FasterRCNN#
FasterRCNN is a public object detection model that is supported by NVIDIA TAO. FasterRCNN in TAO supports below tasks:
dataset_convert
train
evaluate
inference
prune
export
These tasks can be invoked from the TAO Launcher using the following convention on the command-line:
tao model faster_rcnn <sub_task> <args_per_subtask>
where, args_per_subtask are the command-line arguments required for a given subtask. Each
subtask is explained in detail in the following sections.
Preparing the Input Data Structure#
The dataset structure of FasterRCNN is identical to that of DetectNet_v2. The only difference is the command line used to generate the TFRecords from KITTI text labels. To generate TFRecords for FasterRCNN training, use this command:
tao model faster_rcnn dataset_convert [-h] -d <dataset_spec>
-o <output_tfrecords_file>
[--gpu_index <gpu_index>]
Required Arguments#
-d, --dataset_spec: path to the dataset specification file.-o, --output_filename: path to the output TFRecords file.
Optional Arguments#
--gpu_index: The GPU index to run this command on. We can specify the GPU index used to run this command if the machine has multiple GPUs installed. Note that this command can only run on a single GPU.
Creating a Configuration File#
The experiments specification (specification file for short) defines all the necessary parameters required to
in the entire workflow of a FasterRCNN model, from training to export. Below is a sample of the
FasterRCNN specification file. The format of the specification file is a protobuf text (prototxt) message and each of
its fields can be either a basic data type or a nested proto message. The top level structure of the
specification file is summarized in the table below. From the table, we can see the specification file has 9 components:
random_seed, verbose, enc_key, dataset_config, augmentation_config,
model_config, training_config, inference_config and evaluation_config.
Here’s a sample of the FasterRCNN specification file:
random_seed: 42
enc_key: 'nvidia_tlt'
verbose: True
model_config {
input_image_config {
image_type: RGB
image_channel_order: 'bgr'
size_height_width {
height: 384
width: 1248
}
image_channel_mean {
key: 'b'
value: 103.939
}
image_channel_mean {
key: 'g'
value: 116.779
}
image_channel_mean {
key: 'r'
value: 123.68
}
image_scaling_factor: 1.0
max_objects_num_per_image: 100
}
arch: "resnet:18"
anchor_box_config {
scale: 64.0
scale: 128.0
scale: 256.0
ratio: 1.0
ratio: 0.5
ratio: 2.0
}
freeze_bn: True
freeze_blocks: 0
freeze_blocks: 1
roi_mini_batch: 256
rpn_stride: 16
use_bias: False
roi_pooling_config {
pool_size: 7
pool_size_2x: False
}
all_projections: True
use_pooling:False
}
dataset_config {
data_sources: {
tfrecords_path: "/workspace/tao-experiments/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tao-experiments/data/training"
}
image_extension: 'png'
target_class_mapping {
key: 'car'
value: 'car'
}
target_class_mapping {
key: 'van'
value: 'car'
}
target_class_mapping {
key: 'pedestrian'
value: 'person'
}
target_class_mapping {
key: 'person_sitting'
value: 'person'
}
target_class_mapping {
key: 'cyclist'
value: 'cyclist'
}
validation_fold: 0
}
augmentation_config {
preprocessing {
output_image_width: 1248
output_image_height: 384
output_image_channel: 3
min_bbox_width: 1.0
min_bbox_height: 1.0
}
spatial_augmentation {
hflip_probability: 0.5
vflip_probability: 0.0
zoom_min: 1.0
zoom_max: 1.0
translate_max_x: 0
translate_max_y: 0
}
color_augmentation {
hue_rotation_max: 0.0
saturation_shift_max: 0.0
contrast_scale_max: 0.0
contrast_center: 0.5
}
}
training_config {
enable_augmentation: True
enable_qat: False
batch_size_per_gpu: 8
num_epochs: 12
retrain_pruned_model: "/workspace/tao-experiments/data/faster_rcnn/model_1_pruned.tlt"
rpn_min_overlap: 0.3
rpn_max_overlap: 0.7
classifier_min_overlap: 0.0
classifier_max_overlap: 0.5
gt_as_roi: False
std_scaling: 1.0
classifier_regr_std {
key: 'x'
value: 10.0
}
classifier_regr_std {
key: 'y'
value: 10.0
}
classifier_regr_std {
key: 'w'
value: 5.0
}
classifier_regr_std {
key: 'h'
value: 5.0
}
rpn_mini_batch: 256
rpn_pre_nms_top_N: 12000
rpn_nms_max_boxes: 2000
rpn_nms_overlap_threshold: 0.7
regularizer {
type: L2
weight: 1e-4
}
optimizer {
sgd {
lr: 0.02
momentum: 0.9
decay: 0.0
nesterov: False
}
}
learning_rate {
soft_start {
base_lr: 0.02
start_lr: 0.002
soft_start: 0.1
annealing_points: 0.8
annealing_points: 0.9
annealing_divider: 10.0
}
}
lambda_rpn_regr: 1.0
lambda_rpn_class: 1.0
lambda_cls_regr: 1.0
lambda_cls_class: 1.0
}
inference_config {
images_dir: '/workspace/tao-experiments/data/testing/image_2'
model: '/workspace/tao-experiments/data/faster_rcnn/frcnn_kitti_resnet18_retrain.epoch12.tlt'
batch_size: 1
detection_image_output_dir: '/workspace/tao-experiments/data/faster_rcnn/inference_results_imgs_retrain'
labels_dump_dir: '/workspace/tao-experiments/data/faster_rcnn/inference_dump_labels_retrain'
rpn_pre_nms_top_N: 6000
rpn_nms_max_boxes: 300
rpn_nms_overlap_threshold: 0.7
object_confidence_thres: 0.0001
bbox_visualize_threshold: 0.6
classifier_nms_max_boxes: 100
classifier_nms_overlap_threshold: 0.3
}
evaluation_config {
model: '/workspace/tao-experiments/data/faster_rcnn/frcnn_kitti_resnet18_retrain.epoch12.tlt'
batch_size: 1
validation_period_during_training: 1
rpn_pre_nms_top_N: 6000
rpn_nms_max_boxes: 300
rpn_nms_overlap_threshold: 0.7
classifier_nms_max_boxes: 100
classifier_nms_overlap_threshold: 0.3
object_confidence_thres: 0.0001
use_voc07_11point_metric:False
gt_matching_iou_threshold: 0.5
}
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The random seed for the experiment. |
Unsigned int |
|
|
The encoding and decoding key for the TAO models, can be overridden by the command
line arguments of |
Str, should not be empty |
– |
|
Controls the logging level during the experiments. Will print more logs if True. |
Boolean(True or False) |
|
|
The configurations of the dataset, this is the same as |
proto message |
– |
|
The configuration of the data augmentation, same as DetectNet_v2. |
proto message |
– |
|
The configuration of the model architecture. |
proto message |
– |
|
The configurations for doing training with the model. |
proto message |
– |
|
The configuration for doing inference with the model. |
proto message |
– |
|
The configuration for doing evaluation with the model. |
proto message |
– |
Dataset#
The dataset_config defines the dataset of a FasterRCNN experiments (including training dataset and validation dataset).
The definition of FasterRCNN dataset is identical to that of DetectNet_v2. Check the DetectNet_v2
dataset_config documentation for the details of this parameter.
Data augmentation#
The augmentation_config defines the data augmentation during the training of a FasterRCNN
model. The definition of FasterRCNN data augmentation is identical to that of DetectNet_v2.
Check the DetectNet_v2 augmentation_config documentation for the details of this parameter.
Model architecture#
The model_config defines the FasterRCNN model architecture. In this parameter, we can choose
the backbone of the FasterRCNN model, enabling BatchNormalization layers or not, whether or not to
freeze the BatchNormalization layers during training, and whether or not to freeze some blocks in the model
during training. With this parameter, we can define a specialized FasterRCNN model
architecture from the general FasterRCNN application, according to the use cases. Detailed
description of this parameter is summarized in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
Defines the input image format, including the image channel number, channel order, width and height, and the preprocessings (subtract per-channel mean and divided by a scaling factor) for it before feeding input the model. See below for details. |
proto message |
– |
|
The feature extractor (backbone) for the FasterRCNN model. FasterRCNN supports 14 backbones. |
str type. The architecture can be ResNet, VGG , GoogLeNet, MobileNet or DarkNet. For each specific architecture, it can have different layers or versions. Details listed below. ResNet series: resnet:10, resnet:18, resnet:34, resnet:50, resnet:101 VGG series: vgg:16, vgg:19 GoogLeNet: googlenet MobileNet series: mobilenet_v1, mobilenet_v2 DarkNet: darknet:19, darknet:53 EfficientNet: efficientnet:b0, efficientnet:b1 Here a notational convention can be used, i.e., for models that can have different numbers of layers, use a colon followed by the layer number as the suffix of the model name. E.g., resnet:<layer_number> |
– |
|
Configurations of the anchor boxes. |
proto message. |
– |
|
The batch size of ROIs for training the RCNN. |
int. |
|
|
Cumulative stride from model input to RPN. This value is fixed (16) in current implementation. |
int. |
|
|
A flag to freeze all the BatchNormalization layers in the model. Freezing a BatchNormalization layer means freezing its moving mean and moving variance while its gamma and beta parameters are still trainable. This is usually used in FasterRCNN training with a small batch size so the moving means and moving variances are initialized from the pretrained model and fixed during training. |
Boolean. |
|
|
The dropout rate is applicable to the Dropout layers in the model(if there are any). Currently only VGG 16/19 and EfficientNet has Dropout layers. |
float. In the interval (0, 1). |
|
|
The drop_connect rate for EfficientNet. |
float. In the interval (0, 1). |
|
|
The list of block IDs to freeze during training. Some times we want to freeze some blocks in the model after loading the pretrained models for some reason (save GPU memory, make training process more stable, etc.). |
list of ints. For ResNet, the valid block IDs for freezing is any subset of {0, 1, 2, 3}(inclusive). For VGG, the valid block IDs for freezing is any subset of {1, 2, 3, 4, 5}(inclusive). For GoogLeNet, the valid block IDs for freezing is any subset of {0, 1, 2, 3, 4, 5, 6, 7} (inclusive). For MobileNet V1, the valid block IDs is any subset of {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11}(inclusive). For MobileNet V2, the valid block IDs is any subset of {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13}(inclusive). For DarkNet, the valid blocks IDs is any subset of {0, 1, 2, 3, 4, 5}(inclusive). For EfficientNet, the valid block IDs is any subset of { 0, 1, 2, 3, 4, 5, 6, 7}(inclusive). |
leave it unspecified. |
|
A flag to use bias for convlutional layers in the model. If the model has BatchNormalization layers, we usually set it to False. |
Boolean. |
|
|
The configuration for the ROIPooling (CropAndResize) layer in the model. |
proto message. |
– |
|
A flag to replace all the shortcut layers with projection layers in the model. Only valid for ResNet and MobileNet V2. |
Boolean. |
|
|
A flag to use pooling layers in the model or not. This parameter is valid only for VGG and ResNet. If set to True, pooling layers will be used in the model(produces the same model structures as in papers). Otherwise, strided convlutional layers will be used and pooling layers will be omitted. |
Boolean. |
|
|
Defines the activation function used in the model. Only valid for EfficientNet. For INT8 deployment, EfficientNet with relu activation will produces much better accuracy (mAP) than the original swish activation. |
proto message. |
– |
Each of the above proto message parameters will be described in detail below.
Input image configurations#
The input_image_config defines the supported format of images by FasterRCNN model. We can
customize the input image size, the per-channel mean values and scaling factor for image preprocessing.
We can also specify the image type (RGB or grayscale) for our training/validation dataset, and the order of
the channel if we are going to use RGB images during training. This is described in the table
below in detail.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The type of the images in the dataset. |
enum type, either |
|
|
Specify the input image’s smaller side size,
exclusive with |
proto message with only one |
– |
|
Specify the input image’s height and width,
exclusive with |
proto message with two parameters: |
– |
|
The image channel order. |
str type. Can be |
– |
|
Per-channel mean values for the input images. |
proto dict that maps each channel to its mean values. |
– |
|
The image scaling factor to scale the images. Each pixel value will be divided by this number. |
float. |
|
|
The maximum number of objects of an image in the dataset. |
int. |
|
Note
The maximum number of objects in an image depends on the dataset. It is
important to set the parameter max_objects_num_per_image to be no less than this number.
Otherwise, training will fail.
Anchor boxes#
The parameter anchor_box_config defines the anchor box sizes and aspect ratios in the
FasterRCNN model. There are two sub-parameters for it: scale and ratio. Each of
them is a list of floats as below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
Anchor box scales (sizes) in pixel. |
list of floats. |
– |
|
Aspect ratios of the anchor boxes. |
list of floats. |
– |
ROIPooling(CropAndResize)#
The roi_pooling_config parameter defines the parameters required in ROIPooling(CropAndResize)
layer in the model. Described in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The output spatial size (height and width) of the pooled ROIs. Only square ROIs are supported, so this parameter is for both height and width. |
int. |
|
|
A flag to double the pooled ROIs’ size. If this is set to True. CropAndResize will produces ROIs of size 2*pool_size and in RCNN it will be downsampled 2x to get back to pool_size. |
Boolean. |
– |
Activation function#
The parameter activation defines the type and parameter for the activation function in
a FasterRCNN model. This parameter is only valid for EfficientNet.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
Type of the activation function. Only |
str. |
– |
Training configurations#
The proto message training_config defines all the necessary parameters required for
a FasterRCNN training experiment. Each parameter is described in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
A flag to enable data augmentation in training. |
Boolean. |
|
|
The path to the pretrained weights for initializing the FasterRCNN model. |
str. |
– |
|
The path to the pruned model that we are going to retrain. |
str. |
– |
|
The path to the model for which that we are going to resume an interrupted training. |
str. |
– |
|
The lower IoU threshold used to match anchor boxes to groundtruth boxes. If the IoU of an anchor box and any groundtruth box is below this threshold, then this anchor box will be regarded as an negative anchor box. |
float. In the interval (0, 1). |
|
|
The higher IoU threshold used to match anchor boxes to groundtruth boxes. If the IoU of an anchor box and some groundtruth box is higher this threshold, then this anchor box will be regarded as an positive anchor box. |
float. In the interval (0, 1). |
|
|
The lower IoU threshold used to generate the proposal target. If the IoU of a ROI and a groundtruth box is above this number and below classifier_max_overlap, then this ROI is regarded as a negative ROI (background) during training. |
float. In the interval (0, 1). |
|
|
The higher IoU threshold used to generate the proposal target. If the IoU of a ROI and a groundtruth box is above this number, then this ROI is regarded as a positive ROI during training. |
float. In the interval (0, 1). |
|
|
A flag to include groundtruth boxes in the positive ROIs for training the RCNN. |
Boolean. |
|
|
A scaling factor (multiplier) for RPN regression loss. |
float. |
|
|
Scaling factors (denominators) for the RCNN regression loss. A map from ‘x’, ‘y’, ‘w’, ‘h’ to its corresponding scaling factor, respectively. |
proto dict. |
|
|
Training batch size per GPU. |
int. |
– |
|
Number of epochs for the training. |
int. |
|
|
The period in epochs that we will save the checkpoint. Setting this number to be greater than num_epochs will essentially disable checkpointing. |
int. |
|
|
The number of boxes (ROIs) to be retained before the NMS in Proposal layer. |
int. |
– |
|
The maximum number of boxes (ROIs) to be retained after the NMS in Proposal layer. |
int. |
– |
|
The IoU threshold for NMS in Proposal layer. |
float. In the interval (0, 1). |
|
|
The configuration for regularizer. |
proto message. |
– |
|
The configuration for optimizer. |
proto message. |
– |
|
The configuration for learning rate scheduler. |
proto message. |
– |
|
Weighting factor for RPN regression loss. |
float. |
|
|
Weighting factor for RPN classification loss. |
float. |
|
|
Weighting factor for RCNN regression loss. |
float. |
|
|
Weighting factor for RCNN classification loss. |
float. |
|
|
A flag to enable QAT (quantization-aware training). FasterRCNN does not support loading a non-QAT pruned model and retraining with QAT enabled. |
Boolean. |
|
|
List of fraction for model parallelism. Each
number is a fraction that represents the percentage
of model layers to be placed on a GPU. For example
two repeated |
repeated float |
– |
|
Visualization configuration during training. |
proto message |
– |
|
The parameters for early stopping. |
proto message |
– |
The description for proto messages are summarized further below.
Regularizer#
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The type of the regularizer. |
enum type. |
– |
|
The penalty of the regularizer. |
float. |
– |
Optimizer#
Three types of optimizers are supported by FasterRCNN: Adam, SGD and RMSProp. Only one of them
should be specified in specification file. No matter which one is chosen, it will be wrapped in a optimizer
proto. For example:
optimizer {
adam {
lr: 0.00001
beta_1: 0.9
beta_2: 0.999
decay: 0.0
}
}
The Adam optimizer parameters are summarized in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
learning rate. This is actually overridden by the learning rate scheduler and hence not useful. |
float. |
|
|
Momentum for the means of the model parameters. |
float. |
|
|
Momentum for the variances of the model parameters. |
float. |
|
|
decay factor for the learning rate. Not useful |
float. |
|
The SGD optimizer parameters are summarized in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
learning rate. Not useful as the learning rate is overridden by the learning rate scheduler. |
float. |
|
|
Momentum of SGD. |
float. |
|
|
decay factor of the learning rate. Not useful as overridden by learning rate scheduler. |
float. |
|
|
A flag to enable Nesterov momentum for SGD. |
Boolean. |
|
The RMSProp optimizer parameters are summarized in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
learning rate. Not useful as learning rate is overridden by learning rate scheduler. |
float. |
|
Learning rate scheduler#
The parameter learning_rate defines the learning rate scheduler in a FasterRCNN training.
Two types of learning rate schedulers are supported in FasterRCNN: soft_start and
step. NO matter which one is chosen, it will be wrapped in a learning_rate proto message.
For example:
learning_rate {
step {
base_lr: 0.00001
gamma: 1.0
step_size: 30
}
}
The parameters of soft_start scheduler is described in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
Maximum learning rate during the training. |
float. |
– |
|
The initial learning rate at the start of the training. |
float. Smaller than |
– |
|
The duration (in percentage of total epochs) of the soft start phase of the learning rate curve. |
float. In the interval (0, 1). |
– |
|
List of time points at which to decrease the learning rate. Also in percentage. |
list of floats. |
– |
|
divider to decrease the learning rate at each of annealing_points. |
float. |
– |
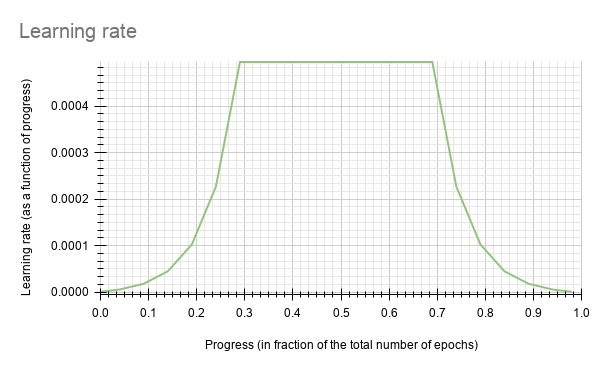
The parameters of step scheduler is described in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
base learning rate at the start of training. |
float. |
– |
|
multiplier to decrease learning rate. |
float. |
– |
|
the step size (in percentage of total epochs) at which the learning rate is multiplied by gamma. |
float. |
– |
Note
The learning rate is automatically scaled with the number of GPUs used during training, or the effective learning rate is learning_rate * n_gpu.
Visualization during training#
Visualization during training is configured by the visualizer parameter. The parameters of it are described in the table
below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
Boolean flag to enable or disable this feature |
bool. |
– |
|
The maximum number of images to be visualized in TensorBoard. |
int. |
|
Visualization during training supports 3 types of visualizations, namely: scalar, image and histogram. These types of visualization all leverage the TensorBoard tool. Each type will have a tab in TensorBoard GUI interface. With the scalar tab, it can visualize scalars like loss, learning rate and validation mAP over time(training step). With the image tab, it can visualize augmented images during training, with bounding boxes drawn on the them. With the histogram tab, it can visualize histograms of each layer’s weights and bias of the model being trained.
If the parameter enabled is set to True, then all above visualizations will be enabled.
Otherwise, all visualization will be disabled.
The parameter num_images is used to limit the maximum number of images to be visualized on
the image tab in TensorBoard.
During the training, visualization can be done anywhere that can access the TensorBoard log directory.
Usually the TAO containers will map volumes to host machine, so TensorBoard can be called on host machine.
The command tensorboard --logdir=/path/to/logs can be used to open the TensorBoard
visualization GUI in web browser. Make sure tensorboard is installed before running this command.
One can run pip3 install tensorboard to install it if it is not installed in the environment.
The /path/to/logs argument is the path to the directory used to save the .tlt model,
with the suffix /logs appended.
Early Stopping#
The parameters for early stopping are described in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The metric to monitor in order to enable early stopping. |
string |
|
|
The number of checks of |
int |
Positive integers |
|
The delta of the minimum value of |
float |
Non-negative floats |
Inference configurations#
The parameter inference_config defines all the parameters required for running inference
against a FasterRCNN model.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
The path to the directory of images to run inference on. |
str. |
– |
|
Path to the |
str. |
– |
|
Batch size for running inference. |
int. |
|
|
The number of boxes (ROIs) to be retained before the NMS in Proposal layer in inference. |
int. |
– |
|
The maximum number of boxes (ROIs) to be retained after the NMS in Proposal layer in inference. |
int. |
– |
|
The IoU threshold for NMS in Proposal layer. |
float. In the interval (0, 1). |
|
|
Object confidence score threshold in NMS. All the objects whose confidence is lower than this number will filtered out in NMS. |
float. In the interval (0, 1). |
|
|
The maximum number of boxes to retain in RCNN NMS. |
int. |
|
|
RCNN NMS IoU threshold. |
float. In the interval (0, 1). |
|
|
Output directory for detection images. |
str. |
– |
|
A flag to display the class name and confidence for each detected object in an image. |
Boolean. |
|
|
Output directory to save the labels of the detected objects. |
str. |
– |
|
The configurations for TensorRT based inference.
If this parameter is set, inference will use
TensorRT engine instead of |
proto message. |
– |
|
The number of bits to represent the score values in NMS plugin in TensorRT OSS. The valid range is integers in [1, 10]. Setting it to any other values will make it fall back to ordinary NMS. Currently this optimized NMS plugin is only available in FP16 but it should also be selected by INT8 data type as there is no INT8 NMS in TensorRT OSS and hence this fastest implementation in FP16 will be selected. If falling back to ordinary NMS, the actual data type when building the engine will decide the exact precision(FP16 or FP32) to run at. |
int. In the interval [1, 10]. |
|
TensorRT based inference#
The parameter trt_inference defines all the parameters for TensorRT based inference.
When specified, Inference will use TensorRT engine instead of the .tlt model.
The TensorRT engine is assumed to be generated by the tao-converter tool.
All the parameters are summarized in the table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
Path to the TensorRT engine file to load. |
str. |
– |
Note
The parameter trt_inference is deprecated. The parameter model can now
support either a .tlt model or a TensorRT engine(any path that does not end with
.tlt extension).
Evaluation configurations#
The parameter evaluation_config defines all the required parameters for running evaluation
against a FasterRCNN model. This parameter is very similar to inference_config.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
Path to the model to run evaluation.
Can be either a |
str. |
– |
|
Batch size for running inference. |
int. |
|
|
The number of boxes(ROIs) to be retained before the NMS in Proposal layer in evaluation. |
int. |
– |
|
The maximum number of boxes(ROIs) to be retained after the NMS in Proposal layer in evaluation. |
int. |
– |
|
The IoU threshold for NMS in Proposal layer. |
float. In the interval (0, 1). |
|
|
Object confidence score threshold in NMS. All the objects whose confidence is lower than this number will filtered out in NMS. |
float. In the interval (0, 1). |
|
|
The maximum number of boxes to retain in RCNN NMS. |
int. |
|
|
RCNN NMS IoU threshold. |
float. In the interval (0, 1). |
|
|
A flag to use PASCAL VOC 2007 11-point AP metric. |
Boolean. |
– |
|
The period(in epochs) for doing validation during training. |
int. |
|
|
The configurations for TensorRT based evaluation.
If this parameter is set, evaluation will use
TensorRT engine instead of |
proto message. |
– |
|
IoU threshold to match detected boxes with groundtruth boxes. Exclusive with gt_matching_iou_threshold_range below. |
float. |
|
|
Range of IoU thresholds for computing AP at multiple IoU thresholds and computing COCO mAP. Exclusive with gt_matching_iou_threshold above. |
proto message. |
– |
|
Boolean flag to enable or disable visualization of Precision-Recall curve. |
bool. |
– |
Note
The parameter visualize_pr_curve, if set to True, will produce an image of precision-recall curve during the
evaluate command, the exact path of the image can be seen in the screen log. By checking the image, we can see each class’s performance
regarding the tradeoff between precision and recall.
TensorRT based evaluation#
In the above table, the definition of trt_evaluation is the same as trt_inference
parameter described before.
Note
The parameter trt_evaluation is deprecated. The parameter model can now
support either a .tlt model or a TensorRT engine(any path that does not end with
.tlt extension).
Evaluation IoU Range#
The gt_matching_iou_threshold_range parameter is described in table below.
Parameter |
Description |
Data Type and Constraints |
Default/Suggested Value |
|
start point of the IoU list(inclusive). |
float. In the interval (0, 1). |
|
|
step size of the IoU list. |
float. In the interval (0, 1). |
|
|
end point of the IoU list(exclusive). |
float. In the interval (0, 1]. |
|
Training the model#
To run training of a FasterRCNN model, use this command:
tao model faster_rcnn train [-h] -e <experiment_spec> -r <results_dir>
[-k <enc_key>]
[--gpus <num_gpus>]
[--num_processes <number_of_processes>]
[--gpu_index <gpu_index>]
[--use_amp]
[--log_file <log_file_path>]
Required Arguments#
-e, --experiment_spec_file: Experiment specification file to set up the evaluation experiment. This should be the same as training specification file.-r, --results_dir: Output directory of the training experiment.
Optional Arguments#
-h, --help: Show this help message and exit.-k, --enc_key: TAO encoding key, can override the one in the specification file.--gpus: The number of GPUs to be used in the training in a multi-GPU scenario (default: 1).--num_processes, -np: Number of processes to be spawned for training. It defaults to be -1(equal to--gpus, for the use case of data parallelism). In the case of model parallelism, this argument should be explicitly set to 1 or more, depending on the actual scenario. Setting--gpusto be larger than 1 and--num_processesto 1 corresponding to the model parallelism use case; while setting both--gpusandnum_processesto be larger than 1 corresponding to the case of enabling both model parallelism and data parallelism. For example,--gpus=4and--num_processes=2means 2 horovod processes will be spawned and each of them will occupy 2 GPUs for model parallelism.--gpu_index: The GPU indices used to run the training. We can specify the GPU indices used to run training when the machine has multiple GPUs installed.--use_amp: A flag to enable AMP training.--log_file: Path to the log file. Defaults to stdout.
Input Requirement#
Input size: C * W * H (where C = 1 or 3, W >= 128, H >= 128)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
Sample Usage#
Here’s an example of using the FasterRCNN training command:
tao model faster_rcnn train --gpu_index 0 -e <experiment_spec> -r <results_dir>
Using a Pretrained Model#
Usually, using a pretrained model (weights) file for the initial training of FasterRCNN helps get better accuracy. NVIDIA recommends using the pretrained weights provided in NVIDIA GPU Cloud (NGC). FasterRCNN loads the pretrained weights by name. That is, layer by layer, if TAO finds a layer whose name and weights (bias) shape in the pretrained weights file matches a layer in the TAO model, it will load that layer’s weights (and bias, if any) into the model. If some layer in the TAO cannot find a matching layer in the pretrained weights, then TAO will skip that layer and will use random initialization for that layer instead. An exception is that if TAO finds a matching layer in the pretrained weights (and bias, if any) but the shape of the pretrained weights (or bias, if any) in that layer does not match the shape of weights (bias) for the corresponding layer in a TAO model, it will also skip that layer.
For some layers that have no weights (bias), nothing will be done for it(hence will be skipped). So, in total, there are three possible statuses to indicate how a layer’s pretrained weights loading is going on:
"Yes"means a layer has weights (bias) and is loaded from the pretrained weights file successfully for initialization."No"means a layer has weights (bias) but due to mismatched weights (bias) shape(or probably something else), the weights (bias) cannot be loaded successfully and will use random initialization instead."None"means a layer has no weights (bias) at all and will not load any weights. In the FasterRCNN training log, there is a table that shows the pretrained weights loading status for each layer in the model.
To use a pretrained model in FasterRCNN training, set the pretrained_weights path to point
to a pretrained .tlt model (generated with the same encryption key as the FasterRCNN training),
a Keras .hdf5 model or a Keras .h5 weights.
Note
At the start of the training, FasterRCNN will print the pretrained model loading status (per-layer). If facing with bad mAP with the model, we can double check this log to see if the pretrained model is loaded properly or not.
Note
FasterRCNN does not support loading a non-QAT pruned model and retraining it with QAT enabled. To make the retrained model a QAT model, it is required to do the initial training with QAT enabled too.
Re-training a pruned model#
A FasterRCNN model can be retrained one or more times. The typical use case is retraining for a pruned
model. To retrain an existing FasterRCNN model, set the retrain_pruned_model path to point to
an existing FasterRCNN model.
Resuming an interrupted training#
Sometimes a training job can be interrupted due to some reason (e.g., system crash). In these cases,
there is no need to redo the training from the start. We can resume the interrupted training
from the last checkpoint(saved .tlt model during training). In this case, set the
resume_from_model path in specification file to point to the last checkpoint and re-run the training
to resume the job.
Input shape: static and dynamic#
FasterRCNN training can support both static input shape and dynamic input shape. Static input shape
means the input’s width and height are constant numbers like 960 x 544. Static shape is the most
commonly used case in practice. To enable static input shape, we should specify it in
input_image_config and augmentation_config. We should use size_height_width
in input_image_config to specify the input height and width. Again, we should specify the
same two numbers in augmentation_config. That is, we specify the
output_image_height and output_image_width in augmentation_config.
With static input shape, we can offline resize the images to the target resolution or we can enable
automatic resize during training. By setting enable_auto_resize in augmentation_config
to True we will enable automatic resize during training. Automatic resize will reduce the
effort to manually resize the images each time we want to train the model on a different resolution.
But since resize happens during training, it will potentially increase the training time.
Users should make this tradeoff between offline resize and automatic(online) resize.
Dynamic input shape means the input’s height and width are not a constant number but rather can
change during training for different images. This kind of input shape is originally proposed in
the literature(such as in FasterRCNN paper) where we resize the image and keep aspect ratio such that
the resultant image’s smaller side is a given number. Besides the limit on smaller side, we also have
a limit on the larger side. If we resize and keep aspect ratio but the resultant image’s larger side’s
size exceed this limit on larger side, then we will resize and keep aspect ratio such that the larger
side’s size is a given number. In that case, the smaller side will be also no more than its limit.
FasterRCNN can support this kind of dynamic input shape. To enable this feature, we have to
specify size_min in input_image_config and specify output_image_min and
output_image_max in augmentation_confg. size_min and output_image_min
indicates the limit of the smaller side’s size, while output_image_max indicates the limit on
the larger side’s size.
Note that there are some limitations regarding the dynamic shape of FasterRCNN.
TAO FasterRCNN training/evaluation/inference can only work with batch size 1.
TAO FasterRCNN export & DeepStream(TensorRT) inference/evaluation does not support dynamic shape for now.
Model parallelism#
FasterRCNN supports model parallelism. Model parallelism is a technique that we split the entire model
on multiple GPUs and each GPU will hold a part of the model. A model is split by layers. For example,
if a model has 100 layers, then we can place the layer 0-49 on GPU 0 and layer 50-99 on GPU 1.
Model parallelism will be useful when the model is huge and cannot fit into a single GPU even with
batch size 1. Model parallelism is also useful if we want to increase the batch size that is seen
by BatchNormalization layers and hence potentially improve the accuracy. This feature can be enabled
by setting model_parallelism in training_config. For example,
model_parallelism: 0.3
model_parallelism: 0.7
will enable a 2-GPU model parallelism where the first GPU will hold 30% of the model layers and the second GPU will hold 70% of the model layers. The percentage of model layers can be adjusted with some trial-and-error so all GPUs consumes almost the same GPU memory size and in that case we can use the largest batch size for this model-parallelised training.
Model parallelism can be enabled jointly with data parallelism. For example, in above case we enabled a 2-GPU model parallelism, at the same time we can also enable 4 horovod processes for it. In this case, we have 4 horovod processes for data parallelism and each process will have the model split on 2 GPUs.
Evaluating the model#
To run evaluation for a faster_rcnn model, use this command:
tao model faster_rcnn evaluate [-h] -e <experiment_spec>
[-k <enc_key>]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
[-m <model_path>]
Required Arguments#
-e, --experiment_spec_file: Experiment specification file to set up the evaluation experiment. This should be the same as a training specification file.
Optional Arguments#
-h, --help: show this help message and exit.-k, --enc_key:The encoding key, can override the one in the specification file.--gpu_index: The GPU index used to run the evaluation. We can specify the GPU index used to run evaluation when the machine has multiple GPUs installed. Note that evaluation can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.-m, --model: Path to the model to run evaluation. The model can be either a.tltmodel or a TensorRT engine(any path that does not end with.tltextension). The model path(if provided in the command line here) will override theevaluation_config.modelin the specification file.
Evaluation Metrics#
The PASCAL VOC 2007 vs 2012 metrics#
For FasterRCNN, the evaluation will produce 4 metrics for the evaluated model:
AP (average precision), precision, recall and RPN_recall for each class in the evaluation dataset.
inally, it will also print the mAP (mean average precision) as a single metric number. Two
modes are supported for computing the AP, i.e., the PASCAL VOC 2007 and 2012 metrics. This
can be configured in the specification file’s evaluation_config.use_voc_11_point_metric parameter.
If this parameter is set to True, then AP calculation will use VOC 2007 method, otherwise it will
use the VOC 2012 method.
Setting IoU value/range for computing AP/mAP#
For matching the detected objects to groundtruth objects, we can define different IoU thresholds.
An IoU of 0.5 is used in PASCAL VOC metrics, while in MS COCO a list of IoUs are used to compute the AP.
For example, in MS COCO, the mAP@[0.5:0.05:0.95] is the averaged AP at 10 different IoUs, starting from 0.5
and ends with 0.95, with a step size of 0.05. TAO FasterRCNN supports evaluating AP at a list of IoUs
and computing the mAP across the range of IoUs. Specifically, setting gt_matching_iou_threshold
in evaluation_config will produce the AP/mAP at a single IoU; setting gt_matching_iou_threshold_range
for a list (range) of IoUs will produce AP at these IoU values and the mAP. In order to compute PASCAL VOC
mAP, we can set the former to 0.5. While in order to compute COCO mAP, we can set the latter to be
start: 0.5, step: 0.05 and end: 1.0.
The RPN_recall metric indicates the recall capability of the RPN of the FasterRCNN model. The higher the RPN_recall metric, it means RPN can better detect an object as foreground (but it doesn’t say anything on which class this object belongs to since that is delegated to RCNN). The RPN_recall metric is mainly used for debugging on the accuracy issue of a FasterRCNN model.
Running inference on the model#
The inference tool for FasterRCNN networks can be used to visualize bboxes or generate frame by frame KITTI format labels on a directory of images. You can execute this tool from the command line as shown here:
tao model faster_rcnn inference [-h] -e <experiment_spec>
[-k <enc_key>]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
[-m <model_path>]
Required Arguments#
-e, --experiment_spec_file: Path to the experiment specification file for FasterRCNN training.
Optional Arguments#
-h, --help: Print help log and exit.-k, --enc_key: The encoding key, can override the one in the specification file.--gpu_index: The GPU index to run inference on. We can specify the GPU index used to run inference if the machine has multiple GPUs installed. Note that inference can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.-m, --model: The path to the model to be used for inference. The model can be either a.tltmodel or a TensorRT engine(any path that does not end with the.tltextension). The model path(if provided in the command line here) will override theinference_config.modelin the specification file.
Pruning the model#
Pruning removes parameters from the model to reduce the model size without compromising the
integrity of the model itself using the tao model faster_rcnn prune command.
The tao model faster_rcnn prune command includes these parameters:
tao model faster_rcnn prune [-h] -m <model>
-o <output_file>
-k <key>
[-n <normalizer>]
[-eq <equalization_criterion>]
[-pg <pruning_granularity>]
[-pth <pruning threshold>]
[-nf <min_num_filters>]
[-el [<excluded_list>]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments#
-m, --model: Path to a pretrained.tltmodel to be pruned.-o, --output_file: Path to save the pruned.tltmodel.-k, --ke: Key to load a :code`.tlt` model.
Optional Arguments#
-h, --help: Show this help message and exit.-n, –normalizer:maxto normalize by dividing each norm by the maximum norm within a layer;L2to normalize by dividing by the L2 norm of the vector comprising all kernel norms. (default: max)-eq, --equalization_criterion: Criteria to equalize the stats of inputs to an element wise op layer or depth-wise convolutional layer. This parameter is useful for resnets and mobilenets. Options arearithmetic_mean,geometric_mean,union, andintersection. (default:union)-pg, -pruning_granularity: Number of filters to remove at a time (default:8)-pth: Threshold to compare normalized norm against (default:0.1)Note
NVIDIA recommends changing the threshold to keep the number of parameters in the model to within 10-20% of the original unpruned model.
-nf, --min_num_filters: Minimum number of filters to keep per layer (default:16)-el, --excluded_layers: List of excluded_layers. Examples: -i item1 item2 (default: [])--gpu_index: The GPU index to run pruning on. We can specify the GPU index used to run pruning if the machine has multiple GPUs installed. Note that pruning can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.
After pruning, the model needs to be retrained. See Re-training the Pruned Model for more details.
Using the Prune Command#
Here’s an example of using the tao model faster_rcnn prune command:
tao model faster_rcnn prune -m /workspace/output/weights/resnet_003.tlt
-o /workspace/output/weights/resnet_003_pruned.tlt
-eq union
-pth 0.7
-k nvidia_tlt
Retraining the pruned model#
Once the model has been pruned, there might be a slight decrease in accuracy. This happens
because some previously useful weights may have been removed. In order to regain the accuracy,
NVIDIA recommends that you retrain this pruned model over the same dataset. To do this, use
the tao model faster_rcnn train command as documented in Training the model with
an updated specification file that points to the newly pruned model as the pretrained model file.
Users are advised to turn off the regularizer(set regularizer type to NO_REG) or use a
smaller weight decay in the specification file to recover the accuracy when retraining a pruned model.
All the other parameters may be retained in the specification file from the previous training.
For FasterRCNN, it is important to set the retrain_pruned_model path to point to the pruned
model.
Exporting the model#
Exporting the model decouples the training process from inference and allows conversion to
TensorRT engines outside the TAO environment. TensorRT engines are specific to each hardware
configuration and should be generated for each unique inference environment.
The exported model may be used universally across training and deployment hardware.
The exported model format is referred to as .etlt. Like .tlt, the .etlt model
format is also a encrypted model format with the same key of the .tlt model that it is
exported from. This key is required when deploying this model.
FasterRCNN export can optionally generate a (partial) DeepStream configuration file and label file. See below.
INT8 Mode Overview#
TensorRT engines can be generated in INT8 mode to improve performance, but require a calibration
cache at engine creation-time. The calibration cache is generated using a calibration tensor
file, if export is run with the --data_type flag set to int8.
Pre-generating the calibration information and caching it removes the need for calibrating the
model on the inference device. Using the calibration cache also speeds up engine creation as building the
cache can take several minutes to generate depending on the size of the calibration data and the model
itself.
The export tool can generate INT8 calibration cache by ingesting training data using either of these options:
Option 1: Using the training data loader to load the training images for INT8 calibration. This option is now the recommended approach to support multiple image directories by leveraging the training dataset loader. This also ensures two important aspects of data during calibration:
Data pre-processing in the INT8 calibration step is the same as in the training process.
The data batches are sampled randomly across the entire training dataset, thereby improving the accuracy of the INT8 model.
Option 2: Pointing the tool to a directory of images that you want to use to calibrate the model. For this option, make sure to create a sub-sampled directory of random images that best represent your training dataset.
FP16/FP32 Model#
The calibration.bin is only required if you need to run inference at INT8 precision. For
FP16/FP32 based inference, the export step is much simpler. All that is required is to provide
a .tlt model from the training/retraining step to be converted into an .etlt.
Exporting the Model#
Here’s an example of the tao model faster_rcnn export command:
tao model faster_rcnn export [-h] -m <path to the .tlt model file generated by training>
-k <key>
--experiment_spec <path to experiment specification file>
[-o <path to output file>]
[--cal_json_file <path to calibration json file>]
[--gen_ds_config]
[--verbose]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments#
-m, --model: Path to the.tltmodel file to be exported.-k, --key: Key used to save the.tltmodel file.-e, --experiment_spec: Path to the specification file.
Optional Arguments#
-o, --output_file: Path to save the exported model to. The default is./<input_file>.etlt.--gen_ds_config: A Boolean flag indicating whether to generate the partial DeepStream related configuration (“nvinfer_config.txt”) as well as a label file (“labels.txt”) in the same directory as theoutput_file. Note that the config file is NOT a complete configuration file and requires the user to update the sample config files in DeepStream with the parameters generated.--gpu_index: The index of (discrete) GPUs used for exporting the model. We can specify the GPU index to run export if the machine has multiple GPUs installed. Note that export can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.
QAT Export Mode Required Arguments#
--cal_json_file: The path to the json file containing tensor scale for QAT models. Thisargument is required if engine for QAT model is being generated.
Note
When exporting a model trained with QAT enabled, the tensor scale factors to calibrate
the activations are peeled out of the model and serialized to a JSON file defined by the
cal_json_file argument.
Sample Usage#
Here’s a sample command to export a FasterRCNN model:
tao model faster_rcnn export --gpu_index 0
-m $USER_EXPERIMENT_DIR/data/faster_rcnn/frcnn_kitti_resnet18_retrain.epoch12.tlt
-o $USER_EXPERIMENT_DIR/data/faster_rcnn/frcnn_kitti_resnet18_retrain_int8.etlt
-e $SPECS_DIR/default_spec_resnet18_retrain_spec.txt
-k nvidia_tlt
TensorRT engine generation, validation, and int8 calibration#
For TensorRT engine generation, validation, and int8 calibration, please refer to TAO Deploy documentation.
Deploying to DeepStream#
For deploying to deepstream, please refer to Deploying to DeepStream for FasterRCNN.