Turbulence Super Resolution
This example uses Modulus to train a super-resolution surrogate model for predicting high-fidelity homogeneous isotropic turbulence fields from filtered low-resolution observations provided by the Johns Hopkins Turbulence Database. This model will combine standard data-driven learning as well as how to define custom data-driven loss functions that are uniquely catered to a specific problem. In this example you will learn the following:
How to use data-driven convolutional neural network models in Modulus
How to define custom data-driven loss and constraint
How to define custom data-driven validator
Modulus features for structured/grid data
Adding custom parameters to the problem configuration file
This tutorial assumes that you have completed the Introductory Example tutorial on Lid Driven Cavity flow and have familiarized yourself with the basics of Modulus. This also assumes that you have a basic understanding of the convolution models in Modulus Pix2Pix Net and Super Resolution Net.
The Python package pyJHTDB is required for this example to download and process the training and validation datasets.
Install using pip install pyJHTDB.
The objective of this problem is to learn the mapping between a low-resolution filtered 3D flow field to a high-fidelity solution. The flow field will be samples of a forced isotropic turbulence direct numerical simulation originally simulated with a resolution of \(1024^{3}\). This simulation solves the forced Navier-Stokes equations:
(205)\[\frac{\partial \textbf{u}}{\partial t} + \textbf{u} \cdot \nabla \textbf{u} = -\nabla p /\nho + \nu \nabla^{2}\textbf{u} + \textbf{f}.\]
The forcing term \(\textbf{f}\) is used to inject energy into the simulation to maintain a constant total energy. This dataset contains 5028 time steps spanning from 0 to 10.05 seconds which are sampled every 10 time steps from the original pseudo-spectral simulation.

Fig. 137 Snap shot of \(128^{3}\) isotropic turbulence velocity fields
The objective is to build a surrogate model to learn the mapping between a low-resolution velocity field \(\textbf{U}_{l} = \left\{u_{l}, v_{l}, w_{l}\night\}\) to the true high-resolution field \(\textbf{U}_{h} = \left\{u_{h}, v_{h}, w_{h}\night\}\) for any low-resolution sample in this isotropic turbulence dataset \(\textbf{U}_{l} \sim p(\textbf{U}_{l})\). Due to the size of the full simulation domain, this tutorial focuses on predicting smaller volumes such that the surrogate learns with a low resolution dimensionality of \(32^{3}\) to a high-resolution dimensionality of \(128^{3}\). Use the Super Resolution Net in this tutorial, but Pix2Pix Net is also integrated into this problem and can be used instead if desired.
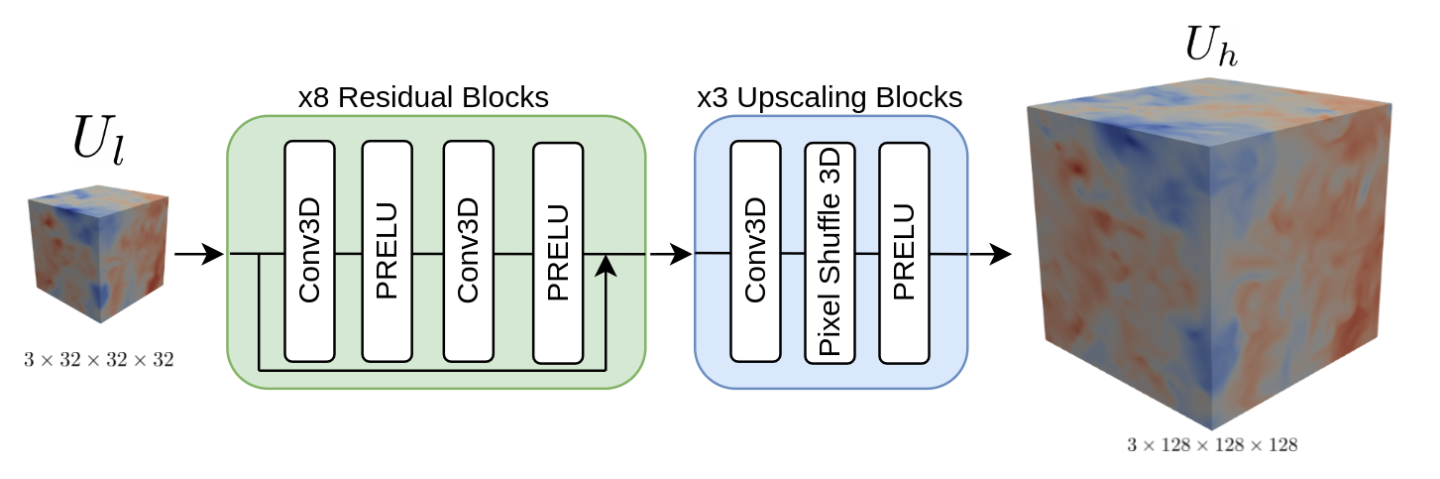
Fig. 138 Super resolution network for predicting high-resolution turbulent flow from low-resolution input
This example demonstrates how to write your own data-driven constraint.
Modulus ships with a standard supervised learning constraint for structured data called SupervisedGridConstraint used in the Darcy Flow with Fourier Neural Operator example.
However, if you want to have a problem specific loss you can extend the base GridConstraint.
Here, you will set up a constraint that can pose a loss between various measures for the fluid flow including velocity, continuity, vorticity, enstrophy and strain rate.
The python script for this problem can be found at examples/super_resolution/super_resolution.py.
class SuperResolutionConstraint(Constraint):
def __init__(
self,
nodes: List[Node],
invar: Dict[str, np.array],
outvar: Dict[str, np.array],
batch_size: int,
loss_weighting: Dict[str, int],
dx: float = 1.0,
lambda_weighting: Dict[str, Union[np.array, sp.Basic]] = None,
num_workers: int = 0,
):
dataset = DictGridDataset(
invar=invar, outvar=outvar, lambda_weighting=lambda_weighting
)
super().__init__(
nodes=nodes,
dataset=dataset,
loss=PointwiseLossNorm(),
batch_size=batch_size,
shuffle=True,
drop_last=True,
num_workers=num_workers,
)
self.dx = dx
self.ops = FlowOps().to(self.device)
An important part to note is that you can control which losses you want to contribute using a loss_weighting dictionary which will be provided from the config file.
Each one of these measures are calculated in examples/super_resolution/ops.py, which can be referenced for more information.
However, as a general concept, finite difference methods are used to calculate gradients of the flow field and the subsequent measures.
self.loss_weighting = {}
self.fields = set("U")
for key, value in loss_weighting.items():
if float(value) > 0:
self.fields = set(key).union(self.fields)
self.loss_weighting[key] = value
def calc_flow_stats(self, data_var):
output = {"U": data_var["U"]}
vel_output = {}
cont_output = {}
vort_output = {}
enst_output = {}
strain_output = {}
# compute derivatives
if len(self.fields) > 1:
grad_output = self.ops.get_velocity_grad(
data_var["U"], dx=self.dx, dy=self.dx, dz=self.dx
)
# compute continuity
if "continuity" in self.fields:
cont_output = self.ops.get_continuity_residual(grad_output)
# compute vorticity
if "omega" in self.fields or "enstrophy" in self.fields:
vort_output = self.ops.get_vorticity(grad_output)
# compute enstrophy
if "enstrophy" in self.fields:
enst_output = self.ops.get_enstrophy(vort_output)
# compute strain rate
if "strain" in self.fields:
strain_output = self.ops.get_strain_rate_mag(grad_output)
if "dU" in self.fields:
# Add to output dictionary
grad_output = torch.cat(
[
grad_output[key]
for key in [
"u__x",
"u__y",
"u__z",
"v__x",
"v__y",
"v__z",
"w__x",
"w__y",
"w__z",
]
],
dim=1,
)
vel_output = {"dU": grad_output}
if "omega" in self.fields:
vort_output = torch.cat(
[vort_output[key] for key in ["omega_x", "omega_y", "omega_z"]], dim=1
)
vort_output = {"omega": vort_output}
output.update(vel_output)
output.update(cont_output)
output.update(vort_output)
output.update(enst_output)
output.update(strain_output)
return output
def save_batch(self, filename):
# sample batch
invar, true_outvar, lambda_weighting = next(self.dataloader)
invar0 = {key: value for key, value in invar.items()}
invar = Constraint._set_device(invar, device=self.device, requires_grad=True)
true_outvar = Constraint._set_device(true_outvar, device=self.device)
Override the loss calculation with the custom method which calculates the relative MSE between predicted and target velocity fields using flow measures defined in the weight dictionary, self.loss_weighting.
def forward(self):
# compute forward pass of conv net
self._pred_outvar = self.model(self._input_vars)
def loss(self, step: int) -> Dict[str, torch.Tensor]:
# Calc flow related stats
pred_outvar = self.calc_flow_stats(self._pred_outvar)
target_vars = self.calc_flow_stats(self._target_vars)
# compute losses
losses = {}
for key in target_vars.keys():
mean = (target_vars[key] ** 2).mean()
losses[key] = (
self.loss_weighting[key]
* (((pred_outvar[key] - target_vars[key]) ** 2) / mean).mean()
)
return losses
The resulting complete loss for this problem is the following:
(206)\[\begin{split}\mathcal{L} = RMSE(\hat{U}_{h}, U_{h}) + \lambda_{dU}RMSE(\hat{dU}_{h}, dU_{h}) + \lambda_{cont}RMSE(\nabla\cdot\hat{U}_{h}, \nabla\cdot U_{h}) + \lambda_{\omega}RMSE(\hat{\omega}_{h}, \omega_{h}) \\
+ \lambda_{strain}RMSE(|\hat{D}|_{h}, |D|_{h}) + \lambda_{enst}RMSE(\hat{\epsilon}_{h}, \epsilon_{h}),\end{split}\]
in which \(\hat{U}_{h}\) is the prediction from the neural network and \(U_{h}\) is the target.
\(dU\) is the velocity tensor, \(\omega\) is the vorticity, \(|D|\) is the magnitude of the strain rate and \(\epsilon\) is the flow’s enstrophy.
All of these can be turned on and off in the configuration file under the custom.loss_weights config group.
Similarly, because the input and output are of different dimensionality, the built in GridValidator in Modulus will not work since it expects all tensors to be the same size.
You can easily extend this to write out the high-resolution outputs and low-resolution outputs into separate VTK uniform grid files.
class SuperResolutionValidator(GridValidator):
def __init__(self, *args, log_iter: bool = False, **kwargs):
super().__init__(*args, **kwargs)
self.log_iter = log_iter
self.device = DistributedManager().device
def save_results(self, name, results_dir, writer, save_filetypes, step):
invar_cpu = {key: [] for key in self.dataset.invar_keys}
true_outvar_cpu = {key: [] for key in self.dataset.outvar_keys}
pred_outvar_cpu = {key: [] for key in self.dataset.outvar_keys}
# Loop through mini-batches
for i, (invar0, true_outvar0, lambda_weighting) in enumerate(self.dataloader):
# Move data to device (may need gradients in future, if so requires_grad=True)
invar = Constraint._set_device(
invar0, device=self.device, requires_grad=self.requires_grad
)
true_outvar = Constraint._set_device(
true_outvar0, device=self.device, requires_grad=self.requires_grad
)
pred_outvar = self.forward(invar)
# Collect minibatch info into cpu dictionaries
invar_cpu = {
key: value + [invar[key].cpu().detach()]
for key, value in invar_cpu.items()
}
true_outvar_cpu = {
key: value + [true_outvar[key].cpu().detach()]
for key, value in true_outvar_cpu.items()
}
pred_outvar_cpu = {
key: value + [pred_outvar[key].cpu().detach()]
for key, value in pred_outvar_cpu.items()
}
# Concat mini-batch tensors
invar_cpu = {key: torch.cat(value) for key, value in invar_cpu.items()}
true_outvar_cpu = {
key: torch.cat(value) for key, value in true_outvar_cpu.items()
}
pred_outvar_cpu = {
key: torch.cat(value) for key, value in pred_outvar_cpu.items()
}
# compute losses on cpu
losses = GridValidator._l2_relative_error(true_outvar_cpu, pred_outvar_cpu)
# convert to numpy arrays
invar = {k: v.numpy() for k, v in invar_cpu.items()}
true_outvar = {k: v.numpy() for k, v in true_outvar_cpu.items()}
pred_outvar = {k: v.numpy() for k, v in pred_outvar_cpu.items()}
# save batch to vtk file
named_target_outvar = {"true_" + k: v for k, v in true_outvar.items()}
named_pred_outvar = {"pred_" + k: v for k, v in pred_outvar.items()}
for b in range(min(4, next(iter(invar.values())).shape[0])):
if self.log_iter:
grid_to_vtk(
{**named_target_outvar, **named_pred_outvar},
results_dir + name + f"_{b}_hr" + f"{step:06}",
batch_index=b,
)
else:
grid_to_vtk(
{**named_target_outvar, **named_pred_outvar},
results_dir + name + f"_{b}_hr",
batch_index=b,
)
grid_to_vtk(invar, results_dir + name + f"_{b}_lr", batch_index=b)
# add tensorboard plots
if self.plotter is not None:
self.plotter._add_figures(
name,
results_dir,
writer,
step,
invar,
true_outvar,
pred_outvar,
)
# add tensorboard scalars
for k, loss in losses.items():
writer.add_scalar("val/" + name + "/" + k, loss, step, new_style=True)
Here the grid_to_vtk function in Modulus is used, which writes tensor data to VTK Image Datasets (Uniform grids), which can then be viewed in Paraview.
When your data is structured grid_to_vtk is preferred to var_to_polyvtk due to the lower memory footprint of a VTK Image Dataset vs VTK Poly Dataset.
Before proceeding, it is important to recognize that this problem needs to download the dataset upon its first run.
To download the dataset from Johns Hopkins Turbulence Database you will need to request an access token.
Information regarding this process can be found on the database website.
Once aquired, please overwrite the default token in the config in the specified location.
Utilities used to download the data can be located in examples/super_resolution/jhtdb_utils.py, but will not be discussed in this tutorial.
By registering for an access token and using the Johns Hopkins Turbulence Database, you are agreeing to the terms and conditions of the dataset itself. This example will not work without an access token.
The default training dataset size is 512 sampled and the validation dataset size is 16 samples. The download can take several hours depending on your internet connection. The total memory footprint of the data is around 13.5Gb. A smaller dataset can be set in the config file.
Configuration
The config file for this example is as follows. Note that both the super-resolution and pix2pix encoder-decoder architecture configuration are included to test.
defaults:
- modulus_default
- /arch/super_res_cfg@arch.super_res
- /arch/pix2pix_cfg@arch.pix2pix
- scheduler: tf_exponential_lr
- optimizer: adam
- loss: sum
- _self_
jit: True
cuda_graphs: False # Graphs does not work with super res network
arch:
super_res:
scaling_factor: 4
pix2pix:
batch_norm: True
n_downsampling: 1
n_blocks: 9
dimension: 3
scaling_factor: 4
scheduler:
decay_rate: 0.95
decay_steps: 2000
optimizer:
lr: 0.0001
training:
rec_validation_freq: 250
rec_constraint_freq: 250
save_network_freq: 250
print_stats_freq: 25
max_steps: 20000
batch_size:
train: 4
valid: 4
custom:
jhtdb:
n_train: 512
n_valid: 16
domain_size: 128
access_token: "edu.jhu.pha.turbulence.testing-201311" #Replace with your own token here
loss_weights:
U: 1.0
dU: 0
continuity: 0
omega: 0.1
enstrophy: 0
strain: 0
The custom config group can be used to store case specific parameters that will not be used inside of Modulus.
Here you can use this group to define parameters related to the dataset size, the domain size of the fluid volumes and the database access token which you should replace with your own!
To just test the model with a toy dataset without a database access token you are recommended to use the below settings:
jhtdb:
n_train: 4
n_valid: 1
domain_size: 16
access_token: "edu.jhu.pha.turbulence.testing-201311"
Loading Data
To load the dataset into memory, you will use the following utilities:
# load jhtdb datasets
invar, outvar = make_jhtdb_dataset(
nr_samples=cfg.custom.jhtdb.n_train,
domain_size=cfg.custom.jhtdb.domain_size,
lr_factor=cfg.arch.super_res.scaling_factor,
token=cfg.custom.jhtdb.access_token,
data_dir=to_absolute_path("datasets/jhtdb_training"),
time_range=[1, 768],
dataset_seed=123,
)
invar_valid, outvar_valid = make_jhtdb_dataset(
nr_samples=cfg.custom.jhtdb.n_valid,
domain_size=cfg.custom.jhtdb.domain_size,
lr_factor=cfg.arch.super_res.scaling_factor,
token=cfg.custom.jhtdb.access_token,
data_dir=to_absolute_path("datasets/jhtdb_valid"),
time_range=[768, 1024],
dataset_seed=124,
)
This will download and cache the dataset locally, so you will not need to download it with every run.
Initializing the Model
Here you initialize the model following the standard Modulus process.
Note that the input and output keys have a size=3, which tells Modulus that these variables have 3 dimensions (velocity components).
model = instantiate_arch(
input_keys=[Key("U_lr", size=3)],
output_keys=[Key("U", size=3)],
cfg=cfg.arch.super_res,
)
nodes = [model.make_node(name="super_res")]
Adding Data Constraints
# make data driven constraint
jhtdb_constraint = SuperResolutionConstraint(
nodes=nodes,
invar=invar,
outvar=outvar,
batch_size=cfg.batch_size.train,
loss_weighting=cfg.custom.loss_weights,
lambda_weighting=None,
dx=2 * np.pi / 1024.0,
)
jhtdb_domain.add_constraint(jhtdb_constraint, "constraint")
Adding Data Validator
# make validator
dataset = DictGridDataset(invar_valid, outvar_valid)
jhtdb_validator = SuperResolutionValidator(
dataset=dataset,
nodes=nodes,
batch_size=cfg.batch_size.valid,
log_iter=False,
)
jhtdb_domain.add_validator(jhtdb_validator, "validator")
NVIDIA recommends that your first run be on a single GPU to download the dataset. Only root process will download the data from the online database while the others will be idle.
python super_resolution.py
However, parallel training is suggested for this problem once the dataset is downloaded. This example was trained on 4 V100 GPUs which can be run via Open MPI using the following command:
mpirun -np 4 python super_resolution.py
Results and Post-processing
Since this example illustrated how to set up a custom data-driven loss that is controllable through the config, you can compare the impact of several different loss components on the model’s performance. The TensorBoard plot is shown below with the validation dataset loss being the bottom most graph. Given the number of potential loss components, only a handful are compared here:
U=1.0: \(\mathcal{L} = RMSE(\hat{U}_{h}, U_{h})\)U=1.0, omega=0.1: \(\mathcal{L} = RMSE(\hat{U}_{h}, U_{h}) + 0.1RMSE(\hat{\omega}_{h}, \omega_{h})\)U=1.0, omega=0.1, dU=0.1: \(\mathcal{L} = RMSE(\hat{U}_{h}, U_{h}) + 0.1RMSE(\hat{\omega}_{h}, \omega_{h}) + 0.1RMSE(\hat{dU}_{h}, dU_{h})\)U=1.0, omega=0.1, dU=0.1, contin=0.1: \(\mathcal{L} = RMSE(\hat{U}_{h}, U_{h}) + 0.1RMSE(\hat{\omega}_{h}, \omega_{h}) + 0.1RMSE(\hat{dU}_{h}, dU_{h}) + 0.1RMSE(\nabla\cdot\hat{U}_{h}, \nabla\cdot U_{h})\)
The validation error is the L2 relative error between the predicted and true high-resolution velocity fields. You can see that the inclusion of vorticity in the loss equation increases the model’s accuracy, however the inclusion of other terms does not. Loss combinations of additional fluid measures has proven successful in past works 1 2. However, additional losses can potentially make the optimization more difficult for the model and adversely impact accuracy.
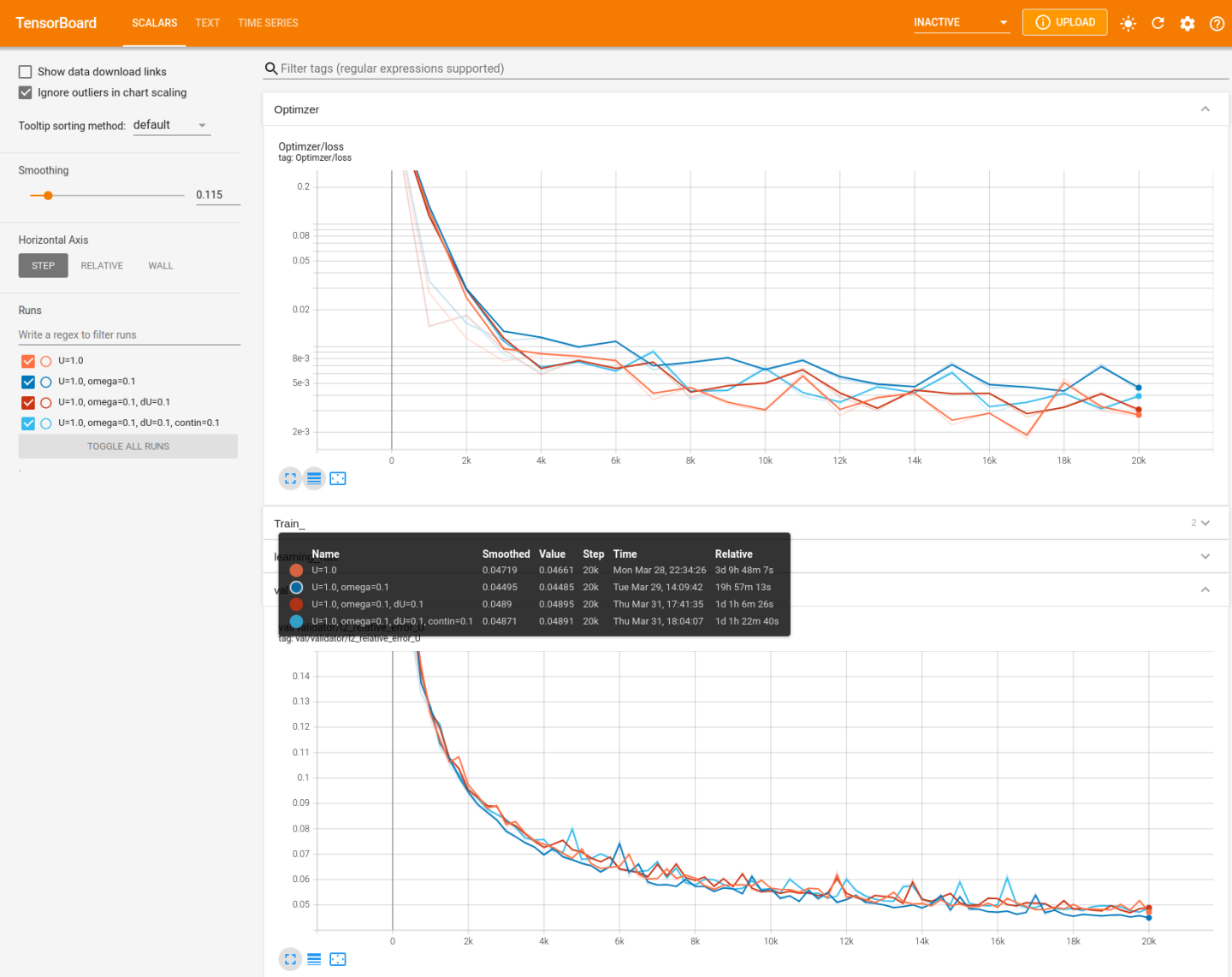
Fig. 139 Tensorboard plot comparing different loss functions for turbulence super-resolution
The output VTK files can be found in the 'outputs/super_resolution/validators' folder which you can then view in Paraview.
The volumetric plots of the velocity magnitude fields are shown below where you can see the model dramatically improves the low-resolution velocity field.
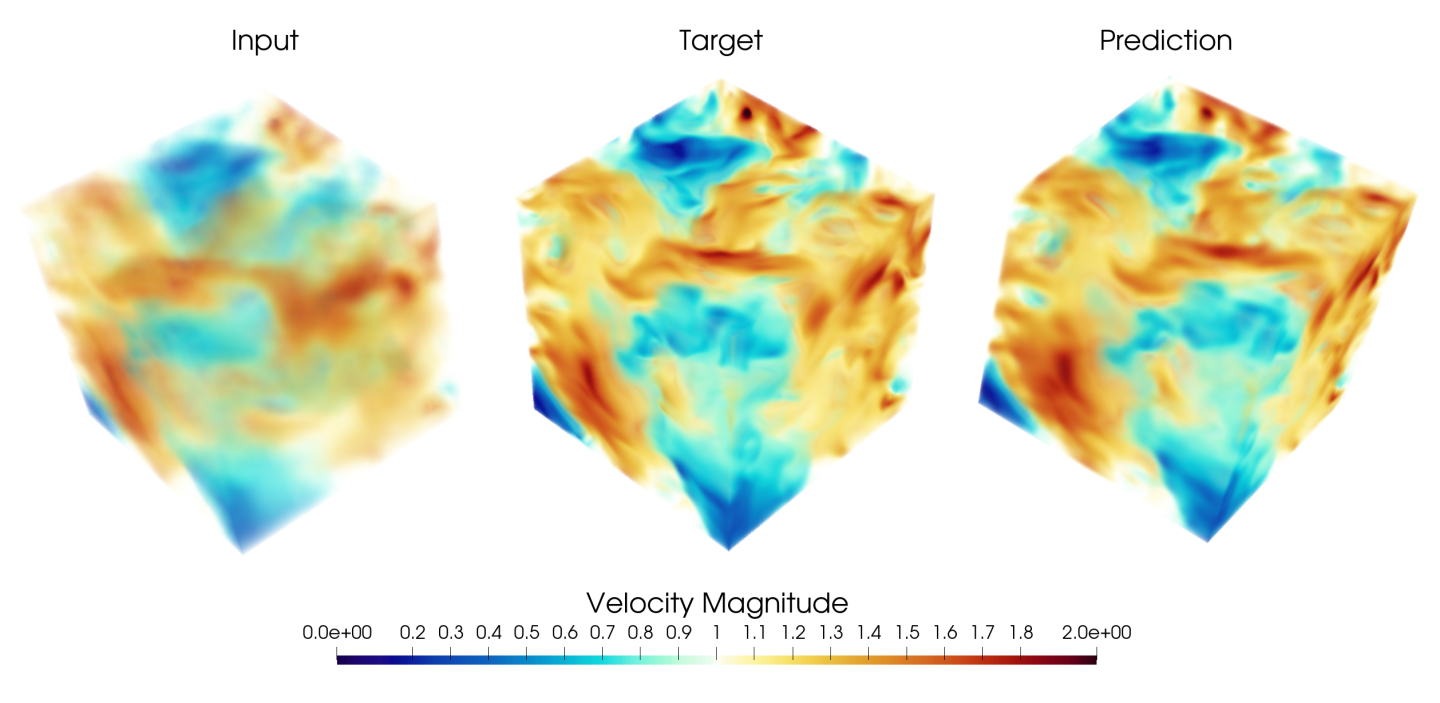
Fig. 140 Velocity magnitude for a validation case using the super resolution model for predicting turbulence
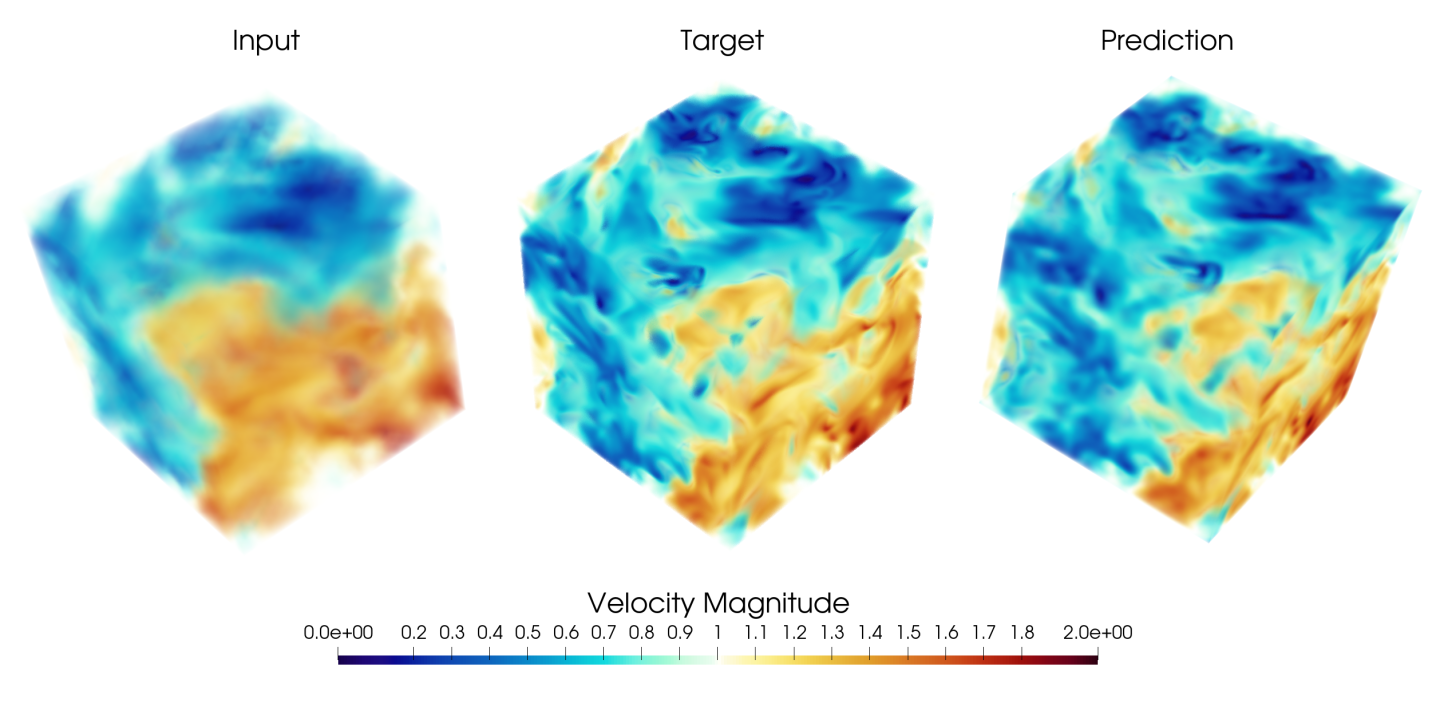
Fig. 141 Velocity magnitude for a validation case using the super resolution model for predicting turbulence
References