Imagen#
Model Introduction#
Imagen [MM-MODELS-IMAGEN4] is a multi-stage text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Given a text prompt, Imagen first generates an image at a 64x64 resolution and then upsamples the generated image to 256x256 and 1024x1024 resolutions, all using diffusion models.
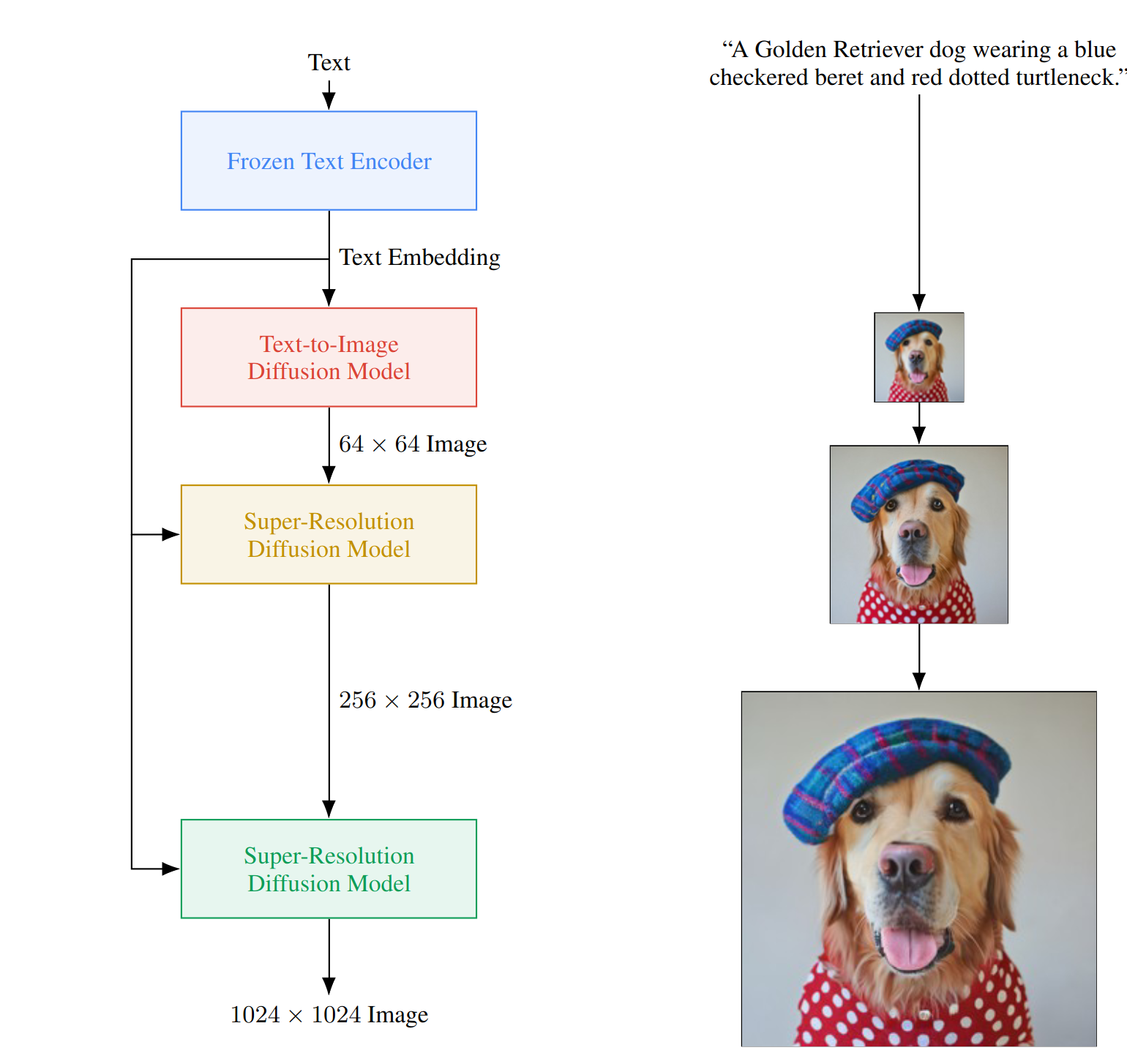
Imagen models can be instantiated using the MegatronImagen class.
Text Encoder#
Imagen employs a text encoder, typically T5, to encode textual features. To enhance efficiency, we strongly recommend preprocessing the training dataset with pre-cached embeddings, given the substantial size of T5 encoders. Loading encoders during training can lead to a notable reduction in training time.
UNet#
Imagen has two types of UNet: Regular UNet and EfficientUNet.
Regular UNet#
Regular UNet is used for Imagen base64 model. You can also use regular UNet for SR models (see example config file sr256-400m-edm.yaml), but this typically results in a larger memory footprint during training for the same model size.
Recommended UNet size for base64 and SR256 models are listed below:
Model |
Resolution |
Hidden Size ( |
Text Condition Size ( |
UNet Size (M) |
|---|---|---|---|---|
500m_res_64 |
64x64 |
256 |
512 |
524 |
2b_res_64 |
64x64 |
512 |
2048 |
2100 |
400m_res_256 |
256x256 |
128 |
512 |
429 |
Efficient UNet#
Efficient UNet is based on Regular UNet with the following modifications:
Shift the model parameters from the high resolution blocks to the low resolution blocks, via adding more residual blocks for the lower resolutions
Scaling skip connection by 1/sqrt(2)
perform downsampling operation before convolution and perform upsampling operation after convolution.
With the aforementioned modifications, Efficient UNet can converge more rapidly and with greater memory efficiency. The Imagen paper states that such a modification has no discernible impact on convergence. However, our empirical findings reveal that the Regular UNet yields slightly better visual quality. Metric-wise, they exhibit similar quality based on FID-CLIP evaluation.
Recommended Efficient UNet size for SR256 and SR1024 models are listed below:
Model |
Resolution |
Hidden Size ( |
Text Condition Size ( |
Attention Block |
UNet Size (M) |
|---|---|---|---|---|---|
600m_res_256 |
256x256 |
128 |
512 |
Fuse Attention |
646 |
400m_res_1024 |
1024x1024 |
128 |
512 |
Cross Attention |
427 |
Noise Scheduling / Sampler#
NeMo Imagen supports two types of noise scheduling: Continous DDPM [MM-MODELS-IMAGEN3] and EDM [MM-MODELS-IMAGEN2].
Denoising diffusion probabilistic models (DDPM) [MM-MODELS-IMAGEN1] represents the most widely adopted noise scheduling approach among all diffusion models. Continuous DDPM introduces several modifications to the standard DDPM framework, with the most significant change being the transition from a discrete noise space to a continuous space.
Elucidating the Design Space of Diffusion-Based Generative Models” (EDM) proposes an enhanced noise level distribution strategy during training. It also identifies the optimal time discretization for sampling and incorporates a higher-order Runge-Kutta method for the sampling process.
Model Configuration#
Text Encoder#
model:
conditioning:
embed_dim: 1024
token_length: 128
drop_rate: 0.1
precached_key: embeddings_t5_xxl
out_key: t5_text
embed_dim represents text feature dimension after encoding. For T5, dimensions are either 1024 or 4096.
token_length specifies the maximum context lnegth. All precached text features will be either trimmed or padded to match this specified length.
drop_rate defines the rate at which random text segments are dropped during training.
embeddings_t5_xxl specifies the key name associated with the precached features in the dataset.
When using online encoding:
model:
conditioning:
online_encoding: True
encoder_path: ???
embed_dim: 1024
token_length: 128
drop_rate: 0.1
Set online_encoding=True and set the text encoder path encoder_path. It will load the text encoder
during training to generate text embedding for the raw text from the dataset.
Regular UNet#
unet_type: base
unet:
embed_dim: 256
image_size: 64
channels: 3
num_res_blocks: 3
channel_mult: [ 1, 2, 3, 4 ]
num_attn_heads: 4
per_head_channels: 64
cond_dim: 512
attention_type: fused
feature_pooling_type: attention
learned_sinu_pos_emb_dim: 0
attention_resolutions: [ 8, 16, 32 ]
dropout: False
use_null_token: False
init_conv_kernel_size: 3
gradient_checkpointing: False
scale_shift_norm: True
stable_attention: True
flash_attention: False
resblock_updown: False
resample_with_conv: True
To configure the UNet model, set unet_type to base for the regular UNet base model or sr-unet for
the super-resolution (SR) model. The embed_dim parameter denotes the base number of channels in each ResBlock.
At each level in the UNet architecture, num_res_blocks defines the number of ResBlocks for that level,
while channel_mult is employed in combination with embed_dim to determine the number of channels at different levels.
cond_dim specifies the size of the conditioning projection.
Imagen supports two methods of time embedding: either learned time positional embedding or unlearned (fixed).
To use unlearned embedding, set learned_sinu_pos_emb_dim to 0; for learned embedding, use a positive number.
The feature_pooling_type parameter specifies the pooling method, which can be either attention or mean.
If you wish to enable model dropout (note that this is different from the text dropout in conditioning),
set the dropout parameter. When resblock_updown is set to False, it indicates the use of ResBlocks for
downsampling and upsampling, as opposed to Torch’s upsample and downsample functions without learnable weights.
If resblock_updown is False, you can use resample_with_conv to determine whether an additional convolutional layer
is needed in addition to pooling and convolution transpose operations.
Efficient UNet#
unet_type: sr
unet:
embed_dim: 128
image_size: 256
channels: 3
channel_mult: [ 1, 2, 4, 8, 8 ]
num_attn_heads: 8
per_head_channels: 64
attention_type: stacked
atnn_enabled_at: [ 0, 0, 0, 1, 1 ]
feature_pooling_type: attention
stride: 2
num_resblocks: [ 2, 4, 8, 8, 8 ]
learned_sinu_pos_emb_dim: 0
use_null_token: False
init_conv_kernel_size: 3
gradient_checkpointing: False
scale_shift_norm: True
stable_attention: False
flash_attention: False
skip_connection_scaling: True
Many of the arguments remain consistent with those for the Regular UNet.
To configure the Efficient UNet SR model training, you should set unet_type to sr.
When using the Efficient UNet SR model, num_resblocks can be specified as a list to define varying numbers
of ResBlocks for each level. Additionally, you have the option to enable skip_connection_scaling,
which scales the skip connections, as detailed in the Imagen paper.
Attention Blocks#
Imagen’s UNet incorporates multiple attention blocks to effectively handle text embeddings. The following arguments in the UNet configurations pertain to these attention blocks:
unet:
attention_type: stacked
attention_resolutions: [8, 16, 32]
stable_attention: False
flash_attention: False
NeMo Imagen has the following attention_type implemented:
self: Multi-head self attention block
cross: Multi-head cross attention block. Imagen paper uses this implementation for SR1024 model.
stacked: Attention blocks that stack oneselfattention andcrossattention
fused: Attention blocks that fuses oneselfattention andcrossattention. Imagen paper uses this implementation for base64 and SR256 model.
Attention blocks can be integrated at various levels within the UNet by specifying the attention_resolutions.
The option stable_attention facilitates the computation of attention block backpropagation in a more
numerically stable manner. You can control whether to utilize the optimized FlashAttention by setting the flash_attention parameter.
Scheduling#
To train NeMo Imagen with EDM, set preconditioning_type=EDM and use the suggested parameters from EDM paper:
preconditioning_type: EDM
preconditioning:
loss_type: l2
sigma_data: 0.5
p_mean: -1.2
p_std: 1.2
Note for EDM scheduling, UNet is trained to predict the denoise image rather than the noise itself. supported loss_type are l1, l2,
and huber.
preconditioning_type: DDPM
preconditioning:
loss_type: l2
pred_objective: noise
noise_schedule: cosine
timesteps: 1000
Setting preconditioning_type=DDPM allows user to train UNet with continous DDPM scheduling. pred_objective can
be either noise or x_start. We currently support linear and cosine modes for noise_schedule.
Training Optimizations#
Feature |
Description |
To Enable |
|---|---|---|
Data parallelism |
Dataset is read concurrently across multiple GPUs or nodes, allowing for faster data loading and processing. |
Automatically when training on multi GPUs/nodes |
Activation Checkpointing |
To reduce memory usage, activations of certain layers are cleared and recomputed during a backward pass. This technique is particularly useful for training large models that wouldn’t fit in GPU memory using traditional methods. |
|
Bfloat16 Training |
Training is conducted in Bfloat16 precision, which offers a balance between the higher precision of FP32 and the memory savings and speed of FP16. |
|
Flash Attention |
FlashAttention is a fast and memory-efficient algorithm to compute exact attention. It speeds up model training and reduces memory requirement by being IO-aware. This approach is particularly useful for large-scale models and is detailed further in the repository linked. [Reference](Dao-AILab/flash-attention) |
|
Channels Last |
ordering NCHW tensors in memory preserving dimensions ordering. |
|
Inductor |
TorchInductor compiler |
|
Reference#
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. 2020. arXiv:2006.11239.
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. 2022. arXiv:2206.00364.
Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. 2021. URL: https://arxiv.org/abs/2102.09672, arXiv:2102.09672.
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. In Conference on Neural Information Processing Systems (NeurIPS). 2022. doi:10.48550/arXiv.2205.11487.