Digital Fingerprinting (DFP)#
Overview#
Every account, user, service, and machine has a digital fingerprint that represents the typical actions performed and not performed over a given period of time. Understanding every entity’s day-to-day, moment-by-moment work helps us identify anomalous behavior and uncover potential threats in the environment.
To construct this digital fingerprint, we will be training unsupervised behavioral models at various granularities, including a generic model for all users in the organization along with fine-grained models for each user to monitor their behavior. These models are continuously updated and retrained over time, and alerts are triggered when deviations from normality occur for any user.
Running the DFP Example#
Instructions for building and running the DFP example are available in the examples/digital_fingerprinting/production/README.md guide in the Morpheus repository.
Training Sources#
The data we will want to use for the training and inference will be any sensitive system that the user interacts with, such as VPN, authentication and cloud services. The digital fingerprinting example (examples/digital_fingerprinting/production/README.md) included in Morpheus ingests logs from Azure Active Directory, and Duo Authentication.
The location of these logs could be either local to the machine running Morpheus, a shared file system like NFS, or on a remote store such as Amazon S3.
Defining a New Data Source#
Additional data sources and remote stores can easily be added using the Morpheus API. The key to applying DFP to a new data source is through the process of feature selection. Any data source can be fed into DFP after some preprocessing to get a feature vector per log/data point. In order to build a targeted model for each entity (such as user, service and machine), the chosen data source needs a field that uniquely identifies the entity we’re trying to model.
Adding a new source for the DFP pipeline requires defining five critical pieces:
The user ID column specified by the
morpheus.config.Config.ae.userid_column_nameconfiguration attribute. This can be any column which uniquely identifies the user, account or service being fingerprinted. Examples of possible user IDs could be:A username or full name (for example,
"johndoe"or"Jane Doe")User’s LDAP ID number
A user group (for example,
"sales"or"engineering")Host name of a machine on the network
IP address of a client
Name of a service (for example,
"DNS","Customer DB", or"SMTP")
The timestamp column specified by the
morpheus.config.Config.ae.timestamp_column_nameconfiguration attribute. The timestamp column needs to be converted to adatetimecolumn refer toDateTimeColumn.The model’s features as a list of strings specified by the
morpheus.config.Config.ae.feature_columnsconfiguration attribute, which should all be available to the pipeline after theDFPPreprocessingStage.A
DataFrameInputSchemafor theDFPFileToDataFrameStagestage.A
DataFrameInputSchemafor theDFPPreprocessingStage.
Production Deployment Example#
This example is designed to illustrate a full-scale, production-ready, DFP deployment in Morpheus. It contains all of the necessary components (such as a model store), to allow multiple Morpheus pipelines to communicate at a scale that can handle the workload of an entire company.
Key Features:
Multiple pipelines are specialized to perform either training or inference
Uses a model store to allow the training and inference pipelines to communicate
Organized into a docker-compose deployment for easy startup
Contains a Jupyter notebook service to ease development and debugging
Uses many customized stages to maximize performance.
This example is described in examples/digital_fingerprinting/production/README.md as well as the rest of this document.
DFP Features#
Azure Active Directory#
Feature |
Description |
|---|---|
|
for example, |
|
for example, |
|
for example, |
|
for example, |
|
for example, |
|
for example, |
|
|
|
country or region name |
|
city name |
Derived Features#
Feature |
Description |
|---|---|
|
tracks the number of logs generated by a user within that day (increments with every log) |
|
increments every time we observe a new city ( |
|
increments every time we observe a new app ( |
Duo Authentication#
Feature |
Description |
|---|---|
|
phone number |
|
for example, |
|
for example, |
|
|
|
reason for the results, for example, |
|
city name |
Derived Features#
Feature |
Description |
|---|---|
|
tracks the number of logs generated by a user within that day (increments with every log) |
|
increments every time we observe a new city ( |
High Level Architecture#
DFP in Morpheus is accomplished via two independent pipelines: training and inference. The pipelines communicate via a shared model store (MLflow), and both share many common components, as Morpheus is composed of reusable stages that can be easily mixed and matched.
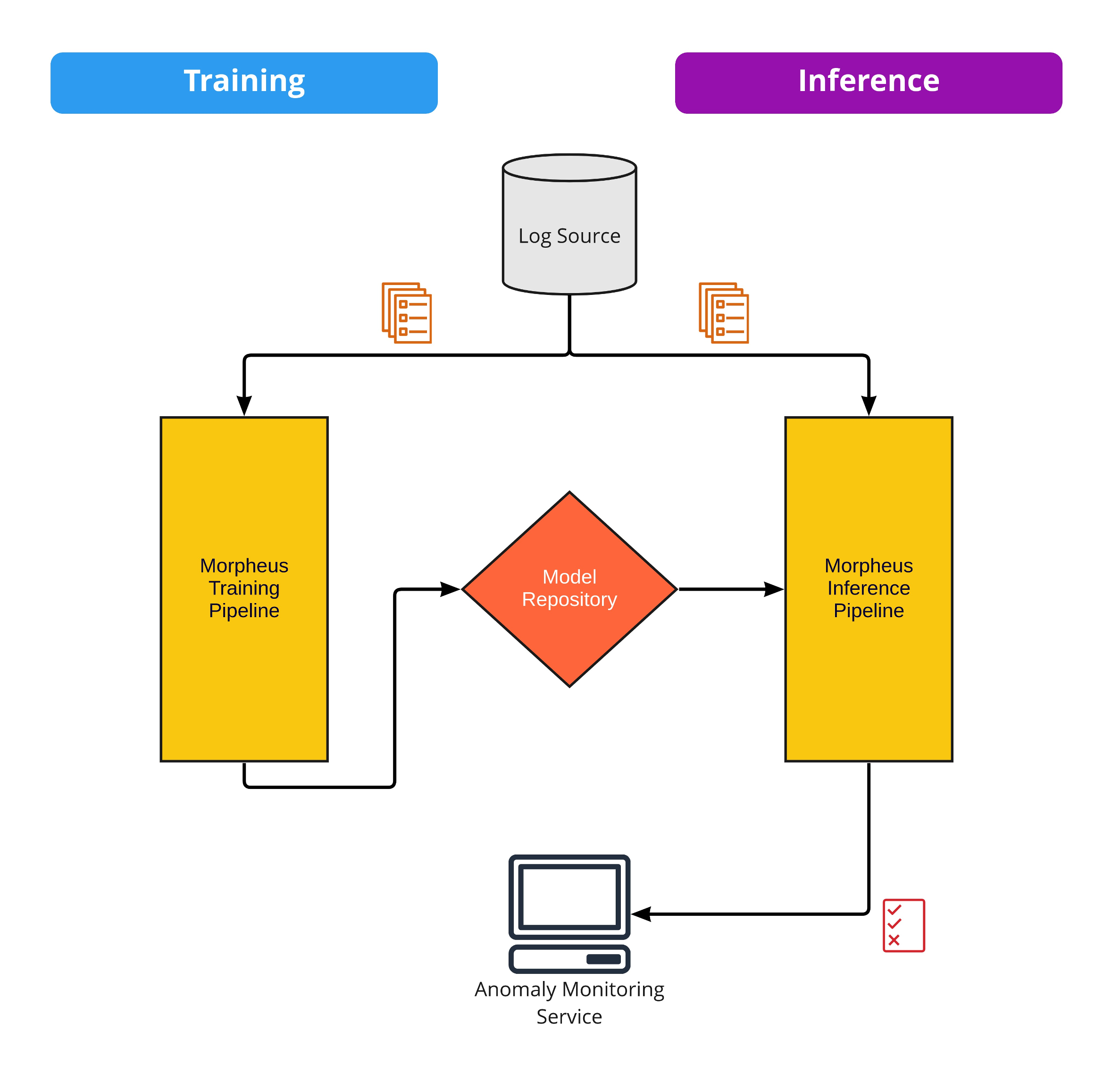
Training Pipeline#
Trains user models and uploads to the model store
Capable of training individual user models or a fallback generic model for all users
Inference Pipeline#
Downloads user models from the model store
Generates anomaly scores per log
Sends detected anomalies to monitoring services
Monitoring#
Detected anomalies are published to an S3 bucket, directory or a Kafka topic.
Output can be integrated with a monitoring tool.
Runtime Environment Setup#
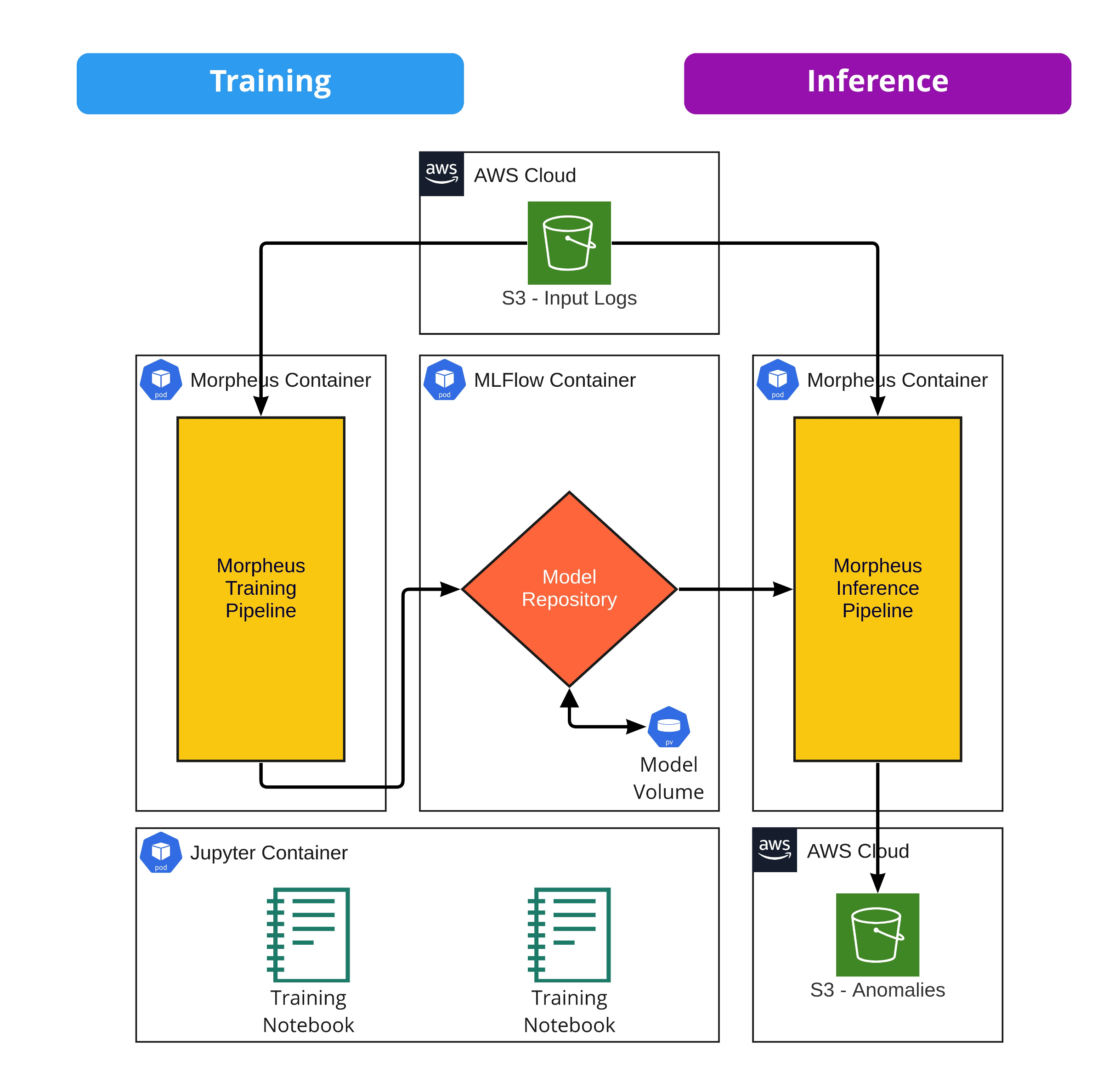
DFP in Morpheus is built as an application of containerized services and can be run using docker-compose for testing and development.
Services#
The reference architecture is composed of the following services:
Service |
Description |
|---|---|
|
MLflow provides a versioned model store |
|
Jupyter Server necessary for testing and development of the pipelines |
|
Used for executing both training and inference pipelines |
|
Downloads the example datasets for the DFP example |
Output Fields#
The output files will contain those logs from the input dataset for which an anomaly was detected; this is determined by the z-score in the mean_abs_z field. By default, any logs with a z-score of 2.0 or higher are considered anomalous. Refer to DFPPostprocessingStage.
Most of the fields in the output files generated by running the above examples are input fields or derived from input fields. The additional output fields are:
Field |
Type |
Description |
|---|---|---|
|
TEXT |
ISO 8601 formatted date string, the time the anomaly was detected by Morpheus |
|
TEXT |
Name and version of the model used to performed the inference, in the form of |
|
FLOAT |
Max z-score across all features |
|
FLOAT |
Average z-score across all features |
In addition to this, for each input feature the following output fields will exist:
Field |
Type |
Description |
|---|---|---|
|
FLOAT |
The loss |
|
FLOAT |
The loss z-score |
|
FLOAT |
The predicted value |
Refer to DFPInferenceStage for more on these fields.
Optional MLflow Service#
Starting the morpheus_pipeline or the jupyter service, will start the mlflow service in the background. For debugging purposes, it can be helpful to view the logs of the running MLflow service.
From the examples/digital_fingerprinting/production dir, run:
docker compose up mlflow
Customizing DFP#
For details on customizing the DFP pipeline refer to Digital Fingerprinting (DFP) Reference.