Nemotron 3 Omni Training Recipe#
Multimodal post-training pipeline for Nemotron 3 Nano Omni, NVIDIA’s 30B-A3B hybrid mixture-of-experts model. Unlike Nano3 and Super3, Omni starts from a GA checkpoint and owns its stage-local container builds.
Read the blog?#
Quick navigation for developers landing here from the release blog:
You want… |
Go to |
|---|---|
Architecture deep-dive (Mamba+transformer, EVS, NemoClaw) |
|
Inference engines, quantization, cloud platforms, providers |
|
Reproduce training |
§Quick Start below |
SFT details |
|
RL details |
Model Overview#
Property |
Value |
|---|---|
Architecture |
Hybrid MoE — Mamba layers (sequence/memory efficiency) + transformer layers (reasoning), with a unified text decoder (details) |
Total / active parameters |
30B / 3B (A3B MoE) |
Native modalities |
Text, image, video, audio |
Max context length |
262K tokens |
Training context schedule |
16K → 49K → 262K (progressive scaling, see §Progressive context scaling) |
Vision encoder |
|
Audio encoder |
|
Video pipeline |
|
GA checkpoint |
|
License |
NVIDIA Nemotron Open Model License (enterprise-friendly, on-prem and any deployment) |
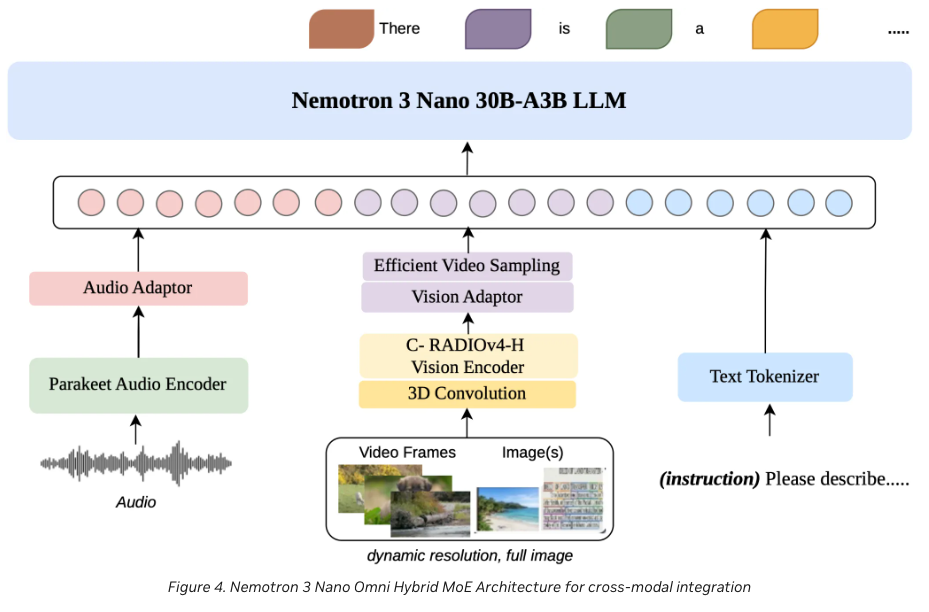
For the full architectural deep-dive — including why EVS drives the throughput numbers, the perception-sub-agent framing, and the released training-data scale (127B / 124M / 20×25 / 11.4M) — see architecture.md.
Capabilities (released benchmarks)#
Best-in-class on MMlongbench-Doc and OCRBenchV2 (document intelligence)
Leading on WorldSense, DailyOmni, VoiceBench (video / audio understanding)
~9.2× greater effective system capacity on video reasoning, ~7.4× on multi-document workloads vs. comparable open omni models
“Highest throughput across every task” in MediaPerf; “lowest inference cost for video-level tagging”
See
inference.mdfor engines, quantization paths, hardware support, and deployment
Use cases#
Designed as a multimodal perception sub-agent for agentic AI — finance, healthcare, scientific discovery, media/entertainment, ad-tech. Especially strong on long-horizon reasoning over complex documents and large video batches. The NemoClaw sandbox provides privacy-first video processing for compliance-bounded workloads.
Upstream training recipes#
This recipe folder is the cookbook view; upstream sources are:
Stage |
Upstream guide |
Branch root |
|---|---|---|
SFT (Megatron-Bridge) |
||
RL (NeMo-RL) |
||
Evaluation |
Same Megatron-Bridge path |
(above) |
Image training data |
— |
|
Long-document SDG |
|
Current Limitations#
The recipe structure, CLI, Dockerfiles, and configs are all in place, but some pieces still depend on upstream work or internal-only data:
Evaluation stage not yet included — coming soon. The omni3 CLI doesn’t have an
evalsubcommand today. Multimodal sanity checks against a trained checkpoint run vianemotron omni3 model eval; see SFT guide §Model lifecycle. A dedicated eval stage that compiles a benchmark task list and submits throughnemo-evaluator-launcherwill land in a follow-up release.SFT default uses CORD-v2 (open); Valor32k is an opt-in.
default.yamlpulls CORD-v2 from HuggingFace via thevlm-hfloader — no local shard building required.-c valor32kswitches to the full audio-visual-language flow, but requires internal access to a prepared Valor32k-AVQA Energon dataset (the raw-shard builder is internal-only at release).data_prep.pyvalidates the Energon path or emits a manifest for HF — it does not assemble shards.Long-document SDG pipeline is a scaffold.
src/nemotron/recipes/data/sdg/long-document/has 9 numbered scripts with their argparse surfaces and a thorough README, but the script bodies raiseNotImplementedError— port bodies from upstream at release time. Seedesigns/long-document-sdg-pipeline.md.Pinned to release branches. The SFT Dockerfile pulls
github.com/NVIDIA-NeMo/Megatron-Bridge @ nemotron_3_omni(andgithub.com/NVIDIA/Megatron-LM @ nemotron_3_omnias a recursive submodule fetch); the RL flow usesgithub.com/NVIDIA/NeMo-RL @ nano-v3-omni. These are the active release branches for Nemotron 3 Omni — bump to a versioned tag (ormain) once these changes merge upstream.
The linked stage guides (SFT / RL / Evaluate) call out each stage’s specific limitations.
Quick Start#
Prerequisites#
Slurm cluster with GPU nodes for SFT, RL, and evaluation — see Execution through NeMo-Run
Weights & Biases for experiment tracking and artifact lineage
Build-capable execution profile for
nemotron omni3 build <stage>jobsGA checkpoint: nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 (BF16 weights). FP8 and NVFP4 quantization paths are supported by the inference engines listed in
inference.md.
Installation#
git clone https://github.com/NVIDIA/nemotron
cd nemotron
uv sync
Configuration#
Create an env.toml profile with both training and build settings:
[wandb]
project = "nemotron"
entity = "YOUR-TEAM"
[YOUR-CLUSTER]
executor = "slurm"
account = "YOUR-ACCOUNT"
partition = "batch"
run_partition = "interactive"
# Build-context overrides — used by `omni3 build sft|rl` only. The build
# is CPU-only and writes its OCI archive to `build_cache_dir`, which
# must be a cluster-visible (e.g. Lustre) path because the dispatcher
# mounts it into the build container.
build_partition = "cpu"
build_time = "02:00:00"
build_cache_dir = "/lustre/.../users/YOUR-USER/.cache/nemotron"
nodes = 1
ntasks_per_node = 8
gpus_per_node = 8
mounts = ["/lustre:/lustre"]
See How container builds authenticate for how the dispatcher reuses your existing
~/.config/enroot/.credentialsto pullnvcr.ioimages inside the build container — no separate podman login required.
Run the Pipeline#
// Stage 0: SFT
$ uv run nemotron omni3 build sft --run YOUR-CLUSTER
$ uv run nemotron omni3 data prep sft --run YOUR-CLUSTER
$ uv run nemotron omni3 model import pretrain --run YOUR-CLUSTER \
--hf-model nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 \
--megatron-path /checkpoints/nemotron_omni
$ uv run nemotron omni3 sft --run YOUR-CLUSTER
// Stage 1.1: RL MPO
$ uv run nemotron omni3 build rl --run YOUR-CLUSTER
$ uv run nemotron omni3 data prep rl -c mpo --run YOUR-CLUSTER
$ uv run nemotron omni3 rl mpo --run YOUR-CLUSTER
// Stage 1.2: RL text
$ uv run nemotron omni3 data prep rl -c text --run YOUR-CLUSTER
$ uv run nemotron omni3 rl text --run YOUR-CLUSTER
// Stage 1.3: RL vision
$ uv run nemotron omni3 data prep rl -c vision --run YOUR-CLUSTER
$ uv run nemotron omni3 rl vision --run YOUR-CLUSTER
Note:
omni3 buildsubmits a short CPU-only container build job through NeMo-Run. The build produces${build_cache_dir}/containers/omni3-{sft,rl}.sqsh(squashfs) which pyxis mounts directly at training time — no per-jobenroot import.
Resources#
Model checkpoint: nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16
Release blog: NVIDIA Nemotron 3 Nano Omni — multimodal agent reasoning
SFT recipe: Stage 0: SFT
RL recipe: Stage 1: RL
Image training data:
nvidia/Nemotron-Image-Training-v3
Training Pipeline#
Stage |
Name |
Purpose |
Guide |
|---|---|---|---|
0 |
Fine-tune the GA checkpoint on Valor32k and related multimodal variants |
||
1 |
Multi-stage Omni RL: MPO → text RL → vision RL |
An evaluation stage (
nemotron omni3 eval) is on the roadmap; until it lands, run benchmarks vianemotron omni3 model eval(see SFT guide §Model lifecycle).
Pipeline Overview#
%%{init: {'theme': 'base', 'themeVariables': { 'primaryBorderColor': '#333333', 'lineColor': '#333333', 'primaryTextColor': '#333333', 'clusterBkg': '#ffffff', 'clusterBorder': '#333333'}}}%%
flowchart LR
sdg["data/sdg/long-document<br/>synthetic document data"] --> prep["omni3 data prep sft"]
ga["GA HF checkpoint"] --> import["omni3 model import pretrain"]
prep --> sft["omni3 sft"]
import --> sft
sft --> mpo["omni3 rl mpo"]
mpo --> text["omni3 rl text"]
text --> vision["omni3 rl vision"]
style sdg fill:#e3f2fd,stroke:#2196f3
style sft fill:#f3e5f5,stroke:#9c27b0
style mpo fill:#e8f5e9,stroke:#4caf50
style text fill:#e8f5e9,stroke:#4caf50
style vision fill:#e8f5e9,stroke:#4caf50
The upstream synthetic-data pipeline lives outside the family tree under src/nemotron/recipes/data/sdg/long-document/. That keeps the recipe split explicit:
src/nemotron/recipes/data/curation/— filter, dedup, and curate existing corpora (for example Nemotron-CC)src/nemotron/recipes/data/sdg/— generate new datasets, including the long-document SDG pipeline consumed by Omni SFTsrc/nemotron/recipes/omni3/— family-specific training, RL, and evaluation stages
Stage Summaries#
Stage 0: SFT#
Omni SFT owns its own Dockerfile, data_prep.py, and train.py (built via the nemotron omni3 build sft dispatcher). The stage ports the Valor32k flow plus LoRA/PEFT variants for image-text and audio-text tuning. The released open-data configs target shorter sequence lengths; the upstream 16K → 49K → 262K progressive schedule is documented in architecture.md.
Stage 1: RL#
The RL stack uses one shared NeMo-RL container and three sub-stages, mirroring the upstream nano-v3-omni flow:
MPO — multimodal preference optimization on the public MMPR dataset (~83K-row preference triples per subset)
Text RL — GRPO continuation of alignment on
nvidia/Nemotron-3-Nano-RL-Training-BlendVision RL — GRPO on MMPR-Tiny (data prep ready; training launcher pending upstream)
The 20 RL datasets / 25 environments / ~2.3M rollouts referenced in the release blog compose the full upstream alignment corpus; this recipe surfaces the public/open-source subset.
→ RL Guide · RL Data Prep
Execution Options#
All Omni commands support NeMo-Run execution modes:
Option |
Behavior |
Use Case |
|---|---|---|
|
Attached—submits job and streams logs |
Interactive development |
|
Detached—submits and exits immediately |
Long-running jobs |
|
Preview resolved config or build plan |
Validation |
CLI Reference#
$ uv run nemotron omni3 --help
Usage: nemotron omni3 [OPTIONS] COMMAND [ARGS]...
Omni3 training recipe
╭─ Infrastructure ─────────────────────────────────────────────────────────╮
│ build Build an Omni3 stage container via podman on the cluster. │
╰───────────────────────────────────────────────────────────────────────────╯
╭─ Commands ────────────────────────────────────────────────────────────────╮
│ data Data preparation commands │
│ model Model import/export/eval commands │
│ rl Reinforcement learning sub-stages │
╰───────────────────────────────────────────────────────────────────────────╯
╭─ Training Stages ─────────────────────────────────────────────────────────╮
│ sft Run omni3 supervised fine-tuning. │
╰───────────────────────────────────────────────────────────────────────────╯