CLIP#
Model Introduction#
Contrastive Language-Image Pre-training (CLIP) [MM-MODELS-CLIP1] offers an efficient method for learning image representations using natural language supervision. The essence of CLIP is to train both an image encoder and a text encoder from scratch. The model aims to predict the correct pairings of a batch of (image, text) training examples by jointly training these encoders. During pre-training, CLIP is designed to predict which images and texts form a semantically coherent pair by maximizing the similarity between the correct (image, text) pairs while minimizing the similarity between incorrect pairs. This contrastive learning approach ensures that CLIP learns meaningful and contextually rich representations of both visual and textual data.
NeMo’s implementation of the CLIP model leverages its parallel transformer implementation, specifically the nemo.collections.nlp.modules.common.megatron.transformer.ParallelTransformer, to enable model parallelism support in both the text encoder and vision model. This design choice ensures efficient scaling and utilization of resources during training. Additionally, some of the model design and loss implementations in NeMo’s CLIP are inspired by the open-source [open_clip](mlfoundations/open_clip) repository.
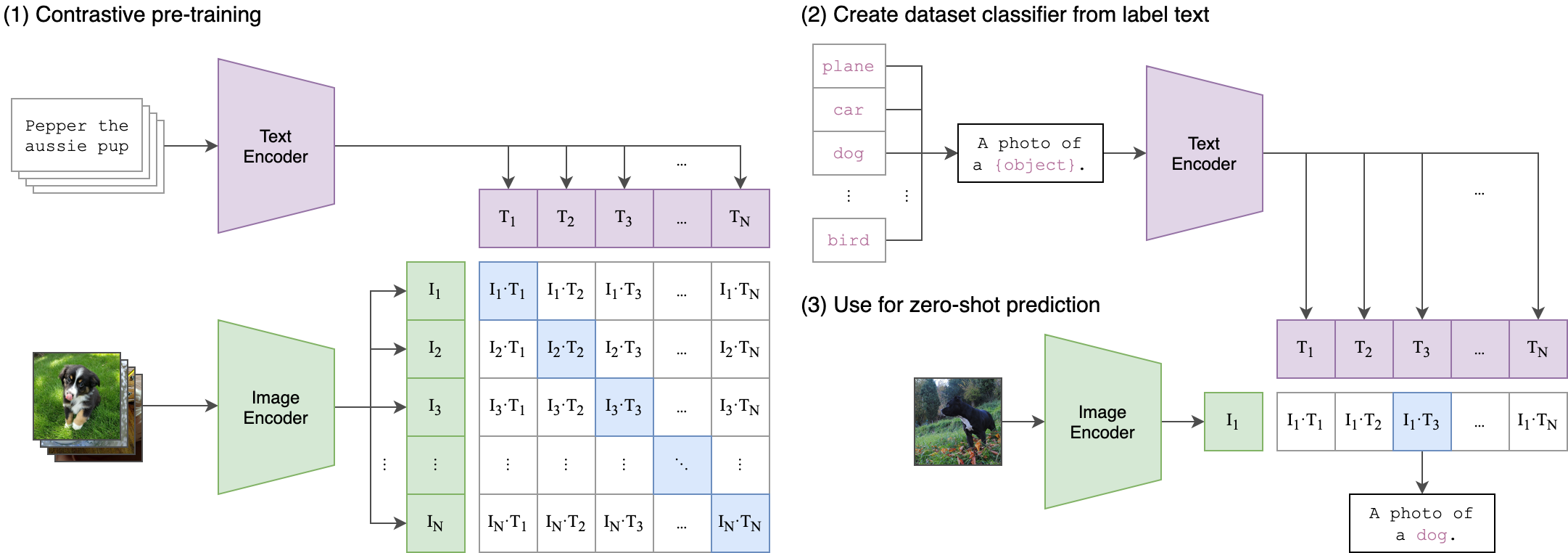
CLIP models in NeMo can be instantiated using the MegatronCLIPModel class.
Text Encoder#
CLIP uses a transformer-based text encoder to encode text features. The text input is tokenized and embedded. Positional embeddings are added to these token embeddings, and this combined representation is then passed through several transformer layers. The output from the last transformer layer corresponding to the first token is used as the text representation. In NeMo, the CLIP text encoder can be instantiated using the CLIPTextTransformer class.
Vision Model#
CLIP’s vision model is based on the Vision Transformer (ViT) architecture. The image is first divided into fixed-size patches (e.g., 16x16 pixels). These patches are linearly embedded into a flat vector, which is then used as input to the transformer. The output of the transformer is then pooled to produce a single image representation. In NeMo, the CLIP vision model can be instantiated using the CLIPVisionTransformer class.
Model |
Image size |
Image Model size (M) (Vision) |
Hidden size (FFN size) (Vision) |
Attention heads (Vision) |
Number of layers (Vision) |
Patch dim (Vision) |
Model size (M) (Text) |
Hidden size (Text) |
Attention heads (Text) |
Number of layers (Text) |
Output dim |
|---|---|---|---|---|---|---|---|---|---|---|---|
B/32 |
224 |
87.85 |
768 |
12 |
12 |
16 |
63.43 |
512 |
8 |
12 |
512 |
B/16 |
224 |
86.19 |
768 |
12 |
12 |
32 |
91.16 |
512 |
8 |
12 |
512 |
L/14 |
224 |
303.97 |
1024 |
16 |
24 |
14 |
123.65 |
768 |
12 |
12 |
768 |
H/14 |
224 |
638.08 |
1280 |
20 |
32 |
14 |
354.03 |
1024 |
16 |
24 |
1024 |
g/14 |
224 |
1012.65 |
1408 (6144) |
22 |
40 |
14 |
354.03 |
1024 |
16 |
24 |
1024 |
G/14 |
224 |
1840 |
1664 (8192) |
16 |
48 |
14 |
590 |
1280 |
20 |
32 |
1280 |
e/14 |
224 |
2200 |
1792 (15360) |
28 |
56 |
14 |
660 |
1280 |
20 |
36 |
1280 |
Model Configuration#
General Configuration#
model:
output_dim: 512
local_loss: False
gather_with_grad: True
output_dim: Represents the dimensionality of the output embeddings for both the text and vision models.local_loss: If set to True, the loss is calculated with local features at a global level, avoiding the need to realize the full global matrix. This can be beneficial for memory efficiency, especially when training on multiple devices.gather_with_grad: Enables full distributed gradient for feature gathering. Disabling this (setting to False) may cause convergence issues.
Vision Model Configuration#
vision:
patch_dim: 16
img_h: 224
img_w: 224
image_mean: null
image_std: null
num_channels: 3
drop_patch_rate: 0.0
drop_path_rate: 0.0
global_average_pool: False
output_dim: ${model.output_dim}
class_token_length: 8
encoder_seq_length: 196
num_layers: 12
hidden_size: 768
ffn_hidden_size: 3072
num_attention_heads: 12
hidden_dropout: 0.
attention_dropout: 0.
patch_dim: Size of the patches the image is divided into.img_handimg_w: Height and width of the input images.image_meanandimage_std: Mean and standard deviation values for image normalization.num_channels: Number of channels in the input image (e.g., 3 for RGB images).drop_patch_rateanddrop_path_rate: Dropout rates for patches and paths respectively.global_average_pool: If set to True, applies global average pooling to the output.class_token_length: Length of the extra classification tokens.encoder_seq_length: Sequence length for the vision encoder.num_layers,hidden_size,ffn_hidden_size,num_attention_heads: Parameters defining the architecture of the vision transformer. Theffn_hidden_sizeis typically 4 times thehidden_size.hidden_dropoutandattention_dropout: Dropout probabilities for the hidden state and attention in the transformer respectively.
Text Model Configuration#
text:
output_dim: ${model.output_dim}
encoder_seq_length: 77
num_layers: 12
hidden_size: 512
ffn_hidden_size: 2048
num_attention_heads: 8
hidden_dropout: 0.
attention_dropout: 0.
output_dim: Dimensionality of the output embeddings for the text model.encoder_seq_length: Sequence length for the text encoder.num_layers,hidden_size,ffn_hidden_size,num_attention_heads: Parameters defining the architecture of the text transformer. Theffn_hidden_sizeis typically 4 times thehidden_size.hidden_dropoutandattention_dropout: Dropout probabilities for the hidden state and attention in the transformer respectively.
Optimizations#
Feature |
Description |
To Enable |
|---|---|---|
Data parallelism |
Dataset is read concurrently across multiple GPUs or nodes, allowing for faster data loading and processing. |
Automatically when training on multi GPUs/nodes |
Tensor parallelism |
Each tensor is split up into multiple chunks, allowing for horizontal parallelism across GPUs. This technique, known as TensorParallel (TP), distributes the model’s tensors across multiple GPUs. During processing, each shard gets processed separately and in parallel on different GPUs, and the results are synced at the end of the step. This approach is inspired by NVIDIA’s Megatron implementation. [Reference](NVIDIA/Megatron-LM) |
|
Activation Checkpointing |
To reduce memory usage, activations of certain layers are cleared and recomputed during a backward pass. This technique is particularly useful for training large models that wouldn’t fit in GPU memory using traditional methods. |
|
Bfloat16 Training |
Training is conducted in Bfloat16 precision, which offers a balance between the higher precision of FP32 and the memory savings and speed of FP16. |
|
BF16 O2 |
Enables O2-level automatic mixed precision, optimizing Bfloat16 precision for better performance. |
|
Distributed Optimizer |
The optimization process is distributed across multiple GPUs, reducing memory requirements. This technique distributes the optimizer state across data parallel ranks, rather than replicating it, offering significant memory savings. This approach is inspired by the ZeRO optimization described in the paper “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” and implemented in NVIDIA’s Megatron. [Reference](NVIDIA/Megatron-LM) |
|
Flash Attention V2 |
FlashAttention is a fast and memory-efficient algorithm to compute exact attention. It speeds up model training and reduces memory requirement by being IO-aware. This approach is particularly useful for large-scale models and is detailed further in the repository linked. [Reference](Dao-AILab/flash-attention) |
|
Model Training#
Refer to https://laion.ai/blog/large-openclip/#results for community training recipe.
References#
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. 2021. arXiv:2103.00020.