DPA All-to-all
NVIDIA DOCA DPA All-to-all Application Guide
This guide explains the all-to-all collective operation example when accelerated using the DPA in NVIDIA® BlueField®-3 DPU.
This example shows how the MPI all-to-all collective can be accelerated on the DPA. In an MPI collective, all processes in the same job call the collective routine.
Given a communicator of n ranks, the example performs a collective operation in which all the processes send and receive the same amount of data from all the processes (hence all-to-all).
This document describes how to run the all-to-all example using DOCA DPA.
All-to-all is a message passing interface (MPI) method. MPI is a standardized and portable message-passing standard designed to function on parallel computing architectures. An MPI program is one where several processes run in parallel.
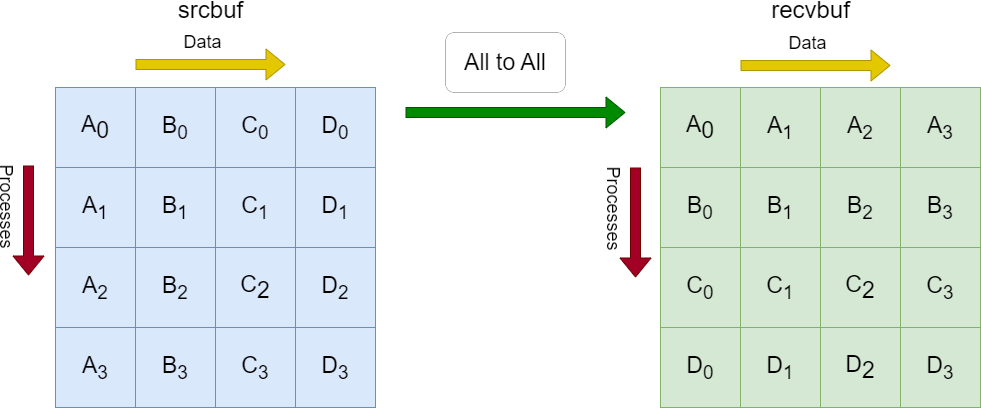
Each process in the diagram divides its local sendbuf into n blocks (4 in this example), each containing sendcount (4 in this example) elements. Process i sends the k-th block of its local sendbuf to process k which places the data in the i-th block of its local recvbuf.
Implementing the all-to-all method using DOCA DPA offloads the copying of the elements from the srcbuf to the recvbufs to the DPA, and leaves the CPU free to perform other computations.
The following diagram describes the differences between the host-based all-to-all and DPA all-to-all.
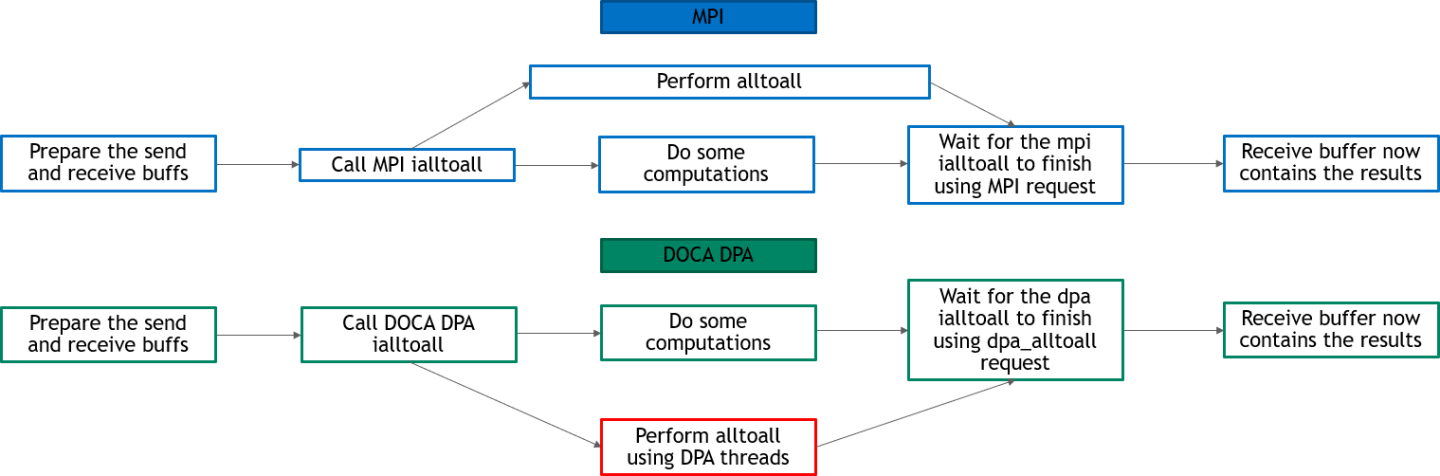
- In DPA all-to-all, DPA threads perform the all-to-all and the CPU is free to do other computations
- In host-based all-to-all, the CPU must still perform the all-to-all at some point and is not completely free for other computations
This section lists the application's configuration flow which includes different FlexIO functions and wrappers.
- Initialize MPI.
MPI_Init(&argc, &argv);
- Parse application argument.
- Initialize arg parser resources and register DOCA general parameters.
doca_argp_init();
- Register the application's parameters.
register_all_to_all_params();
- Parse the arguments.
doca_argp_start();
- The
msgsizeparameter is the size of the sendbuf and recvbuf (in bytes). It must be in multiples of an integer and at least the number of processes times an integer size. - The
devices_paramparameter is the names of the InfiniBand devices to use (must support DPA). It can include up to two devices names.
- The
- Only let the first process (of rank 0) parse the parameters to then broadcast them to the rest of the processes.
- Initialize arg parser resources and register DOCA general parameters.
- Check and prepare the needed resources for the
all_to_allcall:- Check the number of processes (maximum is 16).
- Check the
msgsize. It must be in multiples of integer size and at least the number of processes times integer size. - Allocate the sendbuf and recvbuf according to
msgsize.
- Prepare the resources required to perform the all-to-all method using DOCA DPA:
- Initialize DOCA DPA context:
- Open DOCA DPA device (DOCA device that supports DPA).
open_dpa_device();
- Create DOCA DPA context using the opened device.
doca_dpa_create();
- Open DOCA DPA device (DOCA device that supports DPA).
- Create the required events for the all-to-all: One completion event for the kernel launch (wait location CPU and update location DPA) and kernel events (wait location remote and update location DPA) as the number of processes.
create_dpa_a2a_events() { doca_dpa_event_create(doca_dpa, DOCA_DPA_EVENT_ACCESS_DPA, DOCA_DPA_EVENT_ACCESS_CPU, DOCA_DPA_EVENT_WAIT_DEFAULT, &comp_event, 0); for (i = 0; i < resources->num_ranks; i++) doca_dpa_event_create(doca_dpa, DOCA_DPA_EVENT_ACCESS_REMOTE, DOCA_DPA_EVENT_ACCESS_DPA, DOCA_DPA_EVENT_WAIT_DEFAULT, &(kernel_events[i]), 0); }
- Create DOCA DPA worker (for the endpoints).
doca_dpa_worker_create();
- Prepare DOCA DPA endpoints:
- Create DOCA DPA endpoints as the number of processes/ranks.
for (i = 0; i < resources->num_ranks; i++) doca_dpa_ep_create();
- Connect the local process' endpoints to the other processes' endpoints.
connect_dpa_a2a_endpoints();
- Export the endpoints to DOCA DPA device endpoints (so they can be used by the DPA) and copy them to DPA heap memory.
for (int i = 0; i < resources->num_ranks; i++) { result = doca_dpa_ep_dev_export(); doca_dpa_mem_alloc(); doca_dpa_h2d_memcpy(); }
- Create DOCA DPA endpoints as the number of processes/ranks.
- Prepare the memory required to perform the all-to-all method using DOCA DPA. This includes creating memory handlers for the sendbuf and recvbuf, getting the other processes' recvbufs handlers, and copying these memory handlers and their remote keys and the events' handlers to the DPA heap memory.
prepare_dpa_a2a_memory();
- Initialize DOCA DPA context:
- Launch the
alltoall_kernelusing DOCA DPA kernel launch with all the required parameters:- Every MPI rank launches a kernel of up to
MAX_NUM_THREADS. This example definesMAX_NUM_THREADSas 16. - Launch
alltoall_kernelusingkernel_launch.doca_dpa_kernel_launch();
- Using the
doca_dpa_dev_put_signal_nb()function, copy the relevant sendbuf to the correct recvbuf (according to the process' rank) for every OS process. Remember that multithreading is also used inside of the DPA threads.for (i = thread_rank; i < num_ranks; i += num_threads) doca_dpa_dev_put_signal_nb();
- Wait until the
alltoall_kernelhas finished.doca_dpa_event_wait_until();
Note:After the
alltoall_kernelis finished, the recvbuf of all the processes now contain the expected output of the all-to-all method.
- Every MPI rank launches a kernel of up to
- Destroy the
a2a_resources:- Free all the DOCA DPA memories.
doca_dpa_mem_free();
- Unregister all the DOCA DPA host memories.
doca_dpa_mem_unregister();
- Destroy all the DOCA DPA endpoints.
doca_dpa_ep_destroy();
- Destroy the DOCA DPA worker.
doca_dpa_worker_destroy();
- Destroy all the DOCA DPA events.
doca_dpa_event_destroy();
- Destroy the DOCA DPA context.
doca_dpa_destroy();
- Close the DOCA device.
doca_dev_close();
- Free all the DOCA DPA memories.
- Refer to the following documents:
- NVIDIA DOCA Installation Guide for Linux for details on how to install BlueField-related software.
- NVIDIA DOCA Troubleshooting Guide for any issue you may encounter with the installation, compilation, or execution of DOCA applications.
- NVIDIA DOCA Applications Overview for additional compilation instructions and development tips of DOCA applications.
- The
doca_dpa_all_to_allbinary is located under/opt/mellanox/doca/applications/dpa_all_to_all/bin/doca_dpa_all_to_all. To build all the applications together, run:cd /opt/mellanox/doca/applications/ meson build ninja -C build
- To build only the
dpa_all_to_allapplication:- Edit the following flags in
/opt/mellanox/doca/applications/meson_options.txt:- Set
enable_all_applicationstofalse - Set
enable_dpa_all_to_alltotrue
- Set
- Run the commands in step 2.
Note:
doca_dpa_all_to_allis created under./build/dpa_all_to_all/src/host/.
Application usage:
Usage: doca_dpa_all_to_all [DOCA Flags] [Program Flags] DOCA Flags: -h, --help Print a help synopsis -v, --version Print program version information -l, --log-level Set the log level for the program <CRITICAL=20, ERROR=30, WARNING=40, INFO=50, DEBUG=60> Program Flags: -m, --msgsize <Message size> The message size - the size of the sendbuf and recvbuf (in bytes). Must be in multiplies of integer size. Default is size of one integer times the number of processes. -d, --devices <IB device names> IB devices names that supports DPA, separated by comma without spaces (max of two devices). If not provided then a random IB device will be chosen.
- Edit the following flags in
- Pre-run setup:
- Make sure that MPI is installed in your setup (
openmpiis provided as part of thedoca-toolsmetapackage). Do not forget to update yourLD_LIBRARY_PATHand PATH environment variable to include MPI. For example, if MPI is installed under/usr/mpi/gcc/openmpi-4.1.5rc2/then run:export PATH=/usr/mpi/gcc/openmpi-4.1.5rc2/bin:$PATH export LD_LIBRARY_PATH=/usr/mpi/gcc/openmpi-4.1.5rc2/lib:$LD_LIBRARY_PATH
- Make sure that MPI is installed in your setup (
- CLI example for running the application. Remember, this is an MPI program, so use
mpirunto run the application (with the-npflag to specify the number of processes to run). The same command works for running the application on the host (x86) and the BlueField (Arm cores).- The following runs the DPA all-to-all application with 8 processes using the default message size (the number of processes, which is 8, times the size of 1 integer) with a random InfiniBand device:
mpirun -np 8 /opt/mellanox/doca/applications/dpa_all_to_all/bin/doca_dpa_all_to_all
- The following runs DPA all-to-all application with 8 processes, with 128 bytes as the message size and with
mlx5_0andmlx5_1as the IB devices:mpirun-np 8 /opt/mellanox/doca/applications/dpa_all_to_all/bin/doca_dpa_all_to_all -m 128 -d "mlx5_0,mlx5_1"
- The following runs the DPA all-to-all application with 8 processes using the default message size (the number of processes, which is 8, times the size of 1 integer) with a random InfiniBand device:
- To run
doca_all_to_all_dpausing a JSON file:doca_dpa_all_to_all --json [json_file]
cd /opt/mellanox/doca/applications/dpa_all_to_all/bin ./doca_dpa_all_to_all --json ./dpa_all_to_all_params.json
Refer to NVIDIA DOCA Arg Parser Programming Guide for more information.
| Flag Type | Short Flag | Long Flag/JSON Key | Description | JSON Content |
|---|---|---|---|---|
| General flags | l |
log-level |
Sets the log level for the application:
|
|
v |
version |
Prints program version information | N/A | |
h |
help |
Prints a help synopsis | N/A | |
| Program flags | m |
msgsize |
The message size. The size of the sendbuf and recvbuf (in bytes). Must be in multiples of an integer. The default is size of 1 integer times the number of processes. |
|
d |
device |
InfiniBand devices names that support DPA, separated by comma without spaces (max of two devices). If NOT_SET then a random InfiniBand device is chosen. |
|
Notice
This document is provided for information purposes only and shall not be regarded as a warranty of a certain functionality, condition, or quality of a product. NVIDIA Corporation nor any of its direct or indirect subsidiaries and affiliates (collectively: “NVIDIA”) make no representations or warranties, expressed or implied, as to the accuracy or completeness of the information contained in this document and assume no responsibility for any errors contained herein. NVIDIA shall have no liability for the consequences or use of such information or for any infringement of patents or other rights of third parties that may result from its use. This document is not a commitment to develop, release, or deliver any Material (defined below), code, or functionality.
NVIDIA reserves the right to make corrections, modifications, enhancements, improvements, and any other changes to this document, at any time without notice.
Customer should obtain the latest relevant information before placing orders and should verify that such information is current and complete.
NVIDIA products are sold subject to the NVIDIA standard terms and conditions of sale supplied at the time of order acknowledgement, unless otherwise agreed in an individual sales agreement signed by authorized representatives of NVIDIA and customer (“Terms of Sale”). NVIDIA hereby expressly objects to applying any customer general terms and conditions with regards to the purchase of the NVIDIA product referenced in this document. No contractual obligations are formed either directly or indirectly by this document.
NVIDIA products are not designed, authorized, or warranted to be suitable for use in medical, military, aircraft, space, or life support equipment, nor in applications where failure or malfunction of the NVIDIA product can reasonably be expected to result in personal injury, death, or property or environmental damage. NVIDIA accepts no liability for inclusion and/or use of NVIDIA products in such equipment or applications and therefore such inclusion and/or use is at customer’s own risk.
NVIDIA makes no representation or warranty that products based on this document will be suitable for any specified use. Testing of all parameters of each product is not necessarily performed by NVIDIA. It is customer’s sole responsibility to evaluate and determine the applicability of any information contained in this document, ensure the product is suitable and fit for the application planned by customer, and perform the necessary testing for the application in order to avoid a default of the application or the product. Weaknesses in customer’s product designs may affect the quality and reliability of the NVIDIA product and may result in additional or different conditions and/or requirements beyond those contained in this document. NVIDIA accepts no liability related to any default, damage, costs, or problem which may be based on or attributable to: (i) the use of the NVIDIA product in any manner that is contrary to this document or (ii) customer product designs.
No license, either expressed or implied, is granted under any NVIDIA patent right, copyright, or other NVIDIA intellectual property right under this document. Information published by NVIDIA regarding third-party products or services does not constitute a license from NVIDIA to use such products or services or a warranty or endorsement thereof. Use of such information may require a license from a third party under the patents or other intellectual property rights of the third party, or a license from NVIDIA under the patents or other intellectual property rights of NVIDIA.
Reproduction of information in this document is permissible only if approved in advance by NVIDIA in writing, reproduced without alteration and in full compliance with all applicable export laws and regulations, and accompanied by all associated conditions, limitations, and notices.
THIS DOCUMENT AND ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE. TO THE EXTENT NOT PROHIBITED BY LAW, IN NO EVENT WILL NVIDIA BE LIABLE FOR ANY DAMAGES, INCLUDING WITHOUT LIMITATION ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, PUNITIVE, OR CONSEQUENTIAL DAMAGES, HOWEVER CAUSED AND REGARDLESS OF THE THEORY OF LIABILITY, ARISING OUT OF ANY USE OF THIS DOCUMENT, EVEN IF NVIDIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. Notwithstanding any damages that customer might incur for any reason whatsoever, NVIDIA’s aggregate and cumulative liability towards customer for the products described herein shall be limited in accordance with the Terms of Sale for the product.
Trademarks
NVIDIA, the NVIDIA logo, and Mellanox are trademarks and/or registered trademarks of Mellanox Technologies Ltd. and/or NVIDIA Corporation in the U.S. and in other countries. The registered trademark Linux® is used pursuant to a sublicense from the Linux Foundation, the exclusive licensee of Linus Torvalds, owner of the mark on a world¬wide basis. Other company and product names may be trademarks of the respective companies with which they are associated.
Copyright
© 2023 NVIDIA Corporation & affiliates. All rights reserved.