Introduction#
The NVIDIA Blueprint for Video Search and Summarization (VSS) provides a suite of reference architectures for building vision agents and AI-powered video analytics applications. These reference architectures include accelerated vision-based microservices, VLMs, and LLMs which can be used in your existing applications, as standalone microservices, or as part of a larger vision agent built using the blueprint.
Important
Intended deployment environment: Deploy VSS in a trusted, isolated network. Do not expose the VSS services directly to untrusted networks. This release assumes authentication, TLS termination, rate limiting, and external access controls are provided by the infrastructure. For details, see Known Limitations and Secure Deployment.
Architecture Overview#
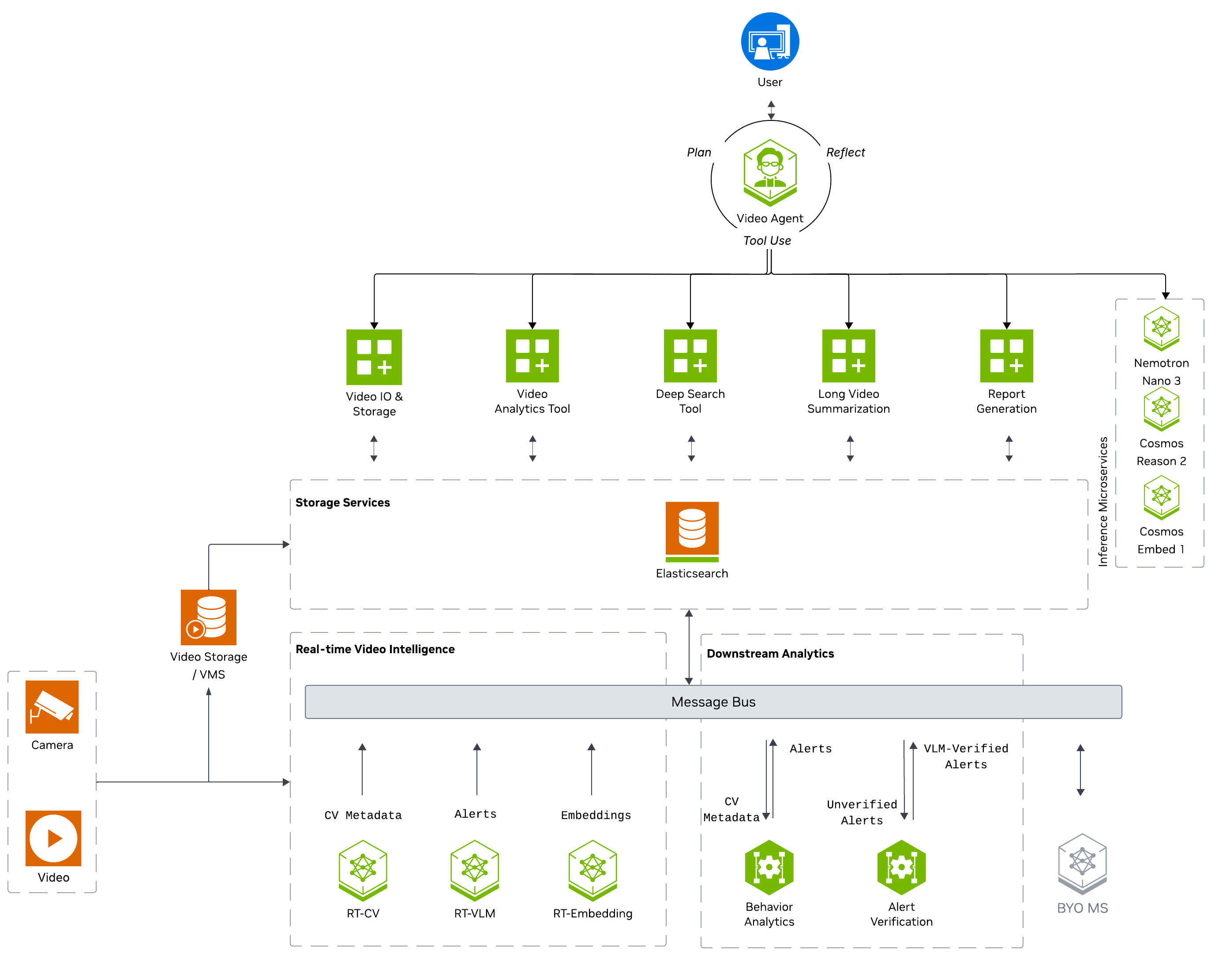
VSS is broken down into 3 major areas of video processing and analysis:
Real-time video intelligence: Extracts features from stored and streamed video in real-time, either continuously or on demand.
Downstream analytics: Analyzes extracted features posted to a message broker or stored in a database for downstream analysis.
Agentic and offline processing: Processes extracted features to generate reports, answers questions, and provides video search capabilities.
Real-Time Video Intelligence#
The Real-Time Video Intelligence layer extracts rich visual features, semantic embeddings, and contextual understanding from video data in real-time, publishing results to a message broker for downstream analytics and agentic workflows. It provides three core microservices for processing video streams:
Real-Time Computer Vision (RT-CV): leverages NVIDIA DeepStream SDK with models like RT-DETR, Grounding DINO, and Sparse4D to perform real-time object detection, classification, and multi-object tracking on single or multi-camera streams.
Real-Time Embedding (RT-Embedding): generates semantic embeddings from video, images, and live RTSP streams using Cosmos-Embed1 models, enabling efficient video search and similarity matching.
Real-Time VLM (RT-VLM): applies Vision Language Models (such as Cosmos Reason1/2 and Qwen3-VL) to generate natural language captions, detect incidents, and identify anomalies in video streams.
Downstream Analytics#
The Downstream Analytics layer processes and enriches the metadata streams generated by real-time video intelligence microservices, transforming raw detections into actionable insights and verified alerts. It provides two core microservices:
Behavior Analytics: consumes frame metadata from message brokers (Kafka, Redis Streams, or MQTT), tracks objects over time across camera sensors, and computes behavioral metrics including speed, direction, and trajectory. It detects spatial events (tripwire crossings, ROI entry/exit) and generates incidents based on configurable violation rules (proximity detection, restricted zones, confined areas).
Alerts Microservice: ingests alerts and incidents from upstream analytics or computer vision pipelines, retrieves corresponding video segments based on alert timestamps, and uses Vision Language Models to verify alert authenticity. Verified results with verdicts (confirmed/rejected/unverified) and reasoning traces are persisted to Elasticsearch and optionally published to Kafka for downstream consumption.
Agent and Offline Processing#
The Agent and Offline Processing layer provides an agent that orchestrates vision-based tools to generate insights, reports, and search capabilities from video content. The top-level agent leverages the Model Context Protocol (MCP) to access video analytics data, incident records, and vision processing capabilities through a unified tool interface. It integrates multiple vision-based tools including video understanding with Vision Language Models (VLMs), semantic video search using embeddings, video summarization for extended footage analysis, and video snapshot/clip retrieval. These tools can also be used as standalone microservices, independent of the agent.
Why VSS?#
VSS is a reference architecture purpose-built for production vision agents. Compared to building a vision agent from scratch, assembling one from generic third-party agent frameworks, or stitching together cloud vision and video understanding APIs, VSS offers three core advantages:
GPU-accelerated real-time video pipeline. VSS uses the NVIDIA DeepStream SDK with TensorRT/Triton-accelerated models and streaming batched inference to process many concurrent camera streams on a single GPU. Throughput scales with available GPU resources rather than per-request API quotas, and capabilities such as synchronized multi-camera 3D detection and tracking with Sparse4D are not exposed by cloud-only vision APIs. See Performance for measured throughput per GPU.
Modular, composable microservices with MCP-based orchestration. Every capability in VSS - real-time computer vision, real-time VLM, embedding generation, behavior analytics, alert verification, summarization - is a standalone microservice with associated Agent Skills and documented REST and MCP interface. Developers deploy only the components they need, swap VLMs and LLMs (Cosmos Reason, Qwen3-VL, local NIMs, or remote model endpoints) without rebuilding services, and integrate the tools into any agent framework via the API Gateway / MCP layer. This avoids both the SDK lock-in of cloud vendor stacks and the bespoke plumbing (message brokers, calibration, multi-stream orchestration, alert verification) required when assembling generic agent frameworks from scratch.
On-premise and edge deployment with no cloud dependency. Because VSS runs on NVIDIA NIMs and locally hosted models, the full pipeline - from video ingest through VLM reasoning - can run inside a trusted, isolated network with no data egress. Reference profiles cover datacenter GPUs, edge devices such as DGX Spark, IGX Thor, and AGX Thor, and Helm-based Kubernetes clusters. For workloads with data sovereignty, latency, or cost-predictability constraints, this avoids the per-request pricing, region restrictions, and closed-source models that come with cloud vision APIs.
Operating VSS with Agent Harnesses#
VSS ships with first-class support for driving the blueprint through natural-language coding agents and agent sandboxes, so developers do not need to memorize compose flags, REST payloads, or MCP tool signatures to deploy and operate the stack.
Agent Skills#
Agent Skills are reusable, self-contained capabilities that follow the agentskills.io specification and package the prompts, reference data, and helper scripts a coding agent needs to operate a deployed VSS Blueprint. Each Skill maps a developer intent - “deploy VSS for video search”, “add a camera”, “summarize this video”, “verify these alerts” - onto the corresponding VSS REST, VA-MCP, and VIOS calls. Skills are versioned alongside the blueprint in the VSS repository, exercised by a CI eval workflow on every change, and consumed by any compatible coding agent (such as Claude Code or Codex) at either deployment time or runtime.
Agent Harnesses#
An agent harness is the coding agent or agent sandbox that loads the VSS Agent Skills and drives the blueprint. Because every Skill follows the agentskills.io specification, any compatible harness can load the same Skills folder without bespoke integration code. Validated harnesses include CLI coding agents such as Claude Code and OpenAI Codex - used to stand up a VSS profile from a request like “Deploy VSS for video search” - and always-on agent sandboxes such as OpenClaw and NemoClaw, which load the same Skills and act as the operational chat interface to a running deployment. See Agent Harnesses for the full list of supported harnesses, their Skills directories, and install flows.
Deployment Types#
To demonstrate the use of the VSS architecture, we provide two deployment types:
Developer Profiles: Deployment type for developers to test and experiment with the VSS architecture. It starts with deploying a basic video agent and then builds on it with additional workflows.
Blueprint Examples: Deployment type for industry-specific use cases, demonstrating typical E2E deployments from video input to agentic workflows.
Developer Profiles#
Developer profiles are docker compose deployments which demonstrate the assembly of various VSS microservices to fulfill specific agent workflows. They are designed to be a starting point for developers to test and experiment with the VSS architecture. To see the developer profiles and their respective workflows, see Agent Workflows.
Industry-Specific Examples#
Industry-specific examples demonstrate the use of the VSS architecture in a variety of industry-specific use cases. These advanced reference deployments include parameters, sample data, and configurations which address key use cases. We provide two blueprint examples:
Smart City Blueprint: A blueprint example which leverages VSS for smart city use cases, including person and vehicle detection/tracking and event verification of collisions.
Warehouse Operations Blueprint: A blueprint example which leverages VSS for warehouse operations use cases, including people and forklift detection/tracking and event verification of near-miss events.