversational AI models using the NVIDIA TAO Toolkit
Learn how to train and optimize a 2D body-pose estimation model with TAO: 2D Pose Estimation Part 1 | 2D Pose Estimation Part 2.
If you have any questions when using TAO Toolkit to train a model and deploy to Riva or DeepStream, post them here: