Video Summarization Microservice#
Overview#
Video Summarization is a microservice that uses Vision-Language Models (VLMs) and Large Language Models (LLMs) to extract insights from uploaded videos and live streams. The system provides REST API and Model Context Protocol (MCP) interfaces for video processing and summarization.
The Video Summarization microservice segments long-form media, generates VLM captions or structured events, stores the results, and produces concise summaries that preserve timestamped evidence.
Key Features#
The Video Summarization microservice operates by analyzing media and generating structured, machine-readable output. The primary output includes timestamped events and a high-level summary, allowing users to identify when specific actions, object appearances, or scene changes occurred.
High Customizability and Model Flexibility#
A defining feature of the Video Summarization microservice is its high degree of customization, particularly regarding the underlying language and vision models it employs.
OpenAI Compatibility: The service is designed for maximum interoperability, allowing users to select and integrate any OpenAI compatible Vision-Language Model (VLM) or Large Language Model (LLM). This flexibility ensures that users can leverage the latest and most suitable models for their specific summarization needs and quality requirements.
RTVI-VLM video inferencing: Per-chunk and live-stream video inferencing is delegated to the Real-Time VLM (RTVI-VLM) microservice. RTVI-VLM supports Cosmos Reason 3, Nemotron Nano Omni, and Qwen 3.5 base models through its proxy and openai-compat modes, so operators can pick the best-fit VLM without rebuilding the Video Summarization microservice.
Note
Nemotron Nano Omni model support in RTVI-VLM and the Video Summarization microservice is limited to integration testing and sanity coverage in this release. It has not undergone full production-level validation. Operators should evaluate model quality on their own workloads before deploying to production.
For the full list of supported VLM checkpoints, precision options, and configuration details, see Models Supported in the Real-Time VLM documentation.
Data Persistence and Management#
The integrity and accessibility of the processed data are managed through a configurable database layer.
Configurable Database: Processed summaries, extracted events, captions, and associated metadata are stored in a dedicated database. Elasticsearch is the default database for search and analytics.
Stream Caption Retrieval: Stored captions and events can be retrieved by stream name and time range so agents can answer later questions about configured streams. Stream retrieval and stream summaries based on stored captions are experimental.
Access and Integration Methods#
To ensure broad applicability and seamless integration into diverse workflows, the Video Summarization microservice exposes multiple methods for access and interaction.
REST API: The service provides a standard RESTful Application Programming Interface (API). This allows users to connect to the Video Summarization microservice using programmatic scripts and traditional software integrations, making it ideal for back-end systems and custom applications.
Model Context Protocol (MCP): In addition to the REST API, the Video Summarization microservice exposes an MCP interface for AI agents and orchestration systems.
Architecture#
The Video Summarization microservice supports two deployment profiles: Summarization Base Profile and Summarization with Streaming and Message Bus. The base profile handles file summarization in-process; the streaming profile adds a Kafka message queue and a Logstash consumer service to decouple raw VLM events from the orchestrator and enables RTSP live-stream summarization.
Summarization Base Profile#
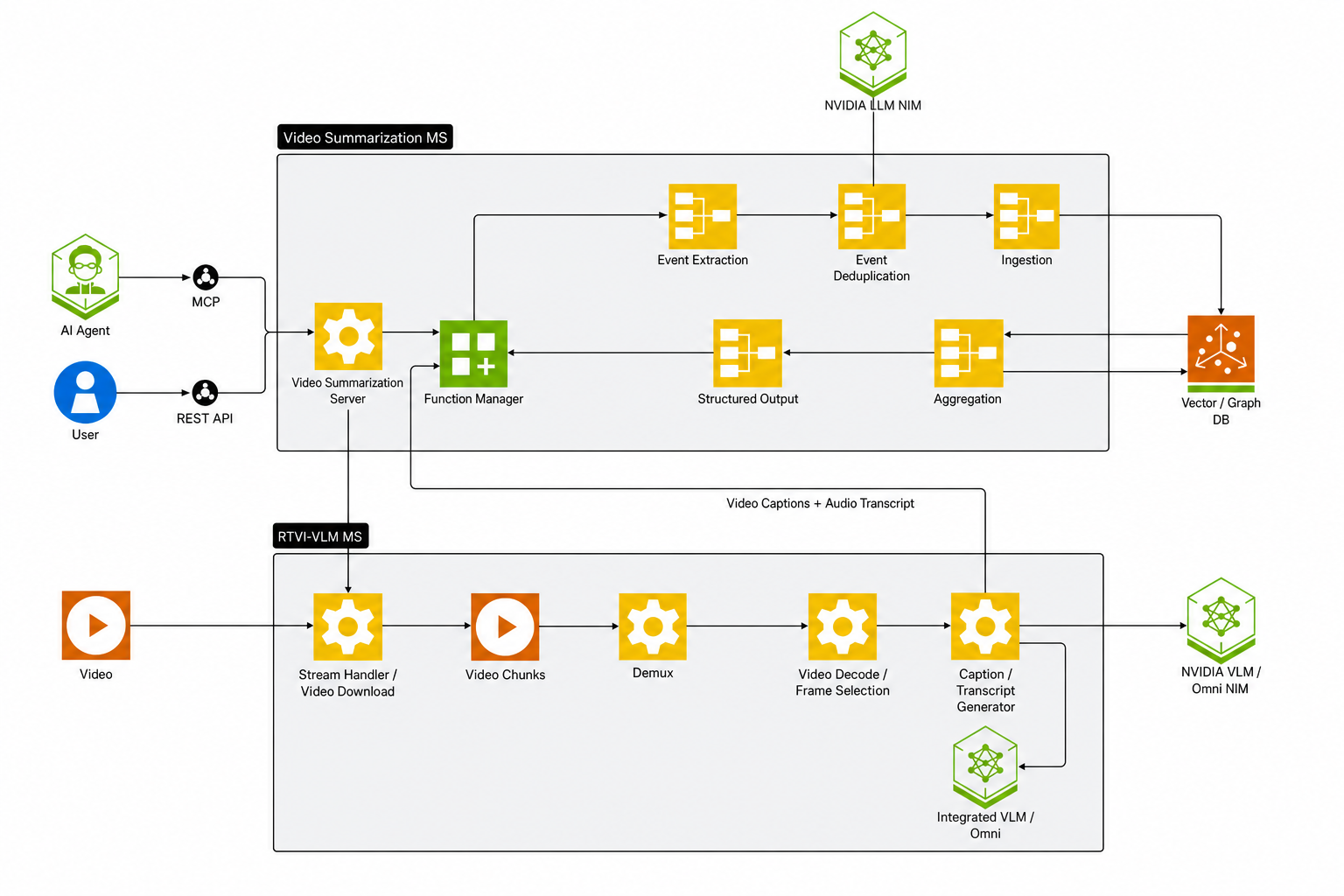
Scenario 1 — File summarization, base profile. The client uploads a video file via REST or MCP. The Video Summarization microservice segments the video into chunks and forwards each chunk to the RTVI-VLM service for inference. RTVI-VLM returns per-chunk events synchronously over Server-Sent Events (SSE); the Video Summarization microservice calls the CA-RAG pipeline in-process to write events to Elasticsearch and aggregate them with the summarization LLM. The structured summary and timestamped events are returned in the HTTP response. The Kafka message queue is disabled in this profile (KAFKA_ENABLED=false).
Summarization with Streaming and Message Bus#
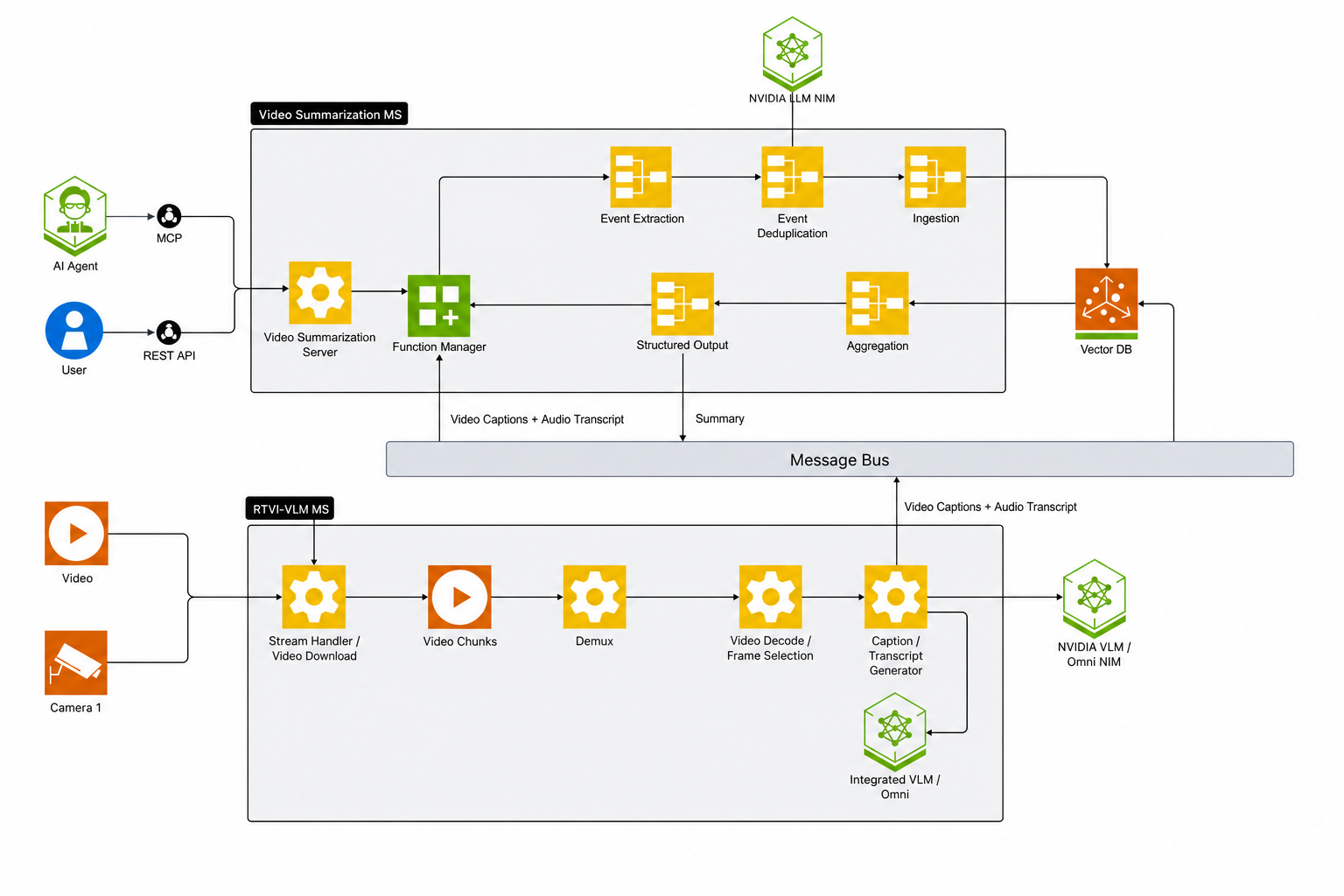
In this profile a Kafka message queue carries raw VLM events and aggregated summaries between RTVI-VLM, the Video Summarization microservice, and Elasticsearch. A Logstash consumer service subscribes to the Kafka topics, decodes the protobuf payloads, normalizes their fields, and indexes the documents into Elasticsearch (default_<asset_id>). RTSP live-stream summarization is supported only in this profile.
Scenario 2 — File summarization with streaming and message bus. The client request is identical to Scenario 1, but RTVI-VLM publishes per-chunk raw events to the Kafka topic mdx-vlm-captions instead of returning them in-process. The Logstash consumer service indexes the events into Elasticsearch. The LVS_CAPTION_SOURCE environment variable controls where the Video Summarization microservice reads captions for aggregation: sse (default) uses the captions received in-process via the RTVI SSE response, while db retrieves captions from the Elasticsearch index populated by the Kafka → Logstash → ES pipeline. In both modes, after the RTVI-VLM SSE stream completes, the Video Summarization microservice waits kafka_consumer_settle_secs (default 5 seconds) so Logstash can flush the last chunk, then aggregates through CA-RAG and publishes the structured events and aggregated summary to the mdx-structured-events-summary topic for Logstash to index.
Scenario 3 — RTSP live-stream summarization with streaming and message bus. Live-stream summarization uses two dedicated APIs instead of the file-only POST /v1/summarize endpoint. The client first calls POST /v1/stream/add on RTVI-VLM with the RTSP URL (no inference yet). In phase 1, the client issues POST /v1/generate_captions on the Video Summarization microservice with the stream ID, model, and prompt parameters (scenario, events, objects_of_interest). The Video Summarization microservice builds the VLM prompt, calls RTVI-VLM to start captioning, and returns immediately with {status: "accepted"}. RTVI-VLM begins captioning frames continuously and publishes raw events to the Kafka message queue, which the Logstash consumer service indexes into Elasticsearch. In phase 2, the client calls POST /v1/stream_summarize with the stream ID and an optional start_time/end_time window. The Video Summarization microservice reads the captions from Elasticsearch, aggregates them via CA-RAG, publishes the structured events and aggregated summary to the mdx-structured-events-summary Kafka topic, and returns the summary synchronously.
Core Components#
The Video Summarization microservice consists of the following core components:
Video Summarization REST Server: FastAPI-based REST API server.
Video Summarization MCP Server: Model Context Protocol server for AI agent integration.
RTVI-VLM: Real-Time VLM service used for per-chunk and live-stream video inferencing.
CA-RAG Pipeline: Context-aware retrieval and generation system that orchestrates event aggregation and summarization.
LLM NIM: NVIDIA Inference Microservice for the summarization LLM.
Vector Store: Elasticsearch for storing extracted events, captions, and aggregated summaries. Stored captions and events can be retrieved by stream name and time range so agents can answer later questions about configured streams.
Kafka Message Queue (Summarization with Streaming and Message Bus profile only): Carries raw VLM events on the
mdx-vlm-captionstopic and aggregated summaries on themdx-structured-events-summarytopic.Logstash Consumer Service (Summarization with Streaming and Message Bus profile only): Subscribes to the Kafka topics, decodes the
nv.VisionLLMprotobuf payloads, normalizes field types, and indexes the documents into Elasticsearch.
Getting Started#
Prerequisites#
Docker and Docker Compose
NVIDIA GPU(s) with appropriate drivers
NGC API Key (for NVIDIA NIMs)
Deployment#
Clone the Repository#
git clone https://github.com/NVIDIA/video-search-and-summarization.git
cd video-search-and-summarization
git checkout tags/v3.2.0
cd services/video-summarization
Build the Container Image#
The Video Summarization compose stack uses a locally built image (via-engine-<username>). Build it before bringing up the stack:
make -C docker build
For the full developer workflow, deploy the Video Summarization profile as described in Video Summarization Workflow.
Video Summarization microservice is deployed via the docker-compose stack at docker/deploy/compose.yaml. Two deployment profiles are supported:
Summarization Base Profile — file summarization without a Kafka message queue.
Summarization with Streaming and Message Bus — file and RTSP live-stream summarization with a Kafka message queue and Logstash consumer service.
Use standalone deployment when you need to run only the Video Summarization server against existing Elasticsearch, LLM, and VLM services. A slimmer single-container option is documented under Standalone Container (Advanced) for operators who already run RTVI-VLM, the LLM NIM, and Elasticsearch externally.
Note
Build the container image as described in the Build the Container Image section above before bringing up the stack. The RTVI-VLM image is pulled from NGC automatically.
Summarization Base Profile#
This profile deploys Video Summarization microservice, RTVI-VLM, and Elasticsearch with the Kafka message queue disabled. Use it for file summarization workloads.
Prerequisites
Docker Engine 28.3.3+ and Docker Compose v2.39.1+
NVIDIA Container Toolkit
NVIDIA GPU(s) with appropriate drivers
External LLM NIM service (for summarization) — configured via
LVS_LLM_HOSTandLVS_LLM_PORT
Environment Setup
Use the example .env file shipped with the compose stack.
Edit .env and set the following key variables:
# API Keys
NGC_API_KEY=<your-ngc-api-key>
NGC_CLI_API_KEY=<your-ngc-api-key>
NVIDIA_API_KEY=<your-nvidia-api-key>
OPENAI_API_KEY=<your-openai-api-key> # required when RTVI uses openai-compat
# Ports
BACKEND_PORT=38111
LVS_MCP_PORT=38112
# Database (in-stack Elasticsearch)
ES_HOST=elasticsearch
ES_PORT=9200
# LLM (external NIM)
LVS_LLM_HOST=<llm-nim-host-ip>
LVS_LLM_PORT=8002
LVS_LLM_MODEL_NAME=openai/gpt-oss-20b
LVS_DATABASE_BACKEND=elasticsearch_db
# RTVI-VLM Integration
COMPOSE_PROFILES=rtvi
RTVI_VLM_IMAGE=nvcr.io/nvidia/vss-core/vss-rt-vlm:3.2.0
RTVI_VLM_PORT=8420
RTVI_VLM_GPU=1
# RTVI_VLM_URL=http://<external-rtvi-host>:8083 # set only when pointing at an external RTVI-VLM
VLM_MODEL_TO_USE=openai-compat
# Kafka message queue disabled for the base profile
KAFKA_ENABLED=false
# Feature Flags
LVS_ENABLE_MCP=true
ENABLE_VIA_HEALTH_EVAL=false
# Logging
VSS_LOG_LEVEL=DEBUG
Bring Up the Stack
docker compose -f docker/deploy/compose.yaml --profile rtvi --env-file .env up -d
Verify Service Health
curl http://localhost:38111/v1/ready
Test the API
Submit a sample file summarization request:
curl --location 'http://localhost:38111/v1/summarize' \
--header 'Content-Type: application/json' \
--data '{
"url": "http://<video-server-ip>:<port>/your-video.mp4",
"model": "gpt-4o",
"scenario": "law enforcement",
"chunk_duration": 15,
"events": ["pulling over", "arrest", "chasing"]
}' | python3 -m json.tool
Replace <video-server-ip> and <port> with your video server address.
Tear Down the Stack
docker compose -f docker/deploy/compose.yaml --profile rtvi down
Summarization with Streaming and Message Bus#
This profile adds a Kafka message queue and a Logstash consumer service to the base profile. It is required for RTSP live-stream summarization, and is also recommended for file summarization when end-to-end Kafka publish-back is desired (for example, to feed downstream consumers off the mdx-structured-events-summary topic).
Prerequisites
Same as the base profile, plus the host ports for the in-stack Kafka broker (
KAFKA_PORTandKAFKA_EXTERNAL_PORT) must be free.
Environment Setup
Source the values from .env for this profile. The diff from the base profile is:
# Enable the Kafka message queue
KAFKA_ENABLED=true
KAFKA_BOOTSTRAP_SERVERS=kafka:9092
KAFKA_TOPIC=mdx-vlm-captions
KAFKA_STRUCTURED_SUMMARY_TOPIC=mdx-structured-events-summary
# Host-side broker ports — the compose defaults are 9092/9094.
# Override these to avoid collisions with other Kafka stacks on the same host.
KAFKA_PORT=9192 # default: 9092
KAFKA_EXTERNAL_PORT=9194 # default: 9094
KAFKA_ADVERTISED_HOST=localhost
# Recommended for multi-call live-stream sessions: keeps the per-stream
# context manager state intact across consecutive /v1/stream_summarize calls.
LVS_DISABLE_DB_RESET_ON_REQUEST_DONE=true
In addition, set the following in configmaps/config.yaml to enable the file path under Kafka mode and to give the Logstash consumer service time to flush the last chunk before the Video Summarization microservice reads events back:
tools:
elasticsearch_db:
type: elasticsearch
params:
host: !ENV ${ES_HOST}
port: !ENV ${ES_PORT}
kafka_consumer_settle_secs: 5.0
functions:
summarization:
type:
vlm_structured_summarization
params:
kafka_enabled: true
summarization_online:
type:
vlm_structured_summarization_online
params:
kafka_enabled: true
Bring Up the Stack
docker compose -f docker/deploy/compose.yaml --profile rtvi --profile kafka up -d
Live-Stream Operator Workflow
Register an RTSP stream on RTVI-VLM (no inference yet):
ASSET_ID=$(curl -fsS -X POST http://localhost:8420/v1/stream/add \
-H 'Content-Type: application/json' \
-d '{
"key": "sensor",
"value": {
"camera_id": "",
"camera_url": "rtsp://<rtsp-source>/stream",
"change": "camera_add"
}
}' \
| python3 -c "import sys,json; print(json.load(sys.stdin).get('asset_id'))")
Start VLM captioning on the stream (fire-and-forget). This is where prompt-related parameters such as
scenario,events, andobjects_of_interestare passed:
curl -fsS -X POST http://localhost:38111/v1/generate_captions \
-H 'Content-Type: application/json' \
-d "{
\"id\": \"$ASSET_ID\",
\"model\": \"gpt-4o\",
\"scenario\": \"warehouse safety monitoring\",
\"events\": [\"box dropping\", \"unsafe forklift operations\", \"normal activity\"],
\"chunk_duration\": 10
}"
Summarize the stream over a time window. No prompt-related parameters are needed — the Video Summarization microservice reads the captions already stored by the captioning phase:
curl -fsS -X POST http://localhost:38111/v1/stream_summarize \
-H 'Content-Type: application/json' \
-d "{
\"id\": \"$ASSET_ID\",
\"model\": \"gpt-4o\",
\"start_time\": 0,
\"end_time\": 0
}"
Repeat the
/v1/stream_summarizecall as needed with progressively larger or narrower time windows to get the latest aggregated events and summary.
Tear Down the Stack
docker compose -f docker/deploy/compose.yaml --profile rtvi --profile kafka down -v --remove-orphans
Standalone Container (Advanced)#
This deployment runs the Video Summarization MS server as a single Docker container, assuming external services (RTVI-VLM, Elasticsearch, LLM NIM) are already running. The compose-based profiles above are recommended for most operators; use this only when you already run all dependencies separately.
Prerequisites
Copy the example environment file to
.env:
touch .env
Edit
.envand fill in your configuration values:
# Environment variables for standalone Video Summarization Server docker run
# Copy this file to .env and fill in the values
# Container Configuration
CONTAINER_IMAGE=nvcr.io/nvidia/vss-core/vss-video-summarization:3.2.0
# API Keys and Authentication
NGC_API_KEY=<your-ngc-api-key>
NVIDIA_API_KEY=<your-nvidia-api-key>
# OPENAI_API_KEY=<your-openai-api-key>
# S3 Configuration (required for S3 URLs)
# AWS_ACCESS_KEY_ID=<your-aws-access-key-id>
# AWS_SECRET_ACCESS_KEY=<your-aws-secret-access-key>
# AWS_ENDPOINT_URL_S3=<your-s3-endpoint-url>
# Port Configuration
BACKEND_PORT=38111
LVS_MCP_PORT=38112
# CA RAG Configuration
# This will be set via mount path - do not override here
# CA_RAG_CONFIG=/opt/nvidia/via/config/default_config.yaml
# Feature Flags
ENABLE_VIA_HEALTH_EVAL=false
LVS_ENABLE_MCP=true
# Database Configuration - Elasticsearch
# Update these to point to your external Elasticsearch service
ES_HOST=<elasticsearch-host-ip>
ES_PORT=9202
ES_TRANSPORT_PORT=9302
# GPU Configuration
# GPU_DEVICES: Comma-separated list of GPU device IDs to use (e.g., "2,3" or "0,1")
GPU_DEVICES=0
NVIDIA_VISIBLE_DEVICES=0
NUM_GPUS=1
# RTVI-VLM Integration (point at an externally running RTVI-VLM)
RTVI_VLM_URL=http://<rtvi-vlm-host>:8000
VLM_MODEL_TO_USE=openai-compat
# OpenTelemetry Configuration (optional)
# VIA_ENABLE_OTEL=false
# VIA_OTEL_ENDPOINT=http://localhost:4318
# VIA_OTEL_EXPORTER=console
# VIA_CTX_RAG_ENABLE_OTEL=false
# VIA_CTX_RAG_EXPORTER=console
# VIA_CTX_RAG_OTEL_ENDPOINT=http://localhost:4318
# Logging and Debug
VSS_LOG_LEVEL=DEBUG
# LLM Configuration
# Update these to point to your external LLM NIM services
LVS_LLM_MODEL_NAME=openai/gpt-oss-20b
LVS_LLM_BASE_URL=http://<llm-nim-host-ip>:8002/v1
# Database Selection
LVS_DATABASE_BACKEND=elasticsearch_db
# Kafka message queue (disabled in standalone mode)
KAFKA_ENABLED=false
Run Script
Create a file named run-lvs-server.sh with the following content:
#!/bin/bash
# Standalone Docker run command for Video Summarization Server
# This script runs only the Video Summarization server container, assuming other services are running separately
# Configuration
CONTAINER_NAME="lvs-server"
ENV_FILE="${ENV_FILE:-.env}"
# Check if .env file exists
if [ ! -f "$ENV_FILE" ]; then
echo "Error: Environment file '$ENV_FILE' not found!"
echo "Please copy .env to $ENV_FILE and fill in the values."
exit 1
fi
# Load CONTAINER_IMAGE from env file
IMAGE=$(grep "^CONTAINER_IMAGE=" "$ENV_FILE" | cut -d'=' -f2)
if [ -z "$IMAGE" ]; then
echo "Error: CONTAINER_IMAGE not found in $ENV_FILE"
echo "Set CONTAINER_IMAGE (e.g., via-engine-\$USER after running make -C docker build)."
exit 1
fi
# Load GPU_DEVICES from env file, default to "2,3" if not set
GPU_DEVICES=$(grep "^GPU_DEVICES=" "$ENV_FILE" | cut -d'=' -f2)
if [ -z "$GPU_DEVICES" ]; then
GPU_DEVICES="2,3"
echo "Warning: GPU_DEVICES not found in $ENV_FILE, using default: $GPU_DEVICES"
fi
# Load MODEL_ROOT_DIR from env file (optional)
MODEL_ROOT_DIR=$(grep "^MODEL_ROOT_DIR=" "$ENV_FILE" | cut -d'=' -f2)
# Load port values from env file
BACKEND_PORT=$(grep "^BACKEND_PORT=" "$ENV_FILE" | cut -d'=' -f2)
LVS_MCP_PORT=$(grep "^LVS_MCP_PORT=" "$ENV_FILE" | cut -d'=' -f2)
# Set defaults if not found
BACKEND_PORT=${BACKEND_PORT:-38111}
LVS_MCP_PORT=${LVS_MCP_PORT:-38112}
# Build port mapping arguments
PORT_ARGS="-p ${BACKEND_PORT}:${BACKEND_PORT} -p ${LVS_MCP_PORT}:${LVS_MCP_PORT}"
# Build volume mount for MODEL_ROOT_DIR if set
MODEL_VOLUME_ARG=""
if [ -n "$MODEL_ROOT_DIR" ]; then
# Expand tilde and get absolute path if directory exists or can be created
MODEL_ROOT_DIR_EXPANDED="${MODEL_ROOT_DIR/#\~/$HOME}"
if [ -d "$MODEL_ROOT_DIR_EXPANDED" ] || mkdir -p "$MODEL_ROOT_DIR_EXPANDED" 2>/dev/null; then
MODEL_ROOT_DIR_ABS="$(cd "$MODEL_ROOT_DIR_EXPANDED" && pwd)"
MODEL_VOLUME_ARG="-v ${MODEL_ROOT_DIR_ABS}:${MODEL_ROOT_DIR_ABS}"
echo "MODEL_ROOT_DIR will be mounted: $MODEL_ROOT_DIR_ABS"
else
echo "Warning: MODEL_ROOT_DIR '$MODEL_ROOT_DIR' could not be accessed or created, skipping mount"
fi
else
echo "MODEL_ROOT_DIR not set in $ENV_FILE, skipping model cache mount"
fi
# Docker run command
# Using host network so the container can resolve service names
# (elasticsearch, rtvi-vlm, LLM NIM) running on the same host.
# To use bridge network with explicit port mapping instead, remove
# --network host and add $PORT_ARGS.
docker run -d \
--name "$CONTAINER_NAME" \
--network host \
--gpus "device=${GPU_DEVICES}" \
--env-file "$ENV_FILE" \
$MODEL_VOLUME_ARG \
--restart unless-stopped \
"$IMAGE"
echo "Video Summarization Server container started!"
echo "Container name: $CONTAINER_NAME"
echo "Container image: $IMAGE"
echo "GPU devices: $GPU_DEVICES"
echo "Backend port: $BACKEND_PORT"
echo "MCP port: $LVS_MCP_PORT"
if [ -n "$MODEL_ROOT_DIR_ABS" ]; then
echo "Model cache mounted from: $MODEL_ROOT_DIR_ABS"
fi
echo ""
echo "To view logs: docker logs -f $CONTAINER_NAME"
echo "To stop: docker stop $CONTAINER_NAME"
echo "To remove: docker rm $CONTAINER_NAME"
Running the Container
Make the script executable:
chmod +x run-lvs-server.sh
Run the script:
./run-lvs-server.sh
Check the container status:
docker logs -f lvs-server
Verify service health:
curl http://localhost:38111/v1/ready
Testing the API
Test video summarization with a sample request:
curl --location 'http://localhost:38111/v1/summarize' \
--header 'Content-Type: application/json' \
--data '{
"id": null,
"url": "http://<video-server-ip>:<port>/your-video.mp4",
"model": "gpt-4o",
"scenario": "law enforcement",
"events": ["pulling over", "arrest", "chasing"]
}' | python3 -m json.tool
Note: Replace <video-server-ip> and <port> with your actual video server address and port.
Stopping the Container
# Stop the container
docker stop lvs-server
# Remove the container
docker rm lvs-server
Configuration Updates
To update environment variables:
Stop and remove the container:
docker stop lvs-server && docker rm lvs-server
Edit your
.envfile with the new valuesRestart the container:
./run-lvs-server.sh
Network Configuration
By default, the script uses Docker’s host network so the container can resolve service names and reach external services (RTVI-VLM, Elasticsearch, LLM NIM) running on the same host. If you need port isolation, edit the script to use bridge network mode (see comments in the script) and reference services by host.docker.internal or the host’s IP address in your .env file.
Troubleshooting
Container fails to start: Check
docker logs lvs-serverfor error messagesCannot connect to external services: Verify
RTVI_VLM_URL,ES_HOST/ES_PORT, andLVS_LLM_BASE_URLin your.envfile and confirm network connectivityPort conflicts: Change port numbers in
.envfileGPU not detected: Ensure NVIDIA Container Toolkit is properly installed
Configuration#
Video Summarization uses YAML configuration files to customize behavior. The main configuration file is mounted in the Video Summarization container and referenced by CA_RAG_CONFIG.
Configuration Structure#
The configuration file (config_update.yml) defines:
1. Tools - External service connections:
tools:
elasticsearch_db:
type: elasticsearch
params:
host: !ENV ${ES_HOST}
port: !ENV ${ES_PORT}
tools:
embedding: nvidia_embedding
summarization_llm:
type: llm
params:
model: !ENV ${LVS_LLM_MODEL_NAME}
base_url: !ENV ${LVS_LLM_BASE_URL}
max_tokens: 10240
temperature: 0.2
top_p: 0.7
api_key: !ENV ${NVIDIA_API_KEY}
nvidia_embedding:
type: embedding
params:
enable: !ENV ${LVS_EMB_ENABLE:false}
model: !ENV ${LVS_EMB_MODEL_NAME}
base_url: !ENV ${LVS_EMB_BASE_URL}
api_key: !ENV ${NVIDIA_API_KEY}
2. Functions - Processing pipelines:
functions:
summarization:
type: vlm_structured_summarization_online
params:
time_overlap_threshold: 0.1
max_events_per_batch: 50
kafka_enabled: true
tools:
db: !ENV ${LVS_DATABASE_BACKEND:elasticsearch_db}
llm: summarization_llm
summarization_online:
type: vlm_structured_summarization_online
params:
time_overlap_threshold: 0.1
max_events_per_batch: 50
kafka_enabled: true
tools:
db: !ENV ${LVS_DATABASE_BACKEND:elasticsearch_db}
llm: summarization_llm
3. Context Manager - Active functions:
context_manager:
functions:
- summarization
- summarization_online
Key Configuration Options#
Vector Database
type:elasticsearch(default)params.host,params.port: Connection parameterstools.embedding: Embedding model to use (reference to tool)
Summarization LLM
type:llm(default)params.model: LLM model name (e.g., from${LVS_LLM_MODEL_NAME})params.base_url: API endpoint (e.g., from${LVS_LLM_BASE_URL})params.max_tokens: Maximum output tokens (default: 10240)params.temperature: Sampling temperature (default: 0.2)params.top_p: Top-p sampling (default: 0.7)params.api_key: Authentication key
Nvidia Embedding
type:embedding(default)params.enable: Enable/disable embedding serviceparams.model: Embedding model nameparams.base_url: Embedding service endpointparams.api_key: NVIDIA API key
VLM Structured Summarization
Used by the file summarization path (POST /v1/summarize). Configured as the summarization function in the context manager.
type: Function type (vlm_structured_summarization(default))params.time_overlap_threshold: Threshold for overlapping time events (default: 0.1)params.max_events_per_batch: Maximum events per batch (default: 50)params.kafka_enabled: Whentrue, the file path reads raw events from Elasticsearch (populated by the Kafka → Logstash pipeline) instead of using the in-process accumulation flow. Must be paired withKAFKA_ENABLED=trueon the Video Summarization MS server. Default:false(reads from${KAFKA_ENABLED})tools.db: Reference to database backend (from${LVS_DATABASE_BACKEND:elasticsearch_db})tools.llm: Reference to LLM tool
VLM Structured Summarization Online
Used by the live-stream summarization path (POST /v1/stream_summarize). Configured as the summarization_online function in the context manager and must be registered alongside summarization for live-stream workflows to dispatch correctly.
type: Function type (vlm_structured_summarization_online)params.time_overlap_threshold: Threshold for overlapping time events (default: 0.1)params.max_events_per_batch: Maximum events per batch (default: 50)params.kafka_enabled: Whentrue, the aggregator reads raw events back from Elasticsearch (populated by the Logstash consumer) rather than expecting in-process accumulation. Required for the live-stream path. Must be paired withKAFKA_ENABLED=trueon the Video Summarization MS server. Default:false(reads from${KAFKA_ENABLED})tools.db: Reference to database backend (from${LVS_DATABASE_BACKEND:elasticsearch_db})tools.llm: Reference to LLM tool
Example: Event Detection#
The default configuration is optimized for event detection in videos:
functions:
summarization:
type: vlm_structured_summarization
params:
time_overlap_threshold: 0.1
max_events_per_batch: 50
kafka_enabled: !ENV ${KAFKA_ENABLED:false}
tools:
db: !ENV ${LVS_DATABASE_BACKEND:elasticsearch_db}
llm: summarization_llm
summarization_online:
type: vlm_structured_summarization_online
params:
time_overlap_threshold: 0.1
max_events_per_batch: 50
kafka_enabled: !ENV ${KAFKA_ENABLED:false}
tools:
db: !ENV ${LVS_DATABASE_BACKEND:elasticsearch_db}
llm: summarization_llm
This extracts structured events with timestamps. You can customize this for specific use cases:
Environment Variables#
Configuration supports environment variable substitution using !ENV ${VAR_NAME}:
Database Configuration
ES_HOST,ES_PORT: Elasticsearch connectionLVS_DATABASE_BACKEND: Database backend to use (elasticsearch_db(default))LVS_DISABLE_DB_RESET_ON_REQUEST_DONE: Preserve stored events and captions after a request completes
LLM Configuration
LVS_LLM_MODEL_NAME: LLM model nameLVS_LLM_BASE_URL: LLM API endpoint
RTVI and Stream Configuration
RTVI_VLM_URL: RTVI-VLM service URL used by the Video Summarization microservice for caption generationRTVI_VLM_URL_PASSTHROUGH: Route VLM calls through RTVI-VLM when set totrueKAFKA_ENABLED: Enable Kafka integration for stream captions and summariesKAFKA_BOOTSTRAP_SERVERS: Kafka bootstrap server listKAFKA_STRUCTURED_SUMMARY_TOPIC: Topic for structured stream summaries
API Keys
NVIDIA_API_KEY: API key for NVIDIA services
Kafka Integration#
When deployed under the Summarization with Streaming and Message Bus profile, the Video Summarization microservice publishes aggregated summarization results to a Kafka message queue and reads per-chunk raw VLM events that RTVI-VLM publishes to the same broker. A Logstash consumer service decodes the protobuf payloads from Kafka and indexes them into Elasticsearch (default_<asset_id>). This enables decoupling of the summarization pipeline from downstream consumers, analytics dashboards, and real-time alerting systems.
Kafka Topics#
The streaming and message bus profile uses two Kafka topics:
Raw VLM Events (default:
mdx-vlm-captions): Containsnv.VisionLLMprotobuf messages produced by RTVI-VLM. Each message carries one chunk’s caption result with frame metadata, sensor info, and theinfo["doc_type"]="raw_events"marker. After the Logstash consumer service decodes and indexes these messages into Elasticsearch, thedoc_typevalue is stored atmetadata.content_metadata.doc_typein the ES document.Structured Summary (default:
mdx-structured-events-summary): Containsnv.VisionLLMprotobuf messages produced by the Video Summarization microservice. Each call toPOST /v1/summarize(file path) orPOST /v1/stream_summarize(live-stream path) publishes oneinfo["doc_type"]="structured_events"message per batch (up tomax_events_per_batchevents) plus oneinfo["doc_type"]="aggregated_summary"message carrying the narrative summary. In Elasticsearch, the Logstash-mapped field path ismetadata.content_metadata.doc_type.
Configuration:
Kafka integration is controlled by the following environment variables on the Video Summarization MS server:
KAFKA_ENABLED: Enable or disable Kafka integration (
true/false). Default:falseKAFKA_BOOTSTRAP_SERVERS: Comma-separated list of Kafka broker addresses (e.g.,
localhost:9092orkafka:9092for the in-stack broker)KAFKA_TOPIC: Topic for raw VLM events. Default:
mdx-vlm-captionsKAFKA_STRUCTURED_SUMMARY_TOPIC: Topic for structured events and aggregated summaries. Default:
mdx-structured-events-summaryKAFKA_PORT: Host port mapping for the in-stack Kafka broker’s internal listener. Default:
9092KAFKA_EXTERNAL_PORT: Host port mapping for the broker’s external listener; also embedded in
KAFKA_ADVERTISED_LISTENERS. Default:9094KAFKA_ADVERTISED_HOST: Hostname or IP that host-side or cross-host clients use to reconnect. Default:
localhost
The same KAFKA_ENABLED=true and KAFKA_BOOTSTRAP_SERVERS values must also be set on the RTVI-VLM service so it publishes raw events to the same broker. See RTVI-VLM Kafka Integration for the producer-side configuration.
Note
KAFKA_TOPIC and KAFKA_STRUCTURED_SUMMARY_TOPIC are forwarded to the Logstash consumer service as well, so all three components (Video Summarization MS, RTVI-VLM, and Logstash) use the same configurable topic names. Override both variables in .env when the default topic names conflict with an existing Kafka deployment.
ctx-rag function configuration:
In addition to the environment variables above, set the following in configmaps/config.yaml to fully enable Kafka mode end to end:
tools:
elasticsearch_db:
type: elasticsearch
params:
host: !ENV ${ES_HOST}
port: !ENV ${ES_PORT}
kafka_consumer_settle_secs: 5.0 # seconds the Video Summarization MS waits after the
# RTVI SSE [DONE] event to let
# Logstash flush the last chunk
functions:
summarization:
params:
kafka_enabled: true # file path uses Kafka end-to-end
summarization_online:
params:
kafka_enabled: true # required for live-stream path
How Summaries Are Sent to Kafka#
Under the streaming and message bus profile, the publishing flow depends on the API path:
File path (
POST /v1/summarize): RTVI-VLM publishes per-chunk raw events toKAFKA_TOPICas it processes the file. TheLVS_CAPTION_SOURCEenvironment variable controls where the Video Summarization microservice reads captions for aggregation:sse(default) uses captions received in-process via the RTVI SSE response, whiledbretrieves them from the Elasticsearch index populated by the Kafka → Logstash → ES pipeline. Indbmode, the Video Summarization microservice waitskafka_consumer_settle_secs(default 5 seconds) so the Logstash consumer service can flush the last chunk. In both modes, the Video Summarization microservice aggregates captions via CA-RAG and publishes the structured events and aggregated summary toKAFKA_STRUCTURED_SUMMARY_TOPIC.Live-stream path (
POST /v1/generate_captions+POST /v1/stream_summarize): The client first calls/v1/generate_captionsto start VLM captioning (fire-and-forget). RTVI-VLM publishes raw events to the Kafka topic, and Logstash indexes them into Elasticsearch. The client then calls/v1/stream_summarizewith an optional[start_time, end_time]window. The Video Summarization microservice reads captions from Elasticsearch, aggregates them via CA-RAG, and publishes the structured events and summary toKAFKA_STRUCTURED_SUMMARY_TOPICwith a per-call upsert ID so repeated calls overwrite the latest result for that stream.Message keys: All messages are published with the key
{request_id}:{chunk_idx|batch_i|doc_i}(UTF-8 encoded) for partitioning and ordering.Requirement: Set
KAFKA_ENABLED=trueon both the Video Summarization MS and RTVI-VLM, and configureKAFKA_BOOTSTRAP_SERVERSon both services. Without these,/v1/summarizesilently falls back to the legacy in-process aggregation flow.POST /v1/summarizenow rejectssource_type=streamwith HTTP 422, directing clients to use the dedicated live-stream APIs instead.
Video Summarization MS to RTVI Sticky Routing (x-stream-id)#
The Video Summarization microservice attaches an x-stream-id HTTP header on every outbound request to RTVI-VLM. The header value is the asset or stream ID for the request (for example, the UUID returned by POST /v1/stream/add). Load balancers or service meshes sitting in front of RTVI-VLM can use this header to route all requests that belong to the same stream to the same RTVI-VLM instance, preventing split-brain state in multi-instance deployments.
The header is sent on the following Video Summarization MS to RTVI call paths:
start_captions—POST /v1/generate_captions(live-stream captioning trigger)generate_captions_stream—POST /v1/generate_captionswithstream=True(file-path captioning)
Message Formats#
Both topics carry nv.VisionLLM protobuf messages. The info map (map<string, string>) is used to distinguish doc types and carry per-stream metadata for the Logstash consumer service.
Raw VLM Events#
Raw events are produced by RTVI-VLM, one per video chunk. See RTVI-VLM VisionLLM Messages for the complete VisionLLM protobuf schema. Video Summarization MS-relevant info fields injected by RTVI-VLM include:
doc_type:
"raw_events"collection_name: Target Elasticsearch index (
default_<asset_id>)uuid / streamId: Asset identifier for the source video or live stream
chunkIdx: Zero-indexed chunk number within the request
start_pts / end_pts: Chunk start and end timestamps in milliseconds
start_ntp / end_ntp: Chunk start and end NTP timestamps (ISO 8601)
is_first / is_last: Boolean markers for chunk boundary in the SSE stream
Structured Events and Aggregated Summary#
Structured-summary messages are produced by the Video Summarization microservice after CA-RAG aggregation. The same nv.VisionLLM protobuf carries two distinct doc_type values:
doc_type=structured_events: One message per batch of up to
max_events_per_batchaggregated events. Thellm.queries[0].responsefield carries a JSON-encoded array of event objects (id,start_time,end_time,type,description).doc_type=aggregated_summary: A single message per summarization call (
/v1/summarizefor files,/v1/stream_summarizefor live streams) carrying the narrativevideo_summarytext inllm.queries[0].response.
Video Summarization MS-injected info fields on every published message:
doc_type:
"structured_events"or"aggregated_summary"collection_name:
default_<sanitized stream_id>— drives the Elasticsearch_indexLogstash writes touuid: Source asset or stream identifier
camera_id: When set on the live stream, copied from the operator’s
/v1/stream/addpayloadbatch_i: Zero-indexed batch number for
structured_eventsmessagesevent_count / total_events: Per-batch and per-call event counts
ID for upsert: Logstash builds the Elasticsearch document _id deterministically as <collection>:<uuid>:<doc_type>:<chunkIdx|batch_i|doc_i>. Repeated /v1/summarize calls on the same stream therefore overwrite the same two ES documents (one structured_events per batch, one aggregated_summary) — this is intentional for at-least-once Kafka redelivery safety.
MCP Server Integration#
Video Summarization includes a Model Context Protocol (MCP) server that exposes the same functionality as the REST API in a format consumable by AI agents and tools like Claude Desktop, Cursor, and other MCP-compatible clients.
Overview#
The MCP server (lvs_mcp.py) provides:
Stdio Transport: Default mode for direct integration with MCP clients
SSE Transport: HTTP-based Server-Sent Events transport for network access
Tool-based Interface: All REST endpoints exposed as MCP tools
Configuration#
The MCP server can be enabled/disabled and configured via environment variables:
LVS_ENABLE_MCP: Enable/disable MCP server (default:true)LVS_MCP_PORT: Port for SSE transport (if not set, uses stdio)
Example: Enable SSE transport on port 38112:
export LVS_ENABLE_MCP=true
export LVS_MCP_PORT=38112
Available MCP Tools#
The MCP server exposes the following tools:
Health & Status
health_ready: Check server readinesshealth_live: Check server livenessget_metrics: Get Prometheus metrics
File Management
add_file: Upload media filelist_files: List uploaded filesget_file_info: Get file metadatadelete_file: Delete a file
Video Processing
list_models: List available VLM modelssummarize_video: Generate video file summarygenerate_captions: Start VLM captioning on a live stream (fire-and-forget)stream_summarize: Summarize a live stream over a time windowgenerate_vlm_captions: Generate timestamped VLM captionsget_recommended_config: Get recommended configuration
Using with MCP Clients#
Claude Desktop Configuration
Add to your Claude Desktop configuration:
{
"mcpServers": {
"via-engine": {
"command": "docker",
"args": [
"exec",
"-i",
"lvs-server",
"python",
"/opt/nvidia/via/src/lvs_mcp.py"
]
}
}
}
Direct SSE Connection
When running with LVS_MCP_PORT set, connect to:
SSE Endpoint:
http://<host>:38112/sseMessages Endpoint:
http://<host>:38112/messages
Example Tool Call:
{
"name": "summarize_video",
"arguments": {
"id": "<file_id>",
"model": "nvidia/Cosmos-Reason2-8B",
"scenario": "police body camera",
"events": ["pulling over", "arrest", "chasing"]
}
}
Best Practices#
Performance Optimization#
Chunk Duration: Use 30-60 second chunks for optimal GPU utilization
RTVI-VLM Tuning: Configure batch size, frame counts, and per-process GPU allocation on the RTVI-VLM service. See Real-Time VLM for guidance.
Live-Stream Sessions: Set
LVS_DISABLE_DB_RESET_ON_REQUEST_DONE=trueto keep context-manager state intact across consecutive/v1/stream_summarizecalls on the same stream.Logstash Settle Window: Tune
tools.elasticsearch_db.params.kafka_consumer_settle_secs(default 5 seconds) to balance ingest latency against the file-path summarize wall time when using the streaming profile.
Error Handling#
Enable
stream: truefor long videos to receive progressive updatesSet appropriate
max_tokensto avoid truncationUse
chunk_overlap_durationto avoid missing events at boundaries
Troubleshooting#
Common Issues#
API Returns 503 Service Unavailable
Another video is being processed (the Video Summarization microservice processes one video or live-stream request at a time)
Wait for current processing to complete
Out of Memory Errors
Tune RTVI-VLM batch size and frame inputs (see Real-Time VLM)
Decrease
chunk_durationSwitch to a smaller VLM model on RTVI-VLM
Slow Processing
Add GPUs to the RTVI-VLM service
Use a smaller or faster VLM model on RTVI-VLM
Reduce
num_frames_per_chunkon RTVI-VLMWhen using the streaming profile, lower
kafka_consumer_settle_secsif the Kafka and Logstash pipeline is keeping up
VLM Returns Incomplete or Invalid JSON Events (Missing or Empty Fields)
The VLM may sometimes produce events that are missing required fields (like
type,description) or contain fields that are present but empty (e.g.,"type": ""). This will lead to warnings such as:
WARNING Skipping invalid event {'start_time': 75.01, 'end_time': 79.5}: 2 validation errors for Event
type
Field required [type=missing, ...]
description
Field required [type=missing, ...]
WARNING Chunk 1: vlm_pipeline_ctx is None - chunk span will be ***MASKED***
WARNING No events found in document 1
WARNING Skipping invalid event {'id': 2, 'start_time': 29.53, 'end_time': 29.53, 'type': '', 'description': 'There are no visible anomalies or artifacts in the frame.'}: 1 validation error for Event
type
Field cannot be empty [type=value_error, ...]
Cause: The VLM may not always strictly follow the JSON output schema. This can result in missing fields, or required fields present with empty values (such as an empty string for
type), especially in difficult scenes or with certain models. When this happens, those events fail validation and are skipped.Impact: Some chunks may report zero extracted events, and the final summary may be incomplete for those time ranges.
Workarounds:
Simplify the event list to reduce ambiguity for the model
Use
override_vlm_promptwith a more explicit prompt that reinforces the required output fields (start_time,end_time,description,type), and clarifies that fields must not be emptyIncrease the number of frames per chunk on RTVI-VLM to give the model more visual context
Retry the summarization request — VLM outputs can vary between runs
MCP Server Not Connecting
Check
LVS_ENABLE_MCP=trueVerify
LVS_MCP_PORTis accessibleCheck container logs:
docker logs lvs-server
Logs and Debugging#
# Set log level
export VSS_LOG_LEVEL=DEBUG
# View logs
docker-compose logs -f lvs-server
# Check specific component
grep "MCP" /var/log/via/via-server.log
API Error Codes#
400 Bad Request: Invalid input syntax
401 Unauthorized: Missing or invalid authentication token
409 Conflict: File is in use and cannot be deleted
422 Unprocessable Entity: Failed to process request (validation error).
POST /v1/summarizereturns this status when called withsource_type=stream— usePOST /v1/generate_captionsandPOST /v1/stream_summarizefor live-stream workflows instead.429 Rate Limit Exceeded: Too many requests
500 Internal Server Error: Server-side error
503 Service Unavailable: Server is busy processing another file
Appendix#
Environment Variables Reference#
Complete list of available environment variables:
API Configuration
BACKEND_PORT: REST API port (default: 38111)LVS_MCP_PORT: MCP server port (default: 38112)VSS_API_ENABLE_VERSIONING: Enable /v1 prefix
API Keys
NGC_API_KEY: NVIDIA NGC API keyNVIDIA_API_KEY: NVIDIA AI API keyOPENAI_API_KEY: OpenAI API keyAZURE_OPENAI_API_KEY: Azure OpenAI API key
S3 Configuration
AWS_ACCESS_KEY_ID: AWS access key ID (required for S3 URL support)AWS_SECRET_ACCESS_KEY: AWS secret access key (required for S3 URL support)AWS_ENDPOINT_URL_S3: AWS S3 endpoint URL (required for S3 URL support)
VLM Configuration
VLM_MODEL_TO_USE: VLM backend selector — set toopenai-compatwhen delegating inference to RTVI-VLM in proxy mode
RTVI-VLM Configuration
RTVI_VLM_URL: URL of the RTVI-VLM service (e.g.,http://rtvi-vlm:8000for the in-stack container, or an external host)RTVI_VLM_IMAGE: Container image for the in-stack RTVI-VLM serviceRTVI_VLM_PORT: Host port for the in-stack RTVI-VLM service (default: 8420; the container always listens on 8000)RTVI_VLM_GPU: GPU device ID assigned to the RTVI-VLM container (separate from the Video Summarization MS GPU)
Kafka Configuration
KAFKA_ENABLED:trueenables the streaming profile end to end on the Video Summarization MS server;falsefor the base profile (default:false)KAFKA_BOOTSTRAP_SERVERS: Kafka broker bootstrap address used by the Video Summarization MS and RTVI-VLM (default:kafka:9092inside the docker network)KAFKA_TOPIC: Kafka topic for raw VLM events (default:mdx-vlm-captions)KAFKA_STRUCTURED_SUMMARY_TOPIC: Kafka topic for structured events and aggregated summaries (default:mdx-structured-events-summary)KAFKA_PORT: Host port mapping for the in-stack Kafka broker’s internal listener (default:9092)KAFKA_EXTERNAL_PORT: Host port mapping for the broker’s external listener; also embedded inKAFKA_ADVERTISED_LISTENERS(default:9094)KAFKA_ADVERTISED_HOST: Hostname or IP that host-side or cross-host clients use to reconnect (default:localhost)LVS_CAPTION_SOURCE: Controls where file-path Kafka aggregation reads captions:sse(default) uses captions received in-process via the RTVI SSE response,dbretrieves captions from Elasticsearch populated by the Kafka → Logstash → ES pipelineLVS_DISABLE_DB_RESET_ON_REQUEST_DONE:truekeeps the per-stream context-manager state across consecutive/v1/stream_summarizecalls — recommended for live-stream sessions
Database Configuration
ES_HOST,ES_PORT: Elasticsearch connectionES_TRANSPORT_PORT: Elasticsearch transport port (default: 9302)ES_MAX_SHARDS_PER_NODE: Maximum number of shards allowed per Elasticsearch node (default:2000). EachPOST /v1/summarizeorPOST /v1/stream/addcreates onedefault_<asset_id>index with one shard; raise this cap for long-retention or high-volume deployments.ES_JAVA_OPTS: JVM heap flags for the in-stack Elasticsearch container (default:-Xms4g -Xmx4g). Elasticsearch recommends no more than 20 active shards per GB of heap — the 4 GB default supports roughly 80 active shards in steady state. TuneES_MAX_SHARDS_PER_NODEandES_JAVA_OPTStogether when increasing retention.LVS_DATABASE_BACKEND: Database backend to use (default:elasticsearch_db)LVS_DISABLE_DB_RESET_ON_REQUEST_DONE: Preserve request data in the database after processing
LLM Configuration
LVS_LLM_HOST,LVS_LLM_PORT: LLM NIM host and portLVS_LLM_MODEL_NAME: LLM model name (e.g.,openai/gpt-oss-20b)LVS_LLM_BASE_URL: LLM API base URL
Stream Configuration
RTVI_VLM_URL: RTVI-VLM service URL for caption generationRTVI_VLM_URL_PASSTHROUGH: Route Video Summarization VLM calls through RTVI-VLMKAFKA_ENABLED: Enable Kafka integrationKAFKA_BOOTSTRAP_SERVERS: Kafka bootstrap server listKAFKA_STRUCTURED_SUMMARY_TOPIC: Topic for structured stream summaries
Feature Flags
LVS_ENABLE_MCP: Enable MCP server (default: true)ENABLE_VIA_HEALTH_EVAL: Enable health evaluation (default: false)VSS_DISABLE_DECODER_REUSE: Disable decoder reuse (default: true)
Logging and Monitoring
VSS_LOG_LEVEL: Log level (DEBUG,INFO,WARNING,ERROR)VIA_LOG_DIR: Directory for VIA logsVIA_ENABLE_OTEL: Enable OpenTelemetryVIA_OTEL_ENDPOINT: OpenTelemetry endpoint (e.g.,http://localhost:4318)VIA_OTEL_EXPORTER: OpenTelemetry exporter type (e.g.,console)VIA_CTX_RAG_ENABLE_OTEL: Enable OpenTelemetry for context RAGVIA_CTX_RAG_EXPORTER: Context RAG exporter typeVIA_CTX_RAG_OTEL_ENDPOINT: Context RAG OpenTelemetry endpoint (e.g.,http://localhost:4318)
Performance#
Published E2E latency and sizing guidance are in Video Summarization Performance.
Glossary#
CA-RAG: Caption-Augmented Retrieval-Augmented Generation
VLM: Vision-Language Model
NIM: NVIDIA Inference Microservice
RTVI-VLM: Real-Time Vision-Language Model microservice — see Real-Time VLM
RTSP: Real-Time Streaming Protocol, the network protocol used for live camera streams
MCP: Model Context Protocol
RAG: Retrieval-Augmented Generation
CV: Computer Vision
PPE: Personal Protective Equipment
API Reference