Sparse4D#
Model Card#
Sparse4D is an advanced 3D Multi-Camera Detection and Tracking Network. We specifically adapt Sparse4D for indoor environments such as warehouses with static camera setups. It generates precise 3D bounding boxes and tracking IDs for a diverse set of objects across multiple camera views. The included model in the Perception Microservice is pre-trained on the MTMC Tracking 2025 subset from the Nvidia PhysicalAI-SmartSpaces dataset.
The Sparse4D model card on NGC expands on data formats and evaluation methodology. TAO fine-tuning (BEV grouping, dataset conversion, training through export) lives in Sparse4D (TAO fine-tuning).
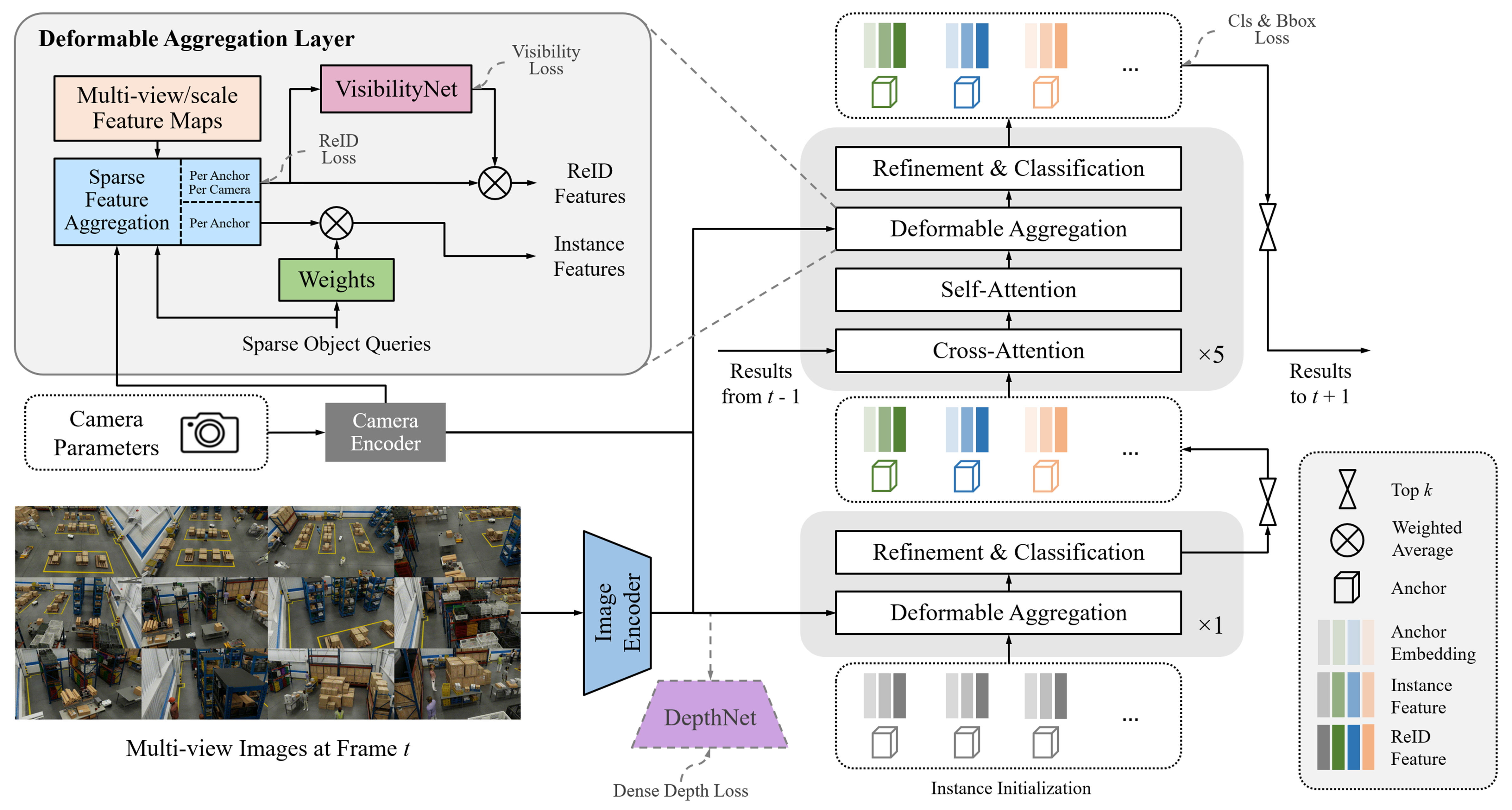
Inference using Perception Microservice#
Detailed information can be found in the 3D Multi Camera Detection and Tracking (Sparse4D) page.
Real-Time Inference Throughput & Latency#
Inference runs through the DeepStream pipeline on TensorRT with mixed precision (FP16+FP32). The TensorRT columns capture model-only latency, while the DeepStream columns add the instance-bank pre- and post-processing overhead. The table summarizes how many cameras each GPU supports at 30, 15, and 10 FPS. Numbers in bold are measured (all TensorRT values and some DeepStream values); DeepStream values not in bold are estimates based on the guidance that the DS microservice adds approximately 30% overhead over Sparse4D TensorRT model performance.
GPU |
TensorRT @30 FPS |
DeepStream @30 FPS |
TensorRT @15 FPS |
DeepStream @15 FPS |
TensorRT @10 FPS |
DeepStream @10 FPS |
|---|---|---|---|---|---|---|
1 x A100-SXM4-80GB |
12 |
9 |
27 |
20 |
42 |
32 |
1 x B200 |
72 |
55 |
100 |
77 |
100 |
77 |
1 x GB200 |
88 |
67 |
100 |
77 |
100 |
77 |
1 x H100 NVL - 94GB |
24 |
13 |
42 |
29 |
72 |
50 |
1 x H100 SXM HBM3 - 80GB |
24 |
13 |
56 |
39 |
88 |
61 |
1 x H200 |
24 |
13 |
64 |
44 |
98 |
68 |
1 x L4 - 24GB |
3 |
2 |
6 |
5 |
10 |
7 |
1 x L40 |
8 |
5 |
16 |
11 |
24 |
16 |
1 x L40S - 48GB |
10 |
7 |
22 |
15 |
32 |
23 |
1 x RTX 6000 ADA |
8 |
6 |
16 |
13 |
24 |
20 |
1 x RTX PRO 6000 Blackwell (Server) |
23 |
18 |
48 |
37 |
72 |
55 |
1 x RTX PRO 6000 Blackwell (Workstation) |
24 |
18 |
48 |
37 |
72 |
55 |
1 x IGX Thor - T7000 iGPU (no dGPU) |
4 |
2 |
8 |
4 |
14 |
9 |
1 x IGX Thor - T7000 dGPU - RTX PRO 6000 Blackwell Max-Q Workstation Edition |
12 |
8 |
28 |
19 |
42 |
29 |
1 x AGX Thor - T5000 |
4 |
2 |
8 |
5 |
14 |
9 |
1 x DGX Spark |
3 |
2 |
7 |
4 |
11 |
8 |
KPI#
The key performance indicator is Higher Order Tracking Accuracy (HOTA) per-class and the average HOTA obtained across all classes. We utilize the HOTA evaluation methodology to assess multi-object tracking accuracy.
Higher Order Tracking Accuracy (HOTA) is a metric that balances detection accuracy and association accuracy into a single unified score. It decomposes tracking performance into Detection Accuracy (DetA), which measures how well objects are localized, and Association Accuracy (AssA), which measures how well detections are linked over time into consistent tracks. HOTA is computed as the geometric mean of DetA and AssA, averaged over a range of localization thresholds. This provides a balanced, holistic measure of tracking quality that captures both spatial accuracy and temporal consistency.
The following scores are for models trained on MTMC Tracking 2025 subset. The evaluation set and training set is disjoint.
Object Class |
HOTA |
DetA |
AssA |
LocA |
|---|---|---|---|---|
Person |
50.03 |
44.91 |
57.00 |
68.14 |
Fourier_GR1_T2_Humanoid |
44.15 |
37.45 |
54.48 |
67.22 |
Agility_Digit_Humanoid |
54.59 |
51.98 |
58.89 |
68.54 |
Nova_Carter |
52.42 |
48.34 |
60.10 |
67.55 |
Transporter |
35.54 |
30.71 |
43.90 |
64.57 |
Forklift |
46.42 |
40.90 |
62.03 |
64.91 |
Average |
47.19 |
42.38 |
56.07 |
66.82 |
Results highlighted in the above table are for the latest model on the test set of the MTMC Tracking 2025 dataset. Please refer to the Model Card for more details.