Nemotron 3 Nano Omni — Architecture#
A deep-dive into the architectural decisions behind Nemotron 3 Nano Omni — what’s in the model, why each piece is there, and where the efficiency story comes from. For training instructions see the recipe overview; for deployment see inference.md.
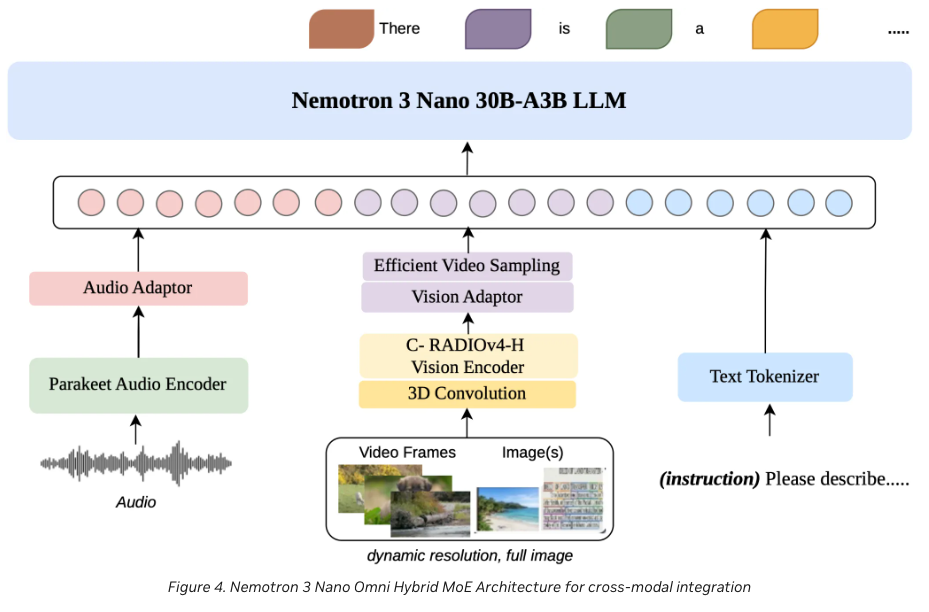
Figure 1. Cross-modal integration. Each modality has a dedicated encoder and adaptor; all token streams converge on the unified 30B-A3B Mamba-transformer decoder, which is the only place reasoning happens.
Hybrid MoE decoder#
Property |
Value |
|---|---|
Total parameters |
30B |
Active parameters per forward pass |
3B |
Architecture |
Hybrid MoE |
Layer mix |
Mamba layers (sequence/memory efficiency) + transformer layers (reasoning) |
Decoder |
Unified text decoder serves as the central reasoning core for all modalities |
Max context length |
262K tokens |
Training context schedule |
16K → 49K → 262K (progressive scaling, see §Progressive context scaling) |
The “A3B” in the model name (30B-A3B) means 30B total parameters / 3B active: the MoE router selects a small subset of expert layers per token, so inference compute is bounded by the 3B active count rather than the 30B total. The Mamba layers handle long-context state with linear time/memory; the transformer layers handle the local-reasoning hot path. The two compose into a unified decoder that all modality encoders feed into — so reasoning, planning, and tool-calling stay in one place rather than fanning out to per-modality heads.
Vision encoder — C-RADIOv4-H#
The vision side uses C-RADIOv4-H, a high-resolution image encoder. It’s the same family as RADIO (Robust Anti-Distillation On vision foundation models) — a learned distillation across multiple frozen teacher models (CLIP, DINOv2, SAM, etc.) that produces a single ViT capable of standing in for any of them. The “v4-H” variant is the high-res release with stronger document-understanding signal, which is part of why omni places best-in-class on MMlongbench-Doc and OCRBenchV2.
Audio encoder — Parakeet (extended)#
Audio uses NVIDIA Parakeet as the encoder, extended via the Granary and Music Flamingo integrations. Parakeet alone gives strong ASR; the Granary/Music Flamingo extensions broaden the audio surface (paralinguistic, music, ambient sound) which is what makes the model competitive on VoiceBench and gives it a usable audio interface for general media-understanding tasks rather than just transcription.
Video pipeline — 3D convolutions + Efficient Video Sampling (EVS)#
Video is handled in two stages: 3D convolutions capture spatiotemporal features natively (motion is a first-class signal, not inferred from a frame-by-frame transcript), and an Efficient Video Sampling (EVS) layer compresses high-density visual tokens across consecutive frames before they hit the decoder.
This is the key efficiency lever for the model. The release blog cites:
~9.2× greater effective system capacity vs. comparable open omni models on video reasoning workloads
~7.4× greater capacity on multi-document workloads
“Highest throughput across every task” in the MediaPerf benchmark, “lowest inference cost for video-level tagging”
Why 3D conv + EVS is decisive vs. transcript-style approaches:
3D conv preserves motion. Frame-by-frame transcript pipelines can’t see motion natively — they hallucinate temporal relations from spatial features in adjacent frames. Native 3D conv gives the decoder real motion features.
EVS bounds the token count. Without EVS, a 60-second video at 24 fps × per-frame patch count blows past 262K tokens trivially. EVS compresses frame redundancy before the decoder, so the unified text decoder can still reason over the full clip in-context.
If you’re doing video-heavy inference and tuning for throughput, EVS configuration is the lever to optimize — see inference.md for runtime knobs.
Progressive context scaling#
The 16K → 49K → 262K sequence is a training schedule, not a property of the inference model. The training pipeline grows the context window in stages so the model first masters short-context cross-modal instruction-following, then extends to medium context, and finally to long context — each stage unfreezing more parameters as needed. This is the same recipe shape used by Nemotron 3 Nano’s pretrain → SFT → RL flow, scaled to the multimodal case.
Implementation note for this recipe folder. The released configs in
src/nemotron/recipes/omni3/stage0_sft/config/target shorter context lengths than the upstream 49K/262K stages — those longer-context schedules use additional internal data and aren’t fully reproducible from the open-source subset. Thedefault.yamlopen-data flow trains the projector only on CORD-v2 with the GA model frozen; longer-context stages are documented here for completeness but ship as configuration stubs. Operators with internal data access can reproduce them by bumpingseq_lengthand the data path. Seedocs/nemotron/omni3/sft.mdfor the per-config breakdown.
Synthetic data — long-document SDG#
The release blog calls out ~11.4M synthetic visual QA pairs (~45B tokens) generated via NVIDIA NeMo Data Designer. The long-document SDG recipe is published in this repository (guide, source) — a 9-stage pipeline with structured argparse surfaces.
Training scale (release figures)#
Stage |
Scale |
|---|---|
Adapter & encoder training |
~127B tokens, mixed modalities (text+image, text+video, text+audio, text+video+audio) |
Curated post-training examples |
~124M |
RL alignment |
20 datasets across 25 environments, ~2.3M rollouts |
Synthetic visual QA |
~11.4M pairs / ~45B tokens |
This recipe folder reproduces the public-data subset of these stages — see each stage doc for which datasets are open-source vs. internal-only.
Why “perception sub-agent”#
The release blog frames omni as a multimodal perception sub-agent for agentic AI — not a general-purpose chat model. The architecture choices follow:
Single unified decoder so an outer agent can call this model with any combination of modalities and get reasoning back through one stable interface
EVS-bounded video tokens so the model can be invoked on full-length video inputs without per-clip pre-processing pipelines
Reasoning-trained checkpoint (
Reasoning-BF16suffix) for explicit multi-step thinking before tool callsNIM + open-license so it can drop into existing agent stacks (LangChain, LlamaIndex, custom orchestrators) without licensing friction
Stage docs (sft.md, rl.md) train and align this perception-sub-agent surface — instruction-following over multimodal inputs, not free-form chat.
License#
The model is released under the NVIDIA Nemotron Open Model License, which permits enterprise use including on-prem and commercial deployment. The license text is available on the model card; the same terms cover the released training data, recipes, and synthetic-data pipelines.
References#
Release blog — the canonical positioning + benchmark source for this doc
Model weights —
nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16Upstream pre-training recipe:
NVIDIA-NeMo/Megatron-Bridgenemotron_3_omniUpstream RL recipe:
NVIDIA-NeMo/RLnano-v3-omni