Deploy to Production with C++ backend#
Warning
TN/ITN transitioned from NVIDIA/NeMo repository to a standalone NVIDIA/NeMo-text-processing repository. All updates and discussions/issues should go to the new repository.
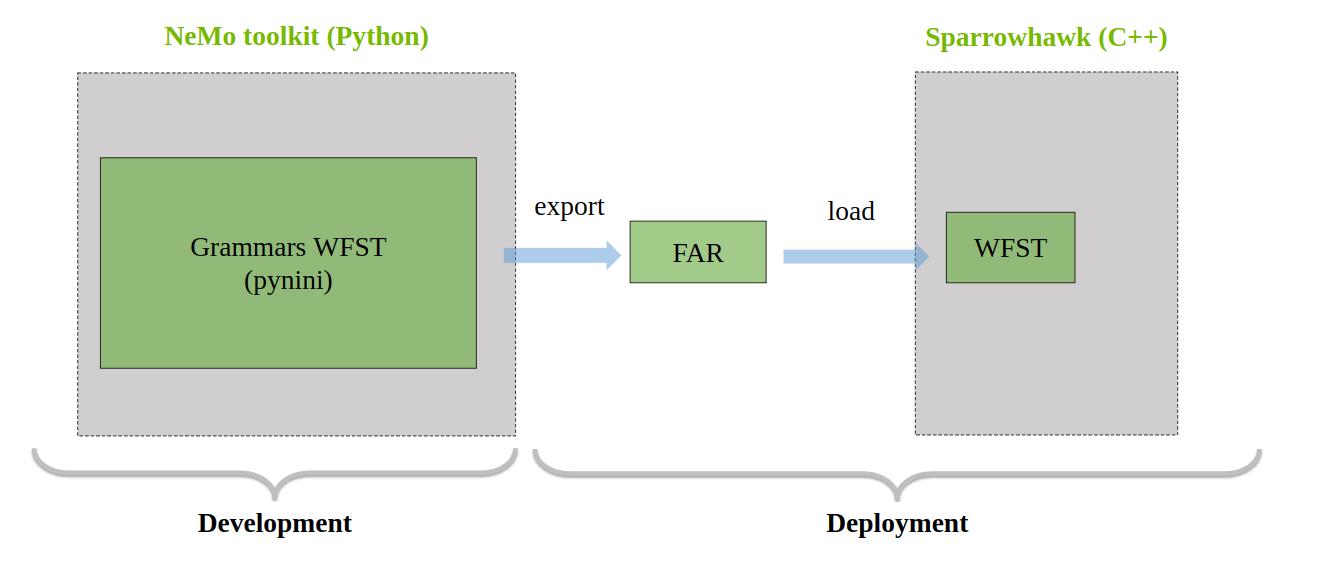
NeMo-text-processing provides tools to deploy TN and ITN for production [TEXTPROCESSING-DEPLOYMENT2]. It uses Sparrowhawk [TEXTPROCESSING-DEPLOYMENT1] – an open-source C++ framework by Google. The grammars written with NeMo-text-processing can be exported into an OpenFST Archive File (FAR) and dropped into Sparrowhawk.
Requirements#
Quick Start#
Examples how to run:
# export English TN grammars and return prompt inside docker container
cd NeMo-text-processing/tools/text_processing_deployment
bash export_grammars.sh --GRAMMARS=tn_grammars --LANGUAGE=en --INPUT_CASE=cased
# export English ITN grammars and return prompt inside docker container
cd NeMo-text-processing/tools/text_processing_deployment
bash export_grammars.sh --GRAMMARS=itn_grammars --LANGUAGE=en
Arguments:#
GRAMMARS-tn_grammarsoritn_grammarsto export either TN or ITN grammars.LANGUAGE- en for English. Click here for full list of languages.INPUT_CASE-casedorlower_cased(ITN has no differentiation between these two, only used for TN).MODE- By defaultexportwhich returns prompt inside the docker. If--MODE=testruns NeMo-text-processing pytests inside container.OVERWRITE_CACHE- Whether to re-export grammars or load from cache. By defaultTrue.FORCE_REBUILD- Whether to rebuild docker image in cased of updated dependencies. By defaultFalse.
Detailed pipeline#
export_grammars.sh runs the following steps in sequence:
Go to script folder:
cd NeMo-text-processing/tools/text_processing_deployment
Grammars written in Python are exported to OpenFST archive files (FAR). Specifically, grammars ClassifyFst and VerbalizeFst from nemo_text_processing are exported and saved to ./LANGUAGE/classify/tokenize_and_classify.far and ./LANGUAGE/verbalize/verbalize.far respectively.
python pynini_export.py <--output_dir .> <--grammars GRAMMARS> <--input_case INPUT_CASE> <--language LANGUAGE>
Warning
TN and ITN grammars are saved to the same file by default.
Docker image is built with dependencies, including Thrax and Sparrowhawk.
bash docker/build.sh
Plugs in grammars into production backend by mounting grammar directory LANGUAGE/classify/ and LANGUAGE/verbalize/ inside docker. Returns docker prompt.
# launch container with the exported grammars
bash docker/launch.sh
Runs system in docker container.
echo "ITN result: two dollars fifty. TN result: $2.50" | ../../src/bin/normalizer_main --config=sparrowhawk_configuration.ascii_proto
This returns “ITN result: $2.50. TN result: two dollars fifty cents”
See WFST Resources for more details.
References#
Alexander Gutkin, Linne Ha, Martin Jansche, Knot Pipatsrisawat, and Richard Sproat. Tts for low resource languages: a bangla synthesizer. In 10th Language Resources and Evaluation Conference. 2016.
Yang Zhang, Evelina Bakhturina, Kyle Gorman, and Boris Ginsburg. Nemo inverse text normalization: from development to production. 2021. arXiv:2104.05055.