Object Detection and Tracking#
Overview#
The Real Time Video Intelligence CV Microservice leverages NVIDIA DeepStream SDK to generate metadata for each stream that downstream microservices can use to generate spatial metrics and alerts.
The microservice features rtvi-cv-app, a DeepStream pipeline that builds on the built-in deepstream-test5 app in the DeepStream SDK. This RTVI-CV app provides a complete application that takes streaming video inputs, decodes the incoming streams, performs inference & tracking, and sends the metadata to other microservices using the defined Protobuf schema.
The Real Time Video Intelligence CV Microservice supports both 2D single-camera detection models (RT-DETR, Grounding DINO) for object detection and classification, as well as 3D multi-camera model (Sparse4D) for birds-eye-view detection and tracking. All the models are integrated within DeepStream pipelines, providing a complete streaming analytics solution for AI-based video understanding.
Key Features#
Real-time Performance: TensorRT/Triton-accelerated inference
Multi-model Support: Flexible architecture supporting different detection models
DeepStream Integration: Built on NVIDIA’s proven streaming analytics framework
Scalable Architecture: Handles multiple camera streams with batch processing
Standardized Output: Consistent metadata schema for downstream processing
Production-Ready: Configurable pipelines with comprehensive monitoring
Architecture#
The Real Time Video Intelligence Microservice follows a modular, pipeline-based architecture built on NVIDIA DeepStream SDK. The architecture supports both 2D single-camera and 3D multi-camera detection pipelines.

Core Components#
Video Source: Handles multiple RTSP streams, file inputs with dynamic stream add/remove capabilities
Stream Multiplexer (nvstreammux): Batches video frames from multiple sources for efficient GPU processing
Preprocessor: Hardware-accelerated image transformation, normalization, and augmentation using nvdspreprocess plugin
Inference Engine: Supports both TensorRT (nvinfer) and Triton Inference Server (nvinferserver) backends for model execution
Tracker: Multi-object tracker for maintaining object identities across frames
Metadata Generator: Converts detection outputs to standardized protobuf format
Message Broker: Kafka producer for streaming metadata to downstream microservices
Data Ingestion Formats Supported#
The following guidance applies to Real-Time Video Intelligence (RTVI) data paths. RT-CV (this microservice) is configured through NVIDIA DeepStream like the other RTVI services. Real-Time Embedding and Real-Time VLM also rely on DeepStream-accelerated decode and streaming internally; they do not ship the same open C-level application customization guide as RT-CV here—use Real-Time Embedding and Real-Time VLM for their APIs, compose settings, and RTSP-related environment variables.
Streaming protocols#
Reference VSS / RTVI deployments are configured for RTSP live ingest and for file- or URL-based video where each microservice documents those inputs. Anything else requires you to change the underlying DeepStream / GStreamer pipeline or to front the source with a gateway (for example remuxing to RTSP).
Supported out of the box (reference blueprint)#
RTSP is the primary live-ingest protocol used across the reference stack: RT-CV (DeepStream), Real-Time Embedding, and Real-Time VLM document RTSP URLs for live streams, and Video IO & Storage (VIOS) / NVStreamer serve test and demo content over RTSP. For DeepStream source configuration, see the DeepStream reference application — Source group.
File-based video (for example MP4 and other common multimedia container formats) is supported where each microservice documents file or URL inputs for batch or offline processing. Codec and multimedia container format considerations for DeepStream-backed paths are summarized under File-based video and codecs.
For additional streaming protocols (such as HLS and RTMP), see Supporting additional streaming protocols.
Supporting additional streaming protocols#
HLS, RTMP, and many other protocols are available through upstream GStreamer plugins (for example in gst-plugins-bad and related packages on a DeepStream image). The VSS blueprint does not ship compose profiles or API fields that accept HLS or RTMP URLs the same way as RTSP; you either insert the appropriate source and demux elements ahead of the DeepStream mux / inference path, or run a gateway that presents the stream as RTSP (or as a file) to the microservice.
Use the upstream plugin documentation when choosing elements and properties:
HLS — GStreamer HLS plugin and hlsdemux. Playlists are usually fetched over HTTP(S); souphttpsrc (or another network source) typically sits before the demuxer.
RTMP — rtmpsrc.
Extending RTVI microservices for custom ingestion#
When you need a non-reference protocol or a custom source graph:
RT-CV — Application-level customization (rebuild the DeepStream sample app, add or link GStreamer elements, and redeploy the container) is described under Application Customization.
Real-Time Embedding and Real-Time VLM — For HLS, RTMP, or other GStreamer-supported sources, plan on modifying or rebuilding the service image and its internal pipeline, or terminating to RTSP with your own gateway. Model and deployment tuning for Embedding is under Customizations on the Embedding page; VLM documents RTSP-related environment variables with its deployment settings.
Use the DeepStream SDK Developer Guide for pipeline and plugin details, and validate latency, reconnect behavior, codecs, and dependencies on your DeepStream and driver versions.
File-based video and codecs#
For RTVI microservices built on DeepStream, elementary streams are supported for H.264, H.265, JPEG, and MJPEG (see the DeepStream FAQ, including What types of input streams does DeepStream support?, for current SDK wording).
Those codecs are usually wrapped in common multimedia container formats such as MP4, MKV, and others. In general, multimedia container formats that GStreamer can autodetect and demux—typically via decodebin or an equivalent bin in your pipeline—work with the DeepStream SDK as long as the underlying video codec is one DeepStream supports and the rest of the pipeline matches your deployment.
Per-microservice APIs and compose profiles still define what each service accepts (file paths, URLs, RTSP-only live endpoints, and so on). See Real-Time Embedding, Real-Time VLM, and this Object Detection and Tracking guide for the inputs each exposes.
For live streaming protocols (RTSP versus optional HLS/RTMP via custom work), see Streaming protocols.
Models Supported#
The Real Time Video Intelligence CV Microservice supports both 2D single-camera and 3D multi-camera detection models:
2D Single-Camera Models:
Mask-Grounding-DINO (Smart City Blueprint): Open vocabulary multi-modal object detection model trained on commercial data with language grounding for zero-shot detection using natural language text prompts
RT-DETR (Smart City Blueprint): Object detection model included in the TAO Toolkit, transformer-based end-to-end detector optimized for real-time performance
RT-DETR (Warehouse Blueprint): Real-Time Detection Transformer object detection model optimized for warehouse environments
3D Multi-Camera Model:
Sparse4D (Warehouse Blueprint): Multi-Camera 3D Detection and Tracking model with 4D (spatial-temporal) capabilities for Birds-Eye-View (BEV) detection across multiple synchronized camera sensors with temporal instance banking
API Reference#
The Real Time Video Intelligence CV (RTVI-CV) Microservice exposes a REST API for stream management, health checks, metrics, and AI/ML operations.
For complete API documentation, including all endpoints, request/response schemas, and interactive examples, see the Object Detection and Tracking API Reference.
API categories:
Health Check — Liveness, readiness, and startup probes (Kubernetes-compatible)
Stream Management — Add, remove, and query video streams dynamically
Monitoring — Metrics and telemetry with Prometheus and OpenTelemetry support
Metadata — Service version and license information
AI/ML Operations — Text embedding generation and other ML capabilities * Text embeddings —
POST /api/v1/generate_text_embeddingsto generate vector embeddings from text
All endpoints are prefixed with /api/v1. Base URL: http://<host>:9000.
ReID and Embeddings (REST API and Config Reference)#
For an end-to-end guide to fine-tuning RADIO-CLIP (and SigLIP 2) with TAO and swapping ONNX or TensorRT artifacts into this microservice, see Model customization overview and RADIO-CLIP object embeddings.
This section describes deployment, features, configuration, and REST APIs for text embeddings, object embeddings (vision encoder), adding video streams by URL, and attaching timestamps from the API payload.
Supported Models#
Component – Model mapping#
Component |
Models |
Backend |
|---|---|---|
Vision Encoder (RT-Embedding) |
RADIO-CLIP / SigLIP V2-SO400M-P16-256 |
TensorRT |
Text Embedder |
SigLIP2 (ONNX) / SigLIP2-giant |
ONNX Runtime |
Embedding NIM |
Combined ONNX Models (Image + Text)#
Both models below are exported as combined CLIP-style ONNX files containing image and text encoders in a single graph. The plugins automatically extract the relevant subgraph (image-only for vision encoder, text-only for text embedder).
Model |
Type |
Image Size |
Text Max Length |
Embedding Dim |
Tokenizer |
Extra Inputs |
|---|---|---|---|---|---|---|
RADIO-CLIP |
RADIO-CLIP (combined image+text) |
224x224 |
77 |
1024 |
CLIPTokenizer (BPE) |
|
SigLIP2 |
SigLIP V2-SO400M-P16-256 |
256x256 |
64 |
1152 |
GemmaTokenizer (SentencePiece) |
|
Model downloads (NGC) – deployable ONNX#
Model |
NGC Registry |
|---|---|
RADIO-CLIP |
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/models/radio-clip |
SigLIP v2 |
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/tao/models/siglip_v2 |
Features added#
Text embeddings using RADIO-CLIP ONNX or SigLIP2 ONNX (config + REST API).
Object embeddings using RADIO-CLIP / SigLIP2 (vision encoder plugin with TensorRT).
Combined ONNX model support – a single ONNX file serves both image and text embeddings; the plugins automatically extract the relevant subgraph.
Add file video URL via curl, including support for creation time of the file URL (see stream add API and streammux config below).
Text embedder (config)#
Enable the text embedder in your config file. The model-name property selects the encoder backend.
RADIO-CLIP ONNX – recommended#
Uses local ONNX Runtime inference with a CLIPTokenizer. No PyTorch or HuggingFace download required. Uses model-name=siglip2-onnx with RADIO-CLIP model and tokenizer paths.
[text-embedder]
enable=1
model-name=siglip2-onnx
onnx-model-path=radio-clip_v1.0.onnx
tokenizer-dir=radio-clip_v1.0_tokenizer/
SigLIP2 ONNX – recommended#
Uses local ONNX Runtime inference with a GemmaTokenizer. No PyTorch or HuggingFace download required.
[text-embedder]
enable=1
model-name=siglip2-onnx
onnx-model-path=siglip2_v1.0.onnx
tokenizer-dir=siglip2_v1.0_tokenizer/
Text embedder property reference#
Property |
Description |
|---|---|
``enable`` |
Enable the text embedder (1 = on, 0 = off). |
``model-name`` |
Use |
``onnx-model-path`` |
Path to the combined ONNX model file (required for |
``tokenizer-dir`` |
Path to the tokenizer directory containing |
Generate text embeddings (curl)#
Endpoint: POST http://localhost:9000/api/v1/generate_text_embeddings
Example:
curl -XPOST http://localhost:9000/api/v1/generate_text_embeddings -d '{
"text_input": "Hello, world!",
"model": ""
}'
Field |
Description |
|---|---|
|
Input text to embed |
|
Currently don’t care – can be left empty. Reserved for future use. |
Video URL – add stream (curl)#
Endpoint: POST http://localhost:9000/api/v1/stream/add
Use this to register a video URL for download and add it as a stream. The payload can include creation_time; to use it as the stream timestamp, set [streammux] attach-sys-ts-as-ntp=0 (see section below).
Example:
curl -XPOST 'http://localhost:9000/api/v1/stream/add' -d '{
"key": "sensor",
"value": {
"camera_id": "uniqueSensorID1",
"camera_name": "front_door",
"camera_url": "http://localhost:30000/sample_720p.mp4",
"creation_time": "2024-12-12T18:32:11.123Z",
"change": "camera_add",
"metadata": {
"resolution": "1920 x1080",
"codec": "h264",
"framerate": 30
}
},
"headers": {
"source": "vst",
"created_at": "2021-06-01T14:34:13.417Z"
}
}'
Field |
Description |
|---|---|
|
e.g. |
|
Unique sensor/stream identifier |
|
Human-readable name (e.g. front_door) |
|
Video URL to download and add as stream |
|
Timestamp (e.g. ISO 8601); used when attaching ts from payload (see section below) |
|
e.g. |
|
Optional (resolution, codec, framerate, etc.) |
|
Optional request metadata |
Attach creation_time (base time of files) from REST API as timestamp (config)#
To use the ``creation_time`` from the REST API payload (e.g. from /api/v1/stream/add) as the stream timestamp instead of system/NTP time:
[streammux]
attach-sys-ts-as-ntp=0
``attach-sys-ts-as-ntp=0`` – use the timestamp provided in the REST API payload (e.g.
creation_time).``attach-sys-ts-as-ntp=1`` (default) – use system/NTP timestamp.
Ensure the stream-add payload includes a valid creation_time when using this option.
Vision encoder plugin (config)#
The vision encoder plugin generates object embeddings (e.g. for ReID) using a TensorRT engine built from an ONNX model.
Combined ONNX model support: When a combined image+text ONNX model (e.g. RADIO-CLIP or SigLIP2) is provided, the TensorRT engine builder automatically:
Detects multiple outputs and prunes to
image_embeddingonly.TensorRT’s dead code elimination removes the entire text encoder.
Extra text inputs (
input_ids,attention_mask) are bound with zero-filled buffers.
This means you can use the same ONNX file for both [visionencoder] (image embeddings via TRT) and [text-embedder] (text embeddings via ONNX Runtime).
Example: RADIO-CLIP#
[visionencoder]
enable=1
onnx-model=radio_clip_v1.0.onnx
tensorrt-engine=radio_clip_v1.0.engine
batch-size=16
min-crop-size=32
gpu-id=0
skip-interval=3
Property reference#
Property |
Description |
|---|---|
``enable`` |
Enable the vision encoder plugin (1 = on, 0 = off). |
``tensorrt-engine`` |
Path to the TensorRT engine file. If not present, the engine is built automatically from the ONNX model. |
``onnx-model`` |
Path to the ONNX model file. The same directory must contain the external weights |
``batch-size`` |
Batch size for TensorRT engine build and inference. |
``min-crop-size`` |
Minimum crop size (width/height in pixels) for embedding generation; objects smaller than this are skipped. |
``skip-interval`` |
Embedding generation at configurable frame intervals. |
``embedding-classes`` |
Configurable classes for embedding (e.g. |
``gpu-id`` |
GPU device ID to use. |
Example: SigLIP2#
[visionencoder]
enable=1
onnx-model=siglip2_v1.0.onnx
batch-size=16
min-crop-size=32
gpu-id=0
skip-interval=3
Note: Image normalization is auto-detected from the ONNX model path: [0, 1] for RADIO-CLIP, [-1, 1] when the path contains siglip.
Combined ONNX model deployment#
Required files#
Each combined ONNX model requires three components in the same directory:
File |
Description |
|---|---|
|
Model graph (small, ~1 MB) |
|
External weights (large, ~1-4 GB). The filename must match what the ONNX references internally. |
|
Tokenizer directory containing |
Engine rebuild#
When switching ONNX models, delete the existing .engine / .plan file and its .meta sidecar so the TensorRT engine is rebuilt with the correct output pruning:
rm -f model.plan model.plan.meta
The engine will be automatically rebuilt on next launch.
Deployment#
IGX Thor: VIC clocks for best performance
For IGX Thor, VIC clocks need to be boosted for best performance and latency. Run the following before deployment:
sudo nvpmodel -m 0
sudo jetson_clocks
sudo su
# Run the following in the root shell (after sudo su):
echo performance > /sys/class/devfreq/8188050000.vic/governor
1. Blueprint Deployment
For warehouse deployment, refer Warehouse Quickstart Guide For smart city deployment, refer Smart City Quickstart Guide
2. Verify Deployment
Check service health:
# Check liveness
curl http://localhost:<port>/api/v1/live
# Check readiness
curl http://localhost:<port>/api/v1/ready
# Check startup
curl http://localhost:<port>/api/v1/startup
# Get stream information
curl http://localhost:<port>/api/v1/stream/get-stream-info
# Monitor metrics
curl http://localhost:<port>/api/v1/metrics
3. Monitor Output
View detection metadata in Kafka topic or check logs for the service:
docker-compose logs -f <rtvi-cv-service-name>
4. TensorRT Engine File Creation and Reuse
On the first run, TensorRT automatically builds optimized engine files (.engine) from the ONNX models. This engine generation can take significant time depending on the model size and GPU. The engine files are stored inside the container’s storage volume (/opt/storage/ for 2D, /opt/storage/ for 3D).
The engine files are automatically retained across Docker restarts via the mounted storage volume, so subsequent restarts will reuse the previously built engines without rebuilding.
Note
If the Docker volumes are removed, the engine files will be deleted and TensorRT will rebuild them on the next run.
Reusing engines with custom models:
When deploying a custom ONNX model (e.g. a fine-tuned RT-DETR or Sparse4D checkpoint), the engine file from the first run is retained in the storage volume. To mount a custom pre-built engine file, add a volume entry to the corresponding Docker Compose file:
Warehouse 2D Blueprint — deployments/warehouse/warehouse-2d-app/warehouse-2d-app.yml (perception-2d service, volumes: section):
volumes:
# ... existing volume mounts ...
- $MDX_DATA_DIR/models/mtmc/rtdetr_warehouse_v1.0.fp16.onnx_b3_gpu0_fp16.engine:/opt/storage/rtdetr_warehouse_v1.0.fp16.onnx_b3_gpu0_fp16.engine
Warehouse 3D Blueprint — deployments/warehouse/warehouse-3d-app/warehouse-3d-app.yml (perception-3d service, volumes: section):
volumes:
# ... existing volume mounts ...
- $MDX_DATA_DIR/models/sparse4d/ov/model.engine:/opt/storage/model.engine
Note
The engine file name must be preserved exactly as the blueprint expects it. For Warehouse 2D, the PGIE config references
rtdetr_warehouse_v1.0.fp16.onnx_b3_gpu0_fp16.engineat/opt/storage/(defined inds-ppl-analytics-pgie-config.yml). For Warehouse 3D, the inference config referencesmodel.engineat/opt/storage/(defined inconfig.yaml). When mounting a custom engine, ensure the file name and path match these config entries, or update the config files accordingly.Engine files are tied to the GPU architecture and TensorRT version they were built on. If you change GPU hardware or update TensorRT, delete the mounted engine files and allow the application to rebuild them.
When switching to a different ONNX model, remove the previously mounted
.enginefile so TensorRT rebuilds it for the new model.Whenever changing to a newer custom model, ensure the earlier engine file(s) are deleted from the storage volume so that TensorRT generates a fresh engine for the new model.
2D Single Camera Detection and Tracking#
2D models perform object detection and classification on individual camera streams, providing accurate bounding box predictions and class labels in image coordinates. These models are ideal for single-camera applications requiring high-accuracy object detection.
DeepStream Pipeline
The diagram below shows the RTVI-CV pipeline used for 2D single camera detection and tracking.
The VSS platform supports multiple 2D detection models, each optimized for different use cases:
RT-DETR: Transformer-based end-to-end detector
Grounding DINO: Zero-shot detector with language grounding for open-vocabulary detection
RT-DETR Detector RTVI-CV Pipeline#
The RT-DETR (Real-Time Detection TRansformer) detector pipeline is based on the deepstream-test5 app in the DeepStream SDK. The app takes streaming video inputs, decodes the incoming stream, performs inference & tracking, and lastly sends metadata over Kafka to other Metropolis Microservices, using the defined Protobuf schema.
RT-DETR is a transformer-based end-to-end object detector optimized for real-time performance. A finetuned RT-DETR model for warehouse blueprint is mounted at /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app/models/mtmc/rtdetr_detection_aic25v0.41_openimages_ytcc_moving_classes_iter_012_v0.7.onnx. The model supports the following classes: Person, Agility_Digit_Humanoid, Fourier_GR1_T2_Humanoid, Nova_Carter, Transporter, Forklift, and Pallet.
A finetuned RT-DETR model for smartcity blueprint is mounted at /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app/models/rtdetr-its/model_epoch_035.onnx. The model supports the following classes: background, two_wheeler, Vehicle, Person, and road_sign.
Configuration Options
The RT-DETR Detector RTVI-CV Pipeline has several key configuration options:
Sources: To change input source type and number of channels, refer to:
Source Group for offline configuration
RTVI-CV microservice API for dynamic configuration
PGIE: To change AI model, batch size, and model parameters, refer to the Primary and Secondary GIE Group and the Gst-nvinfer plugin
Tracker: To change Multi-Object Tracker parameters, refer to the Gst-nvtracker and the NvMultiObjectTracker Parameter Tuning Guide
Message Broker: To change Message Broker parameters, refer to the Gst-nvmsgbroker
Grounding DINO Detector RTVI-CV Pipeline#
The Grounding DINO detector pipeline is based on the deepstream-test5 app in the DeepStream SDK. The app takes streaming video inputs, decodes the incoming stream, performs inference & tracking, and lastly sends metadata over Kafka to other Metropolis Microservices, using the defined Protobuf schema.
Grounding DINO is a zero-shot object detection model that combines vision and language understanding to detect objects based on free-form text descriptions (prompts). The implementation uses the DeepStream Triton Inference Server plugin (Gst-nvinferserver) with a custom processing library for text prompt support and optional instance segmentation masks. The app is enabled with PGIE (Primary GPU Inference Engines), NVDCF/DeepSORT tracker and message broker for sending metadata to Kafka.
Configuration Options
The Grounding DINO Detector RTVI-CV Pipeline has several key configuration options:
Sources: To change input source type and number of channels, refer to:
Source Group for offline configuration
RTVI-CV microservice API for dynamic configuration
PGIE: The implementation uses Triton Inference Server backend via the Gst-nvinferserver plugin. To change AI model, batch size, and model parameters, refer to the Primary and Secondary GIE Group
Tracker: To change Multi-Object Tracker parameters, refer to the Gst-nvtracker and the NvMultiObjectTracker Parameter Tuning Guide
Message Broker: To change Message Broker parameters, refer to the Gst-nvmsgbroker
Text Prompt Configuration#
Labels for Grounding DINO are defined in the nvinferserver configuration file (config_triton_nvinferserver_gdino.txt) in the postprocess section. The text prompts enable zero-shot detection of objects using natural language descriptions.
postprocess {
other {
type_name: "Car . Truck . Bus . Motorcycle . Bicycle . Scooter . Emergency Vehicle . Vehicle . Person . ;0.4"
}
}
Prompt Syntax:
Use periods (
.) followed by spaces (” . “) to separate multiple objectsAdd a semicolon (
;) followed by confidence threshold (e.g.,;0.4for 40% confidence)Descriptive phrases enable fine-grained detection (e.g., “person wearing helmet”)
Case-insensitive processing
The threshold value filters detections below the specified confidence level
3D Multi Camera Detection and Tracking#
The 3D pipeline performs object detection and tracking across multiple synchronized camera streams using Sparse4D, a Birds-Eye-View (BEV) detection model. It maintains object identity across frames through temporal tracking with instance banking, providing 3D position, orientation, velocity, and persistent instance IDs for each detected object.
The pipeline ingests multicamera video streams, processes them through calibrated projection matrices for spatial alignment, and utilizes a feedback mechanism with temporal instance banking to maintain object identity across frames. Detection results include 3D position, orientation, velocity, and instance IDs, enabling sophisticated multi-camera fusion capabilities.
The processed metadata follows DeepStream’s standardized message format and transmits via Kafka brokers for downstream applications such as Multi-Camera Tracking (MCT), Real-Time Location Systems (RTLS), and Facility Safety Logic (FSL). The entire pipeline optimizes for real-time performance with TensorRT acceleration (FP16/FP32) and configurable batch processing, making it ideal for complex spatial understanding in applications like warehouse automation and traffic monitoring.
DeepStream Pipeline
The diagram below shows the RTVI-CV pipeline used for 3D multi camera detection and tracking.
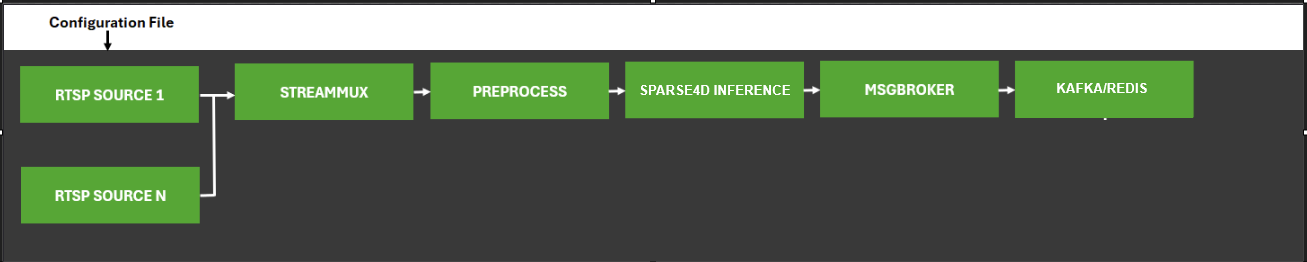
Sparse4D RTVI-CV Pipeline#
The Sparse4D RTVI-CV pipeline is based on the deepstream-test5 app in the DeepStream SDK. The app takes streaming video inputs from multiple synchronized camera streams, decodes the incoming streams, performs 3D inference & temporal tracking using instance banking, and sends metadata over Kafka to other Metropolis Microservices, using the defined Protobuf schema.
Sparse4D is a Birds-Eye-View (BEV) detection model that performs 3D object detection and tracking across multiple synchronized camera sensors. The model maintains object identity across frames through temporal tracking with instance banking, providing 3D position, orientation, velocity, and persistent instance IDs for each detected object.
Configuration Options
The Sparse4D RTVI-CV Pipeline has several key configuration options:
Inference Configuration: To configure model inference parameters, calibration settings, preprocessing properties, instance bank properties, decoder properties, and debugging options, refer to the Inference Configuration File section.
DeepStream Configuration: To change input source type, number of channels, stream multiplexing, and message broker settings, refer to:
Source Group for offline configuration
RTVI-CV microservice API for dynamic configuration
DeepStream SDK Documentation for complete configuration options
Preprocessing: To configure preprocessing operations such as resizing, scaling, cropping, format conversion, and normalization, refer to the DeepStream Preprocessing Plugin Documentation and the Preprocess Plugin Configuration File section.
Message Broker: To change Message Broker parameters, refer to the Gst-nvmsgbroker
Runtime Configuration: For common configuration adjustments such as modifying the number of input streams or integrating a new Sparse4D model checkpoint, refer to the Modifying the Number of Input Streams and Integrating a Sparse4D Model Checkpoint sections in the 3D Multi Camera Detection and Tracking (Sparse4D) documentation.
Implementation Details#
Since the application is built using DeepStream SDK deepstream-test5-app, refer to the following documentation for more details:
Kafka Integration#
The Real Time Video Intelligence CV Microservice publishes detection and tracking metadata to Kafka for downstream processing by other microservices such as Multi-Camera Tracking (MCT), Real-Time Location Systems (RTLS), and Facility Safety Logic (FSL).
Kafka Topics
The microservice publishes messages to configurable Kafka topics. By default, detection metadata is sent to the deepstream-metadata topic.
Configuration
Configure Kafka integration in the DeepStream application configuration file:
[message-broker]
enable=1
broker-proto-lib=/opt/nvidia/deepstream/deepstream/lib/libnvds_kafka_proto.so
broker-conn-str=kafka-broker:9092
topic=deepstream-metadata
comp-id=perception-app
Message Formats#
Detection and tracking metadata is serialized as Protocol Buffer messages using the Frame message type defined in the Protobuf Schema.
Message Header:
message_type:
"frame"(default, if not specified)
Message Structure:
Key Fields:
Frame message:
version: Schema version
id: Frame identifier
timestamp: Frame timestamp in UTC format
sensorId: Camera/sensor identifier
objects: Array of detected objects with bounding boxes, classifications, tracking IDs, and attributes
info: Additional metadata (key-value pairs)
Object message:
id: Object tracking ID
bbox: Bounding box coordinates (leftX, topY, rightX, bottomY) for 2D detection
bbox3d: 3D bounding box coordinates for Sparse4D detection
type: Object class (e.g., Person, Vehicle, Forklift)
confidence: Detection confidence score
coordinate: 3D position (x, y, z) for Sparse4D detection
speed: Object velocity for Sparse4D tracking
dir: Movement direction vector for Sparse4D tracking
info: Additional object attributes
DeepStream Configuration Files#
The following table lists the DeepStream configuration files for different blueprint deployments. These configurations define the pipeline behavior, model parameters, and integration settings for 2D and 3D computer vision models.
DeepStream configuration files are present in RTVI-CV Docker at below mentioned locations.
Smart City Blueprint#
Configuration Location: deployments/smartcities/smc-app/deepstream/configs/
Configuration File |
Description |
|---|---|
|
Primary GIE (PGIE) configuration for RT-DETR |
|
Main DeepStream pipeline configuration for RT-DETR & Grounding DINO |
|
Triton inference server configuration for Grounding DINO model |
Note: Few config parameters are updated dynamically based on the model name and number of streams.
Warehouse 2D Blueprint#
Please refer to the Warehouse 2D Blueprint documentation for configurations.
Warehouse 3D Blueprint#
Please refer to the Warehouse 3D Blueprint documentation for configurations.
Customization of Microservice#
The microservice provides flexible customization options to adapt to different deployment requirements, models, and use cases. This section describes the key customization areas.
Model Customization#
Updating Model Checkpoints for provided models
The microservice supports RT-DETR and Grounding DINO detection models for 2D object detection:
For custom 2D detection models (RT-DETR and Grounding DINO) trained with TAO Toolkit:
Export your model to ONNX format using TAO
Update deepstream application configuration file to reference your model:
[primary-gie]
model-engine-file=<custom_model_name_b4_gpu0_fp16>.engine
onnx-file=<custom_model_name>.onnx
batch-size=4 # set to the batch size of your model
Update the PGIE configuration file (nvinfer or nvinferserver ) for your custom model in the deepstream application configuration file.
For integrating custom model architectures (beyond RT-DETR and Grounding DINO), you will need to export your model to ONNX format, configure the DeepStream nvinfer plugin with appropriate preprocessing and parsing parameters, and potentially implement custom bounding box parsers. Refer to the DeepStream nvinfer Plugin Guide for detailed integration steps.
For 3D object detection models, refer to the Integrating a Sparse4D Model Checkpoint section in the 3D Multi Camera Detection and Tracking (Sparse4D) documentation.
Tracker Customization#
Tracker Selection and Configuration
DeepStream supports multiple tracking algorithms. You can configure tracker section in the deepstream application configuration file as per your requirements. For example:
[tracker]
enable=1
tracker-width=640
tracker-height=384
ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.so
ll-config-file=config_tracker_NvDCF_perf.yml
display-tracking-id=1
Tracker Algorithm Options
NvDCF: Discriminative Correlation Filter (recommended for most use cases)
IOU: Intersection over Union tracker (lightweight, best for static cameras)
DeepSORT: Deep learning-based tracker (best accuracy, higher compute)
Note
Known Limitation (NvDCF Tracker): Each VPI™ backend low-level tracker library supports at most 128 streams. When running more than 128 streams, configure sub-batching to run multiple instances of the low-level tracker library. Refer to the DeepStream nvtracker sub-batching documentation for details.
For detailed tracker configuration options, parameters, and algorithm-specific settings, refer to the Gst-nvtracker Plugin Documentation.
Message Broker Customization#
Kafka Configuration
Customize message broker output in the deepstream application configuration file:
[message-broker]
enable=1
broker-proto-lib=/opt/nvidia/deepstream/deepstream/lib/libnvds_kafka_proto.so
broker-conn-str=kafka-broker:9092
topic=deepstream-metadata
comp-id=perception-app
Redis Configuration
For Redis message broker, use the deepstream application configuration file:
[message-broker]
enable=1
broker-proto-lib=/opt/nvidia/deepstream/deepstream/lib/libnvds_redis_proto.so
broker-conn-str=redis-server:6379
For detailed message broker configuration options, parameters, and settings, refer to the Gst-nvmsgbroker Plugin Documentation.
Application Customization#
The application can be customized to add custom processing logic, modify metadata handling, or integrate additional GStreamer elements.
Source Code Location
The application source code is typically located in /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app/ :
metropolis_perception_app/
├── metropolis_perception_app.c # Main application with pipeline setup
├── metropolis_perception_app.h # Header with structure definitions
├── Makefile # Build configuration
Key Customization Points
Adding Custom Probes
Add probes to access metadata and buffers at specific pipeline elements:
static GstPadProbeReturn custom_pad_probe(GstPad *pad, GstPadProbeInfo *info, gpointer user_data) { GstBuffer *buf = (GstBuffer *) info->data; NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta(buf); // Access and process metadata for (NvDsMetaList *l_frame = batch_meta->frame_meta_list; l_frame != NULL; l_frame = l_frame->next) { NvDsFrameMeta *frame_meta = (NvDsFrameMeta *) (l_frame->data); // Custom processing per frame } return GST_PAD_PROBE_OK; } // Attach probe to a pad GstPad *sink_pad = gst_element_get_static_pad(element, "sink"); gst_pad_add_probe(sink_pad, GST_PAD_PROBE_TYPE_BUFFER, custom_pad_probe, NULL, NULL); gst_object_unref(sink_pad);
Building Custom Application
After modifying the source code, rebuild the application:
cd metropolis_perception_app/
make clean
make
Deployment Considerations
When deploying customized applications using docker compose:
Update the Docker container to include your custom binary:
COPY metropolis_perception_app /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app/ RUN chmod +x /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app/metropolis_perception_app
Ensure all dependencies and libraries are available in the container
Update configuration files to match your custom processing requirements
Common Customization Use Cases
Custom Object Filtering: Filter detected objects based on size, confidence, or region of interest
Custom Analytics: Implement line crossing, zone intrusion, or occupancy counting
External System Integration: Connect to databases, REST APIs, or other services
Performance Monitoring: Add custom telemetry and performance metrics collection
RTSP Streaming#
Variable |
Description |
Default |
|---|---|---|
|
RTSP latency (ms) |
|
|
RTSP timeout (ms) |
|
|
Time to detect stream interruption and wait for reconnection (seconds) |
|
|
Duration to attempt reconnection after interruption (seconds) |
|
|
Max reconnection attempts |
|
Kafka Configuration#
Variable |
Description |
Default |
|---|---|---|
|
Enable Kafka integration |
|
|
Kafka broker address |
|
|
Topic for embedding messages |
|
|
Topic/channel for error messages |
|
Standalone Microservice Deployment and Testing#
The RTVI-CV microservice can be run independently outside the full blueprint deployment. This is useful for validating models, benchmarking inference performance, testing configuration changes, or developing custom integrations without deploying the entire Metropolis stack.
Reference configuration files for every supported model are available in a dedicated GitHub repository. You clone the configs repository, pull the RTVI-CV container, mount the configs and your model assets, adjust batch size and paths, and launch the application.
Prerequisites#
The RTVI-CV Docker image from NGC
For IGX Thor / Jetson platforms, boost VIC clocks before benchmarking — see the Deployment section for instructions
Reference Configuration Repository#
Reference configuration files for standalone testing are maintained in a GitHub repository. Clone the repository on the host machine:
git clone <TODO: GitHub repository URL>
cd <repo-directory>/reference-configs
Note
TODO: Replace the placeholder above with the final GitHub repository URL once available.
The repository contains configs organized by model:
Directory |
Description |
|---|---|
|
Warehouse 2D detection (RT-DETR) — main pipeline config, PGIE config (YAML), class labels, NvDCF tracker config, Kafka/Redis broker configs |
|
Warehouse 3D detection (Sparse4D) — main pipeline config, Sparse4D model config ( |
|
Smart City 2D detection (RT-DETR / TrafficCamNet) — main pipeline config, PGIE config (INI), class labels, Kafka broker config |
|
Smart City open-vocabulary detection (Grounding DINO) — main pipeline config, Triton nvinferserver config, Kafka broker config |
Start the Docker Container#
Pull and launch the RTVI-CV container with GPU access, a persistent storage volume, and the reference configs mounted into the application directory.
Replace <rtvi-cv-image> with the full NGC image path and tag for your platform. Replace device=0 with the target GPU index. Replace <path-to-reference-configs> with the absolute path to the cloned reference-configs directory on the host.
x86 / aarch64 (multi-arch):
docker run --name=rtvi-cv --network=host \
--gpus "device=0" --shm-size=6g \
-v $HOME/standalone-storage:/opt/storage \
-v <path-to-reference-configs>:/opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app/reference-configs \
-it --user root --rm \
<rtvi-cv-image>
SBSA (Spark):
docker run --name=rtvi-cv --network=host \
--gpus "device=0" --privileged --shm-size=6g \
-v $HOME/standalone-storage:/opt/storage \
-v <path-to-reference-configs>:/opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app/reference-configs \
-it --user root --rm \
<rtvi-cv-image>
Thor (Jetson):
Before running benchmarks on Jetson Thor, boost the CPU/GPU and VIC clocks on the host (outside the container):
sudo nvpmodel -m 0
sudo jetson_clocks
sudo su
echo performance > /sys/class/devfreq/8188050000.vic/governor
Then launch the container:
docker run --name=rtvi-cv --network=host \
--gpus "device=0" --shm-size=6g \
-v $HOME/standalone-storage:/opt/storage \
-v <path-to-reference-configs>:/opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app/reference-configs \
-it --user root --rm \
<rtvi-cv-image>
The -v $HOME/standalone-storage:/opt/storage mount persists downloaded models and TensorRT engines across container restarts. The second -v mount makes the reference configs available inside the container at the expected application path.
Configure the NGC CLI inside the container before downloading any models or resources:
mkdir -p /opt/storage/resources
ngc config set --serverurl https://api.ngc.nvidia.com
All remaining steps are run inside the container.
Step 1: Place Your Model and Assets#
Download or copy the required model assets into the container. The table below lists what each model needs:
Model |
Required Assets |
|---|---|
Warehouse 2D (RT-DETR) |
ONNX model file |
Warehouse 3D (Sparse4D) |
ONNX model file, labels file, anchor file ( |
Smart City RT-DETR |
ONNX model file, ReID tracker model (for NvDCF with deep association) |
Smart City GDINO |
ONNX model file |
Use the NGC CLI to download models, or place your own custom ONNX exports in /opt/storage/.
Step 2: Pre-Run Setup (Model-Specific)#
Most models require no additional setup beyond placing the model and updating configs. Sparse4D and Grounding DINO are exceptions — they require extra steps before running.
Note
If you are running Warehouse 2D or Smart City RT-DETR, skip this step and proceed to Step 3: Update Configuration.
Sparse4D (Warehouse 3D)
Sparse4D requires environment variables, config file placement, and a TensorRT engine build before launching:
Set environment variables (required for every terminal session):
export SPARSE4D_REPO=/opt/nvidia/deepstream/deepstream/sources/sparse4d export LD_PRELOAD=$SPARSE4D_REPO/libmsda_fp16.so export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SPARSE4D_REPO:/usr/local/lib/python3/dist-packages/torch/lib
LD_PRELOADloads the MSDA custom TensorRT plugin that Sparse4D depends on at engine build time and inference time.Copy the reference config and calibration files into the Sparse4D source directory:
export CONFIGS=<path-to-reference-configs> cp $CONFIGS/warehouse-3d/config.yaml $SPARSE4D_REPO/configs/config.yaml cp $CONFIGS/warehouse-3d/calibration.json $SPARSE4D_REPO/calibration.json
Generate the TensorRT engine:
bash $SPARSE4D_REPO/configs/sparse4d_setup.sh
Engine generation takes a few minutes depending on the GPU. The engine is cached and reused on subsequent runs.
Important
If you modify config.yaml after the initial copy (for example, changing batch size, enabling visualization, or updating paths), you must re-copy it to $SPARSE4D_REPO/configs/config.yaml before running the application.
Grounding DINO (Smart City)
Grounding DINO uses the Triton Inference Server backend. You must copy the ONNX model into the Triton model repository and build a TensorRT engine before launching:
Copy the ONNX model:
export TRITON_REPO=/opt/nvidia/deepstream/deepstream/sources/TritonGdino/triton_model_repo mkdir -p $TRITON_REPO/gdino_trt/1/ cp <your-gdino-model>.onnx $TRITON_REPO/gdino_trt/1/model.onnx
Build the TensorRT engine (replace
<N>with your batch size):/usr/src/tensorrt/bin/trtexec \ --onnx=$TRITON_REPO/gdino_trt/1/model.onnx \ --minShapes=inputs:1x3x544x960,input_ids:1x256,attention_mask:1x256,position_ids:1x256,token_type_ids:1x256,text_token_mask:1x256x256 \ --optShapes=inputs:<N>x3x544x960,input_ids:<N>x256,attention_mask:<N>x256,position_ids:<N>x256,token_type_ids:<N>x256,text_token_mask:<N>x256x256 \ --maxShapes=inputs:<N>x3x544x960,input_ids:<N>x256,attention_mask:<N>x256,position_ids:<N>x256,token_type_ids:<N>x256,text_token_mask:<N>x256x256 \ --fp16 --useCudaGraph \ --saveEngine=$TRITON_REPO/gdino_trt/1/model.plan
Rebuild the engine when changing batch size. For text prompt configuration, see Text Prompt Configuration.
Step 3: Update Configuration#
All models share a common set of configuration touch points. When changing the number of streams (batch size), the following keys in the main pipeline config must stay in sync:
[streammux]
batch-size=<N>
[primary-gie]
batch-size=<N>
[source-list]
max-batch-size=<N>
Additionally, each model has its own config files where model paths and batch size must be updated:
Model |
Config File |
Keys to Update |
|---|---|---|
Warehouse 2D |
PGIE config (YAML) |
|
Warehouse 3D |
|
|
Preprocess config |
|
|
Smart City RT-DETR |
PGIE config (INI) |
|
Smart City GDINO |
Triton PGIE config |
|
All four Triton |
|
Note
The model-engine-file name typically encodes the batch size (e.g. _b4_gpu0_fp16.engine). When changing batch size, update the engine file name to match, or delete the existing engine file so TensorRT rebuilds it. See the TensorRT Engine notes under Deployment for details.
Step 4: Run the Application#
Launch the application from the metropolis_perception_app directory with the appropriate config file:
cd /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/metropolis_perception_app
./metropolis_perception_app -c <main-config-file>
Model |
Main Config File |
|---|---|
Warehouse 2D |
|
Warehouse 3D |
|
Smart City RT-DETR |
|
Smart City GDINO |
|
By default, the configs use type=1 (FakeSink) so no display is required. On the first run, TensorRT automatically builds optimized engine files from the ONNX models — this may take several minutes. Subsequent runs reuse the cached engines from /opt/storage/.
Stream Management#
All reference configs use dynamic stream addition by default (use-nvmultiurisrcbin=1). The pipeline starts with zero streams and exposes a REST server at http://localhost:9000. After the application is running, add streams via the REST API.
Add a stream dynamically:
curl -XPOST 'http://localhost:9000/api/v1/stream/add' -d '{
"key": "sensor",
"value": {
"camera_id": "<unique-camera-id>",
"camera_name": "<display-name>",
"camera_url": "<file-or-rtsp-url>",
"change": "camera_add",
"metadata": {
"resolution": "1920 x1080",
"codec": "h264",
"framerate": 30
}
},
"headers": {
"source": "vst",
"created_at": "2021-06-01T14:34:13.417Z"
}
}'
The camera_url can be a local file path (file:///opt/storage/videos/sample.mp4) or an RTSP URL (rtsp://<ip>:<port>/<path>). You can add up to max-batch-size streams.
For the complete stream management API, see the API Reference.
Use static sources instead:
To launch with pre-configured sources rather than adding them dynamically, populate the [source-list] section in the main pipeline config:
[source-list]
num-source-bins=<N>
list=file:///path/to/video1.mp4;file:///path/to/video2.mp4
sensor-id-list=cam1;cam2
sensor-name-list=cam1;cam2
max-batch-size=<N>
For RTSP streams, replace file URIs with rtsp:// URLs. Ensure num-source-bins, max-batch-size, and all other batch-size touch points match.
Visualization (Optional)#
The default configs use FakeSink (no display). To visualize detection output on screen, set the DISPLAY environment variable and update the main pipeline config:
export DISPLAY=:0
[sink0]
type=2
[osd]
enable=1
[tiled-display]
enable=1
For Sparse4D (Warehouse 3D) only, also enable 3D bounding box rendering in config.yaml:
generate_3d_bbox: True
After changing config.yaml, re-copy it to the Sparse4D source directory before running.
OpenTelemetry Support#
The microservice supports OpenTelemetry for exporting metrics to observability platforms like Prometheus and Grafana.
Configuration#
Configure OpenTelemetry using the following environment variables:
Environment Variable |
Description |
|---|---|
|
Set to |
|
Service identifier (e.g., |
|
Collector base URL (e.g., |
|
Metric export interval in milliseconds (default: |
|
Export destination: |
Additionally, set below parameters in the deepstream application configuration file:
[tiled-display]
enable=3
[sinkN]
nvdslogger=1
Supported Prometheus Metrics#
The following metrics are exported to Prometheus for monitoring and alerting:
Stream Performance Metrics:
Metric Name |
Description |
Typical Value |
|---|---|---|
|
Frames per second processed for each stream |
25-30 (depends on source) |
|
End-to-end pipeline latency in milliseconds (from frame capture to metadata output) |
30-100ms (lower is better) |
|
Current frame number being processed for each stream (incremental counter) |
Monotonically increasing |
|
Total number of active streams being processed |
Based on configuration |
System Resource Metrics:
Metric Name |
Description |
|---|---|
|
CPU utilization percentage across all cores |
|
GPU compute utilization percentage |
|
System RAM memory usage in gigabytes |
|
GPU memory usage in gigabytes |
Note
gpu_memory_gb is not applicable on aarch64 devices (e.g., Jetson Thor) as they use unified memory, so it returns -1.
OpenTelemetry Collector Configuration#
Ensure an OpenTelemetry Collector is running on the configured otlp-uri endpoint. To filter out inactive stream metrics, add the following processor to your collector configuration:
processors:
filter/drop_inactive_streams:
error_mode: ignore
metrics:
datapoint:
- 'metric.name == "stream_fps" and value_double == -1.0'
- 'metric.name == "stream_latency" and value_double == -1.0'
- 'metric.name == "stream_frame_number" and value_int == -1'
If exporting to Prometheus, set metric_expiration >= otlp-interval to drop stale metrics:
exporters:
prometheus:
endpoint: "0.0.0.0:8889"
metric_expiration: 4s
Runtime Configuration Using REST API#
The OpenTelemetry HTTP exporter can be configured at runtime using the metrics endpoint with custom headers. This allows dynamic configuration without restarting the microservice.
Available Headers:
X-REFRESH-PERIOD: Set the metrics push interval in milliseconds. If the OpenTelemetry exporter is not running, it starts the exporter at the default endpoint (http://localhost:4318) with the specified interval.X-OTLP-URL: Set the OpenTelemetry collector endpoint. Starts posting metrics to the specifiedhttp://ip:portwith default interval (5000 milliseconds).
Examples:
Set refresh interval to 3000 milliseconds (starts exporter at default endpoint if not running):
curl -XGET 'http://localhost:9000/api/v1/metrics' -H "X-REFRESH-PERIOD:3000"
Set custom collector endpoint (uses default 5000 milliseconds interval):
curl -XGET 'http://localhost:9000/api/v1/metrics' -H "X-OTLP-URL:http://192.168.1.100:4318"
Set both custom endpoint and interval:
curl -XGET 'http://localhost:9000/api/v1/metrics' -H "X-REFRESH-PERIOD:3000" -H "X-OTLP-URL:http://192.168.1.100:4318"
Note
If OTEL_SDK_DISABLED="true" is set in the environment variables, using the above runtime configuration will enable OpenTelemetry metrics support. The X-REFRESH-PERIOD value is specified in milliseconds.
Disable the OpenTelemetry HTTP exporter:
curl -XGET 'http://localhost:9000/api/v1/metrics' -H "X-REFRESH-PERIOD:-1"
Troubleshooting#
Common Issues#
Environment settings to be exported in working environment
DEEPSTREAM_ENABLE_SENSOR_ID_EXTRACTION=1Enables sensor_id_extraction, which adds support for the updated schema required by rtvi-cvGST_ENABLE_CUSTOM_PARSER_MODIFICATIONS=1Enables custom_parser changes that patch the SEI handling logic in the OSS parser code to prevent crashes caused by NULL SEI pointer
Issue: Poor performance with large number of streams
For ensuring performance with large number of streams, need to enable sub-batches property in the nvtracker plugin.
Refer nvtracker plugin documentation for more details.
For example:
For 24 streams, set sub-batches to 8:8:8.
Issue: Low FPS / High Latency
Solution:
Reduce batch size for latency-critical applications
Increase batch size for throughput optimization
Check GPU utilization (
nvidia-smi)
Issue: Poor Detection Accuracy
Solution:
Adjust confidence threshold (
pre-cluster-threshold)Verify input image quality and resolution
Check preprocessing configuration (normalization, resize)
Fine-tune model on domain-specific data using TAO
Issue: TensorRT Engine Build Failure
Solution:
Verify ONNX model compatibility with TensorRT version
Check available GPU memory during engine build
Review TensorRT logs for specific errors
Set
force_engine_rebuild: Trueto rebuild engine
Issue: Sparse4D Multi-Camera Sync Issues
Solution:
Verify camera time synchronization (NTP)
Check
batch-sizematchesnum_sensorsEnsure all cameras are streaming at same FPS
Review
nvstreammuxconfiguration
Debugging Tips#
Enable Verbose Logging
export NVDS_LOG_LEVEL=4 # Debug level
Monitor Performance
# Check GPU utilization
nvidia-smi dmon -s u
# Monitor DeepStream FPS
# Check console output for "FPS:" lines
Visualize Outputs
Enable on-screen display (OSD) in DeepStream config:
[osd]
enable=1
border-width=3
text-size=15
Dump Intermediate Tensors
For debugging model issues, enable tensor dumping:
# In config.yaml (Sparse4D)
dump_frames: True
dump_max_frames: 50
For additional troubleshooting guidance, see the DeepStream SDK Troubleshooting Guide.
Error Propagation Configuration#
The microservice supports error propagation using the message API with Redis protocol adaptors to monitor pipeline errors and stream-related issues. Configure error propagation in the application configuration:
[source-list]
#Set the below error propagation key to enable the error propagation to a given adaptor
enable-error-propagation=0
# Once above error propagation key is set, uncomment and update below key values accordingly
# All error messages (stream-related and GStreamer-based) published to user-defined topic
#proto-lib=/opt/nvidia/deepstream/deepstream/lib/libnvds_redis_proto.so
#conn-str=<host>;<port>
#topic=<topic>
Configuration Parameters:
enable-error-propagation: Set to1to enable error propagation (default:0)proto-lib: Path to the protocol adaptor library (libnvds_redis_proto.so)conn-str: Connection string for the message broker (format:<host>;<port>for Kafka,<host>;<port>for Redis)topic: Base topic name for error messages
References#
Official Documentation
Model Papers
External Resources
API Reference