Darcy Flow with Adaptive Fourier Neural Operator
This tutorial demonstrates the use of transformer networks based on the Adaptive Fourier Neural Operators (AFNO) in Modulus. Note that in contrast with the Fourier Neural Operator which has a convolutional architecture, the AFNO leverages contemporary transformer architectures in the computer vision domain. Vision transformers have delivered tremendous success in computer vision. This is primarily due to effective self-attention mechanisms. However, self-attention scales quadratically with the number of pixels, which becomes infeasible for high-resolution inputs. To cope with this challenge, Guibas et al. 1 proposed the Adaptive Fourier Neural Operator (AFNO) as an efficient attention mechanism in the Fourier domain. AFNO is based on a principled foundation of operator learning which allows us to frame attention as a continuous global convolution without any dependence on the input resolution. This principle was previously used to design FNO, which solves global convolution efficiently in the Fourier domain. To handle challenges in vision such as discontinuities in images and high resolution inputs, AFNO proposes principled architectural modifications to FNO which results in memory and computational efficiency. This includes imposing a block diagonal structure on the channel mixing weights, adaptively sharing weights across tokens, and sparse frequency modes via soft-thresholding and shrinkage.
This tutorial presents the use of the AFNO transformer for modeling a PDE system. While AFNO has been designed for scaling to extremely high resolution inputs that the FNO cannot handle as well (see 2), here only a simple example using Darcy flow is presented. This problem is intended as an illustrative starting point for data-driven training using AFNO in Modulus but should not be regarded as leveraging the full extent of AFNO’s functionality.
This is an extension of the Darcy Flow with Fourier Neural Operator chapter. The unique topics you will learn in this tutorial include:
How to use the AFNO transformer architecture in Modulus
Differences between AFNO transformer and the Fourier Neural Operator
This tutorial assumes that you are familiar with the basic functionality of Modulus and understand the AFNO architecture. Please see the Introductory Example and Adaptive Fourier Neural Operator sections for additional information. Additionally, this tutorial builds upon the Darcy Flow with Fourier Neural Operator which should be read prior to this one.
The Python package gdown is required for this example if you do not already have the example data downloaded and converted.
Install using pip install gdown.
This problem develops a surrogate model that learns the mapping between a permeability and pressure field of a Darcy flow system. The mapping learned, \(\textbf{K} \nightarrow \textbf{U}\), should be true for a distribution of permeability fields \(\textbf{K} \sim p(\textbf{K})\) not a single solution. As discussed further in the Adaptive Fourier Neural Operator theory, the AFNO is based on an image transformer backbone. As with all transformer architectures, the AFNO tokenizes the input field. Each token is embedded from a patch of the image. The tokenized image is processed by the transformer layers followed by a linear decoder which generates the output image.
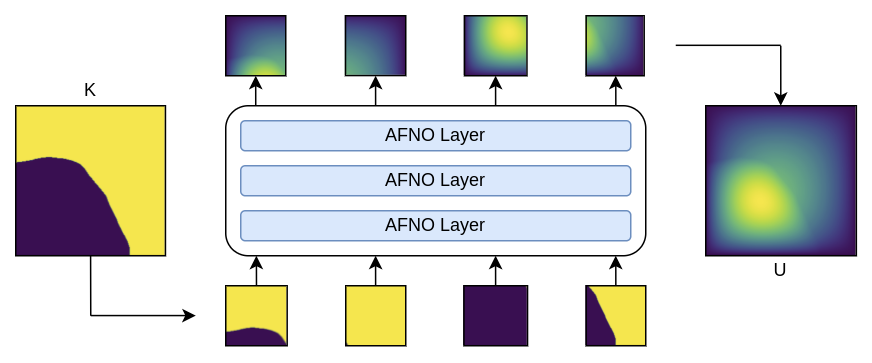
Fig. 82 AFNO surrogate model for 2D Darcy flow
Similar to the FNO chapter, the training and validation data for this example can be found on the Fourier Neural Operator Github page.
The example also includes an automated script for downloading and converting this dataset.
This requires the package gdown which can easily installed through pip install gdown.
The python script for this problem can be found at examples/darcy/darcy_afno.py.
Configuration
The AFNO is based on the ViT transformer architecture 3 and requires tokenization of the inputs.
Here each token is a patch of the image with a patch size defined in the configuration file through the parameter patch_size
The embed_dim parameter defines the size of the latent embedded features used inside the model for each patch.
defaults:
- modulus_default
- arch:
- afno
- scheduler: tf_exponential_lr
- optimizer: adam
- loss: sum
- _self_
arch:
afno:
patch_size: 16
embed_dim: 256
depth: 4
num_blocks: 8
scheduler:
decay_rate: 0.95
decay_steps: 1000
training:
rec_results_freq: 1000
max_steps: 10000
batch_size:
grid: 32
validation: 32
Loading Data
Loading both the training and validation datasets into memory follows a similar process as the Darcy Flow with Fourier Neural Operator example.
# load training/ test data
input_keys = [Key("coeff", scale=(7.48360e00, 4.49996e00))]
output_keys = [Key("sol", scale=(5.74634e-03, 3.88433e-03))]
download_FNO_dataset("Darcy_241", outdir="datasets/")
invar_train, outvar_train = load_FNO_dataset(
"datasets/Darcy_241/piececonst_r241_N1024_smooth1.hdf5",
[k.name for k in input_keys],
[k.name for k in output_keys],
n_examples=1000,
)
invar_test, outvar_test = load_FNO_dataset(
"datasets/Darcy_241/piececonst_r241_N1024_smooth2.hdf5",
[k.name for k in input_keys],
[k.name for k in output_keys],
n_examples=100,
)
The inputs for AFNO need to be perfectly divisible by the specified patch size (in this example patch_size=16), which is not
the case for this dataset. Therefore, trim the input/output features such that they are an appropriate dimensionality 241x241 -> 240x240.
# get training image shape
img_shape = [
next(iter(invar_train.values())).shape[-2],
next(iter(invar_train.values())).shape[-1],
]
# crop out some pixels so that img_shape is divisible by patch_size of AFNO
img_shape = [s - s % cfg.arch.afno.patch_size for s in img_shape]
print(f"cropped img_shape:{img_shape}")
for d in (invar_train, outvar_train, invar_test, outvar_test):
for k in d:
d[k] = d[k][:, :, : img_shape[0], : img_shape[1]]
print(f"{k}:{d[k].shape}")
Initializing the Model
Initializing the model and domain follows the same steps as in other examples. For AFNO, calculate the size of the domain after loading
the dataset. The domain needs to be defined in the AFNO model, which is provided with the inclusion of the keyword argument img_shape
in the instantiate_arch call.
# make list of nodes to unroll graph on
model = instantiate_arch(
input_keys=input_keys,
output_keys=output_keys,
cfg=cfg.arch.afno,
img_shape=img_shape,
)
nodes = [model.make_node(name="AFNO")]
Adding Data Constraints and Validators
Data-driven constraints and validators are then added to the domain. For more information, see the Darcy Flow with Fourier Neural Operator chapter.
# make domain
domain = Domain()
# add constraints to domain
supervised = SupervisedGridConstraint(
nodes=nodes,
dataset=train_dataset,
batch_size=cfg.batch_size.grid,
)
domain.add_constraint(supervised, "supervised")
# add validator
val = GridValidator(
nodes,
dataset=test_dataset,
batch_size=cfg.batch_size.validation,
plotter=GridValidatorPlotter(n_examples=5),
)
domain.add_validator(val, "test")
The training can now be simply started by executing the python script.
python darcy_AFNO.py
Training with model parallelism
With model parallelism, The AFNO model can be parallelized so multiple GPUs can split up and process even a single batch element in parallel. This can be very beneficial when trying to strong scale and get to convergence faster or to reduce the memory footprint of the model per GPU in cases where the activations and model parameters are too big to fit on a single GPU.
The python script for the model parallel version of this example is at examples/darcy/darcy_AFNO_MP.py. There are two main changes compared to the
standard AFNO example. The first is changing the model architecture from afno to distributed_afno in the config file.
defaults:
- modulus_default
- arch:
- distributed_afno
- scheduler: tf_exponential_lr
- optimizer: adam
- loss: sum
- _self_
arch:
distributed_afno:
patch_size: 16
embed_dim: 256
depth: 4
num_blocks: 8
scheduler:
decay_rate: 0.95
decay_steps: 1000
training:
rec_results_freq: 1000
max_steps: 10000
batch_size:
grid: 32
validation: 32
The second change is to set the MODEL_PARALLEL_SIZE environment variable to initialize the model parallel communication backend.
# Set model parallel size to 2
os.environ["MODEL_PARALLEL_SIZE"] = "2"
This configures the distributed AFNO model to use 2 GPUs per model instance. The number of GPUs to use can be changed as long as the following conditions are satisfied:
The total number of GPUs in the job must be an exact multiple of
MODEL_PARALLEL_SIZE,The
num_blocksparameter in the config must be an exact multiple ofMODEL_PARALLEL_SIZEandThe embedding dimension
embed_dimmust be an exact multiple ofMODEL_PARALLEL_SIZE.
Training the model parallel version of the example can then be launched using:
mpirun -np 2 python darcy_AFNO_MP.py
If running as root (typically inside a container), then OpenMPI requires adding a --allow-run-as-root option:
mpirun --allow-run-as-root -np 2 python darcy_AFNO_MP.py
Results and Post-processing
The checkpoint directory is saved based on the results recording frequency
specified in the rec_results_freq parameter of its derivatives. See Results Frequency for more information.
The network directory folder (in this case 'outputs/darcy_afno/validators') contains several plots of different
validation predictions.
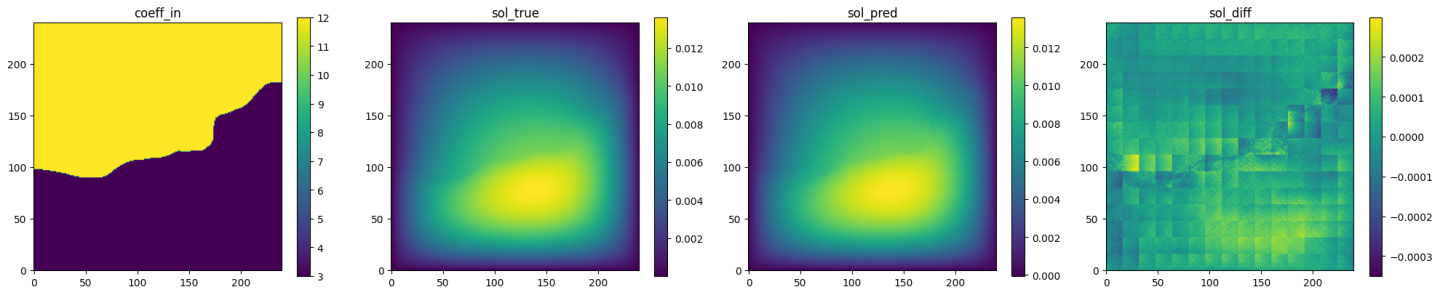
Fig. 83 AFNO validation prediction 1. (Left to right) Input permeability, true pressure, predicted pressure, error.
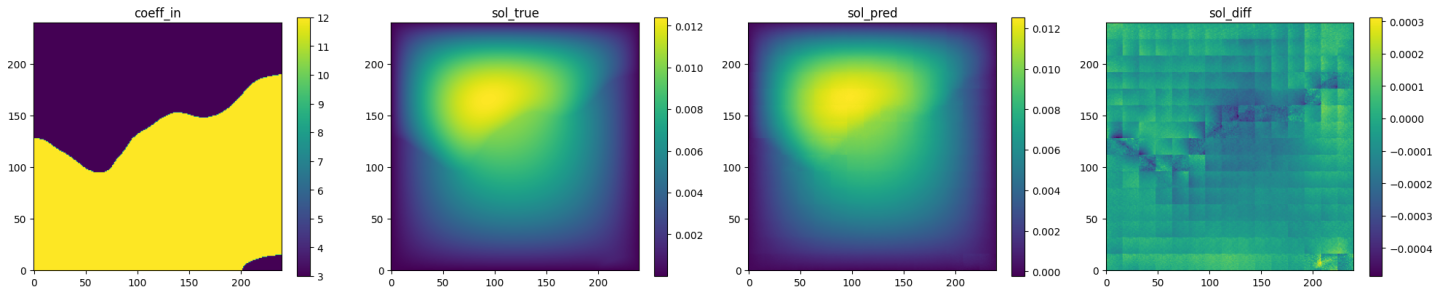
Fig. 84 AFNO validation prediction 2. (Left to right) Input permeability, true pressure, predicted pressure, error.
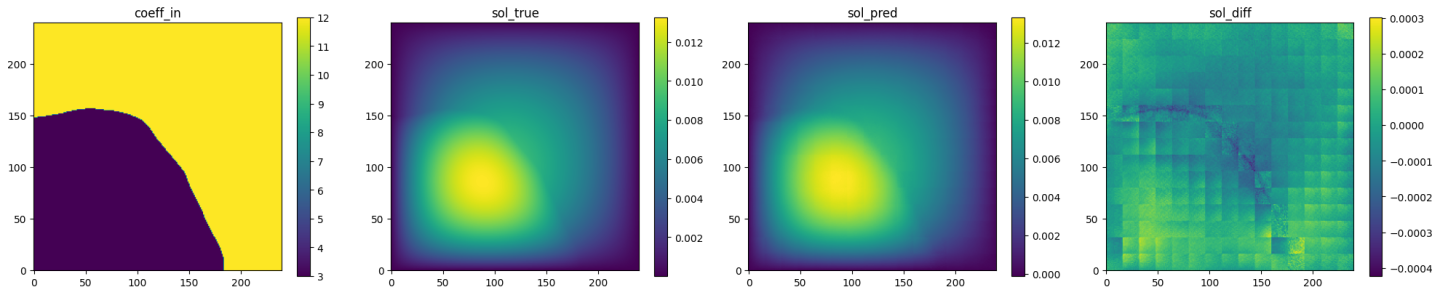
Fig. 85 AFNO validation prediction 3. (Left to right) Input permeability, true pressure, predicted pressure, error.
It is important to recognize that AFNO’s strengths lie in its ability to scale to a much larger model size and datasets than what is used in this chapter 1 2. While not illustrated here, this example demonstrates the fundamental implementation of data-driven training using the AFNO architecture in Modulus for users to extend to larger problems.
References
Guibas, John, et al. “Adaptive fourier neural operators: Efficient token mixers for transformers” International Conference on Learning Representations, 2022.
Pathak, Jaideep, et al. “FourCastNet : A global data-driven high-resolution weather model using adaptive Fourier neural operators” arXiv preprint arXiv:2202.11214 (2022).
Dosovitskiy, Alexey et al. “An image is worth 16x16 words: Transformers for image recognition at scale” arXiv preprint arXiv:2010.11929 (2020).