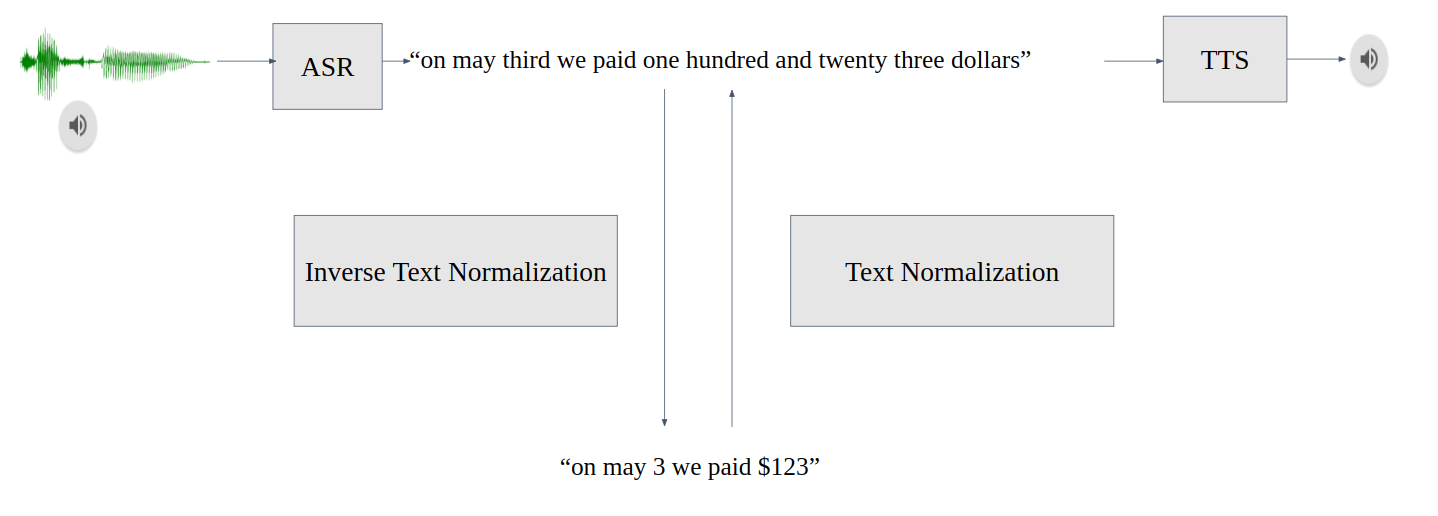
Text (Inverse) Normalization#
Warning
TN/ITN transitioned from NVIDIA/NeMo repository to a standalone NVIDIA/NeMo-text-processing repository. All updates and discussions/issues should go to the new repository.
The nemo_text_processing Python package is based on WFST grammars [TEXTPROCESSING-NORM2] and supports:
Text Normalization (TN) converts text from written form into its verbalized form. It is used as a preprocessing step before Text to Speech (TTS). For example,
"123" -> "one hundred twenty three"
nemo_text_processing has both a fast version which is deterministic [TEXTPROCESSING-NORM3] which has more language support and a context-aware version [TEXTPROCESSING-NORM1]. In case of ambiguous input, e.g.
"St. Patrick's Day" -> "Saint Patrick's Day"
"St. Patrick's Day" -> "Street Patrick's Day"
the context-aware TN will convert “St. Patrick’s Day” to “Saint Patrick’s Day”.
Inverse text normalization (ITN) is a part of the Automatic Speech Recognition (ASR) post-processing pipeline and can be used to convert normalized ASR model outputs into written form to improve text readability. For example,
"one hundred twenty three" -> "123"
Audio-based provides multiple normalization options. For example,
"123" -> "one hundred twenty three", "one hundred and twenty three", "one two three", "one twenty three" ...
The normalization which best reflects what is actually said in an audio is then picked. Audio-based TN can be used to normalize ASR training data.
Installation#
If you have already installed nemo_text_processing, it should have pynini python library. Otherwise install explicitly:
pip install pynini==2.1.5
or if this fails on missing OpenFst headers:
conda install -c conda-forge pynini=2.1.5
Quick Start Guide#
Text Normalization#
The standard text normalization based on WFST [TEXTPROCESSING-NORM3] is not context-aware. It is fast and can be run like this:
cd NeMo-text-processing/nemo_text_processing/text_normalization/
python normalize.py --text="123" --language=en
if you want to normalize a string. To normalize a text file split into sentences, run the following:
cd NeMo-text-processing/nemo_text_processing/text_normalization/
python normalize.py --input_file=INPUT_FILE_PATH --output_file=OUTPUT_FILE_PATH --language=en
The context-aware version [TEXTPROCESSING-NORM1] is a shallow fusion of non-deterministic WFST and pretrained masked language model.

cd NeMo-text-processing/nemo_text_processing/
python wfst_lm_rescoring.py
Inverse Text Normalization#
cd NeMo-text-processing/nemo_text_processing/inverse_text_normalization/
python inverse_normalize.py --text="one hundred twenty three" --language=en
Arguments:
text- Input text. Should not exceed 500 words.input_file- Input file with lines of input text. Only one oftextorinput_fileis accepted.output_file- Output file to save normalizations. Needed ifinput_fileis specified.language- language id.input_case- Only for text normalization.lower_casedorcased.verbose- Outputs intermediate information.cache_dir- Specifies a cache directory for compiled grammars. If grammars exist, this significantly improves speed.overwrite_cache- Updates grammars in cache.whitelist- TSV file with custom mappings of written text to spoken form.
Warning
The maximum length of a single string to be (de-)normalized should not exceed 500 words. To avoid this, please split your string into sentences shorter than this limit and pass it as --input_file instead.
Audio-based TN#
cd NeMo-text-processing/nemo_text_processing/text_normalization/
python normalize_with_audio.py --text="123" --language="en" --n_tagged=10 --cache_dir="cache_dir" --audio_data="example.wav" --model="stt_en_conformer_ctc_large"
Additional Arguments:
text- Input text or JSON manifest file with multiple audio paths.audio_data- (Optional) Input audio.model- Off-shelf NeMo CTC ASR model name or path to local NeMo model checkpoint ending on .nemon_tagged- number of normalization options to output.
Note
More details can be found in NeMo-text-processing/tutorials/text_processing/Text_(Inverse)_Normalization.ipynb in Google’s Colab.
Language Support Matrix#
Language |
ID |
TN |
ITN |
Audio-based TN |
context-aware TN |
English |
en |
x |
x |
x |
x |
Spanish |
es |
x |
x |
x |
|
Spanish-English |
es_en |
x |
|||
French |
fr |
x |
x |
||
German |
de |
x |
x |
x |
|
Arabic |
ar |
x |
x |
||
Russian |
ru |
x |
x |
||
Swedish |
sv |
x |
x |
||
Vietnamese |
vi |
x |
|||
Portuguese |
pt |
x |
|||
Chinese |
zh |
x |
x |
||
Hungarian |
hu |
x |
|||
Italian |
it |
x |
|||
Armenian |
hy |
x |
x |
||
Marathi |
mr |
x |
|||
Hindi |
hi |
x |
x |
||
Japanese |
ja |
x |
x |
See Grammar customization for grammar customization details.
See Text Processing Deployment for deployment in C++ details.
WFST TN/ITN resources could be found in here.
References#
Evelina Bakhturina, Yang Zhang, and Boris Ginsburg. Shallow fusion of weighted finite-state transducer and language model for text normalization. arXiv preprint arXiv:2203.15917, 2022.
Mehryar Mohri, Fernando Pereira, and Michael Riley. Weighted automata in text and speech processing. arXiv preprint cs/0503077, 2005.
Yang Zhang, Evelina Bakhturina, Kyle Gorman, and Boris Ginsburg. Nemo inverse text normalization: from development to production. 2021. arXiv:2104.05055.