Real-Time VLM Microservice#
Overview#
The Real-Time VLM Server is a FastAPI-based REST API service that provides real-time video understanding capabilities using Vision Language Models (VLM). It enables users to generate captions, process live video streams, and manage live streams through a comprehensive set of REST endpoints.
The server translates between HTTP requests/responses and the underlying Real-Time VLM Microservice components, providing a clean API interface for live stream processing operations.
Key Features#
VLM Caption Generation: Generate captions and alerts using Vision Language Models for live streams
Live Stream Support: Process RTSP live streams for real-time caption generation and alert detection
Streaming Responses: Server-Sent Events (SSE) for streaming output or Kafka messages
Asset Management: Comprehensive stream lifecycle management
Sampling Rate Management: Manage the image frames sampling for VLM inference of the live stream
Health Monitoring: Health check endpoints for service monitoring
Metrics: Prometheus metrics endpoint for observability
Architecture#
The following diagram illustrates the DeepStream Accelerated Pipeline architecture for the RTVI VLM Server:
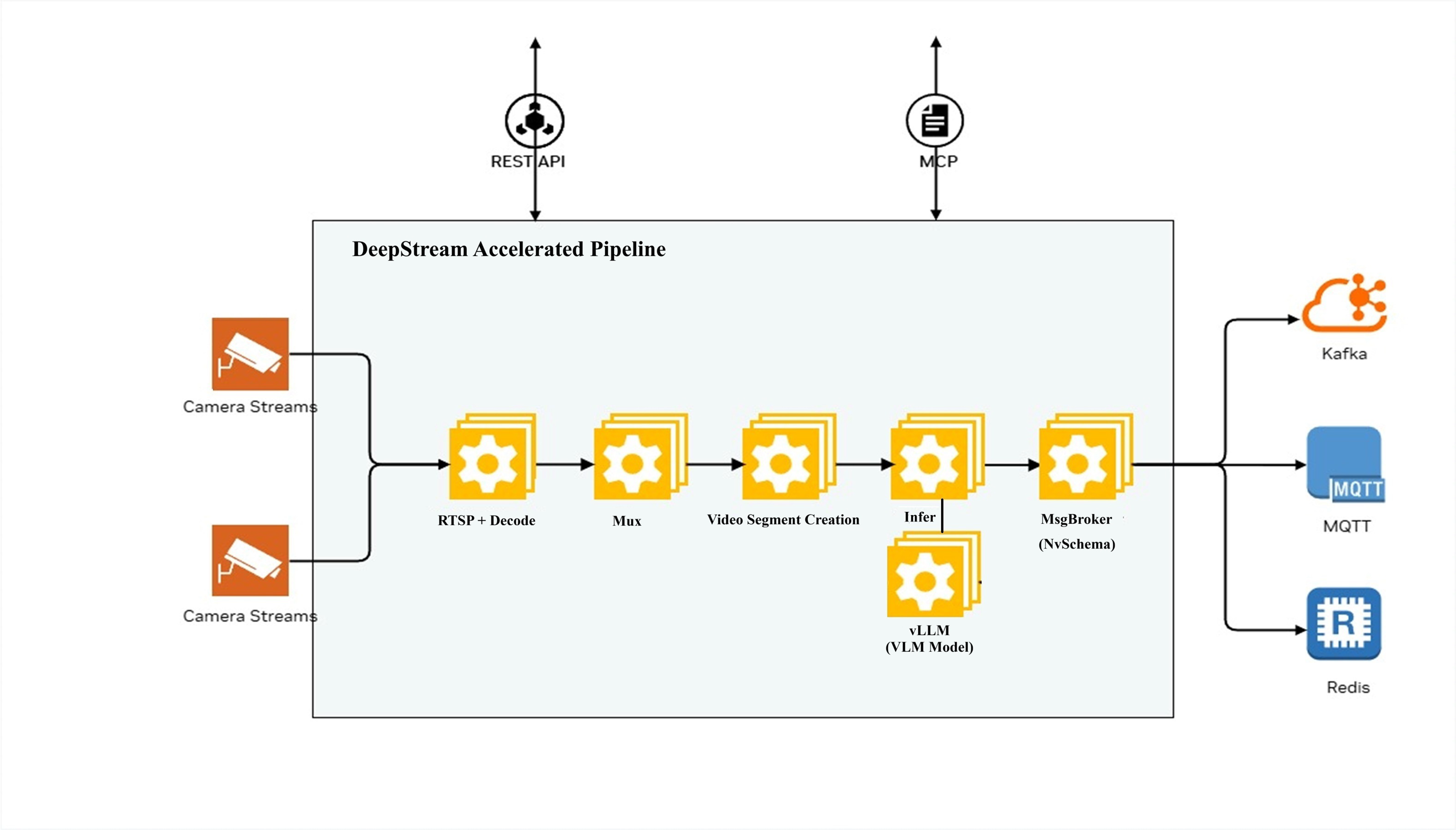
The pipeline processes camera streams through the following stages:
RTSP + Decode: Receives and decodes camera streams
Video Segment Creation: Creates video segments for processing
Infer: Performs inference using VLM models (with vLLM inference engine)
MsgBroker (NvSchema): Publishes messages to Kafka
The system can be configured and controlled via:
REST API: HTTP-based API for configuration and control
Models Supported#
The RTVI VLM Microservice supports local vLLM-compatible checkpoints, NGC
model artifacts, and remote OpenAI-compatible endpoints. Use
MODEL_PATH=git:<Hugging Face URL> for Hugging Face checkpoints,
MODEL_PATH=ngc:<org>/<team>/<model>:<version> for NGC model artifacts,
or VLM_MODEL_TO_USE=openai-compat with VIA_VLM_ENDPOINT for a remote
endpoint.
The following model families are supported.
Cosmos Reason2 Family (Default)#
Cosmos Reason2 8B with
0303-fp8-dynamic-kv8. UseVLM_MODEL_TO_USE=cosmos-reason2andMODEL_PATH=ngc:nim/nvidia/cosmos-reason2-8b:0303-fp8-dynamic-kv8.Cosmos Reason2 8B hf-0303. Use
VLM_MODEL_TO_USE=cosmos-reason2andMODEL_PATH=ngc:nim/nvidia/cosmos-reason2-8b:hf-0303.Cosmos Reason2 8B 0303-fp4-dynamic-kv8. Use
VLM_MODEL_TO_USE=cosmos-reason2andMODEL_PATH=ngc:nim/nvidia/cosmos-reason2-8b:0303-fp4-dynamic-kv8. Do not use this FP4/NVFP4 variant on GB200.
Cosmos3 Family#
Cosmos3 Nano Reasoner modelopt-nvfp4-full-quantize. Use
VLM_MODEL_TO_USE=cosmos-reason3andMODEL_PATH=ngc:nim/nvidia/cosmos3-nano-reasoner:modelopt-nvfp4-full-quantize-final_format_fix.Cosmos3 Nano Reasoner modelopt-fp8-full-quantize. Use
VLM_MODEL_TO_USE=cosmos-reason3andMODEL_PATH=ngc:nim/nvidia/cosmos3-nano-reasoner:modelopt-fp8-final_format_fix.
Nemotron Omni Family#
Nemotron-3-Nano-Omni-30B-A3B-Reasoning. Use
VLM_MODEL_TO_USE=vllm-compatibleandVLM_TRUST_REMOTE_CODE=true. SetVLM_MODEL_SUPPORTS_AUDIO=truefor native audio.Nemotron-3-Nano-Omni-30B-A3B-Reasoning-FP8. Use
VLM_MODEL_TO_USE=vllm-compatibleandVLM_TRUST_REMOTE_CODE=true. SetVLM_MODEL_SUPPORTS_AUDIO=truefor native audio.
Qwen Family#
Qwen3-VL-30B-A3B-Instruct. Use
VLM_MODEL_TO_USE=vllm-compatibleandMODEL_PATH=git:https://huggingface.co/Qwen/Qwen3-VL-30B-A3B-Instruct.Qwen3-Omni-30B-A3B-Instruct. Use
VLM_MODEL_TO_USE=vllm-compatibleandMODEL_PATH=git:https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct.Qwen3.5-27B. Use
VLM_MODEL_TO_USE=vllm-compatibleandMODEL_PATH=git:https://huggingface.co/Qwen/Qwen3.5-27B.
Cosmos Reason1#
Cosmos Reason1 7B 1.1-fp8-dynamic. Use
VLM_MODEL_TO_USE=cosmos-reason1andMODEL_PATH=ngc:nim/nvidia/cosmos-reason1-7b:1.1-fp8-dynamic.
RT-VLM supports video and text prompts for caption generation. Remote VLM
model endpoints are tested with NVIDIA NIM or OpenAI-compatible
chat/completions endpoints.
API Reference#
For complete API documentation including all endpoints, request/response schemas, and interactive examples, see the Real-Time VLM API Reference.
The API is organized into the following categories:
Captions: Generate VLM captions and alerts for videos and live streams
Files: Upload and manage video/image files
Live Stream: Add, list, and manage RTSP live streams
Stream: CV-compatible stream add, remove, and list APIs
Models: List available VLM models
Health Check: Service health and readiness probes
Metrics: Prometheus metrics endpoint
Metadata: Service metadata and version information
NIM Compatible: OpenAI-compatible endpoints for interoperability
Endpoint |
Method |
Description |
|---|---|---|
|
|
Get Prometheus-format RTVI metrics |
|
|
Get RTVI VLM Microservice readiness status |
|
|
Get RTVI VLM Microservice liveness status |
|
|
Get RTVI VLM Microservice startup status |
|
|
Get asset storage statistics |
|
|
Get RTVI VLM Microservice metadata |
|
|
Upload a media file or register media by URL/path |
|
|
List uploaded files |
|
|
Delete a file |
|
|
Get file information |
|
|
Get file content |
|
|
Add one or more live streams |
|
|
List live streams |
|
|
Remove a live stream |
|
|
Remove multiple live streams |
|
|
Add a stream using the CV-compatible format |
|
|
Remove a stream using the CV-compatible format |
|
|
List streams using the CV-compatible format |
|
|
List available models |
|
|
Generate VLM captions and audio transcripts |
|
|
Stop live stream caption generation |
|
|
OpenAI-compatible chat completion endpoint |
|
|
OpenAI-compatible completions endpoint |
|
|
Get release and API versions |
|
|
Get license information |
|
|
Get service manifest information |
|
|
NIM-compatible liveness check |
|
|
NIM-compatible readiness check |
All endpoints are prefixed with /v1. The API is available at
http://<host>:8000.
Deployment#
Prerequisites#
Validated GPUs:
The RTVI VLM Microservice has been validated and tested on the following NVIDIA GPUs:
NVIDIA H100
NVIDIA RTX PRO 6000 Blackwell
NVIDIA L40S
NVIDIA DGX SPARK
NVIDIA IGX Thor
NVIDIA AGX Thor
Software:
OS: Ubuntu 24.04 or compatible Linux distribution (x86); DGX OS 7.4.0 (DGX Spark); Jetson Linux BSP Rel 38.4/38.5 (Jetson Thor)
Docker: Version 28.2+ and earlier than 29.5.0
Docker Compose: Version 2.36+
NVIDIA Driver: 580+
NVIDIA Container Toolkit: Latest version
Git LFS: For large file handling
Quick Start#
Clone the blueprint repository and use the deployment assets shipped with the RT-VLM service.
Docker Compose Deployment#
Clone the repository and change into the service Docker directory:
git clone https://github.com/NVIDIA-AI-Blueprints/video-search-and-summarization.git cd video-search-and-summarization git checkout tags/v3.2.0 cd services/rtvi/rt-vlm/docker
Create a
.envfile with your configuration:cat > .env << EOF BACKEND_PORT=8000 RTVI_IMAGE=nvcr.io/nvidia/vss-core/vss-rt-vlm:3.2.0 # For DGX Spark/SBSA platforms: #RTVI_IMAGE=nvcr.io/nvidia/vss-core/vss-rt-vlm:3.2.0-sbsa VLM_MODEL_TO_USE=cosmos-reason2 MODEL_PATH=ngc:nim/nvidia/cosmos-reason2-8b:0303-fp8-dynamic-kv8 KAFKA_ENABLED=true #KAFKA_BOOTSTRAP_SERVERS=<Kafka_server_ip:port> KAFKA_TOPIC=mdx-vlm-captions KAFKA_INCIDENT_TOPIC=mdx-vlm-incidents NGC_API_KEY=nvapi-XXXXXX VLM_BATCH_SIZE=128 NVIDIA_VISIBLE_DEVICES=0 EOF
Start the service:
docker compose up
Note
The standalone Compose stack starts RT-VLM, Kafka, and Redis. To use a
different Kafka server, set KAFKA_BOOTSTRAP_SERVERS. To use a different
Redis server, set REDIS_HOST.
If the launch fails due to Out of Memory error, see Troubleshooting (adjust VLLM_GPU_MEMORY_UTILIZATION,
reduce VLM_MAX_MODEL_LEN, or set NVIDIA_VISIBLE_DEVICES=<gpuid>).
The APIs are available at http://<HOST_IP>:<BACKEND_PORT>/docs.
Standalone Helm Chart Deployment#
Use the standalone Helm chart when running only RT-VLM on Kubernetes. The chart
is in deploy/helm/services/rtvi/charts/rtvi-vlm in the
video-search-and-summarization repository.
Clone the repository and change into the chart directory:
git clone https://github.com/NVIDIA-AI-Blueprints/video-search-and-summarization.git cd video-search-and-summarization git checkout tags/v3.2.0 cd deploy/helm/services/rtvi/charts/rtvi-vlm
Create the namespace and secrets:
kubectl create namespace vss-rtvi kubectl create secret docker-registry ngc-image-pull-secret \ --docker-server=nvcr.io \ --docker-username='$oauthtoken' \ --docker-password="$NGC_API_KEY" \ -n vss-rtvi kubectl create secret generic ngc-api \ --from-literal=NGC_API_KEY="$NGC_API_KEY" \ -n vss-rtvi # Required when MODEL_PATH points to a gated Hugging Face checkpoint. kubectl create secret generic hf-token-secret \ --from-literal=HF_TOKEN="$HF_TOKEN" \ -n vss-rtvi
Install the chart with the standalone override:
helm upgrade --install vss-rtvi-vlm . \ -n vss-rtvi \ -f overrides_rtvi_vlm.yaml
When using the
hf-token-secretsecret, sethfTokenSecret.name=hf-token-secretandhfTokenSecret.key=HF_TOKENin your values file or with--set.Expose the API for local testing:
kubectl port-forward -n vss-rtvi svc/vss-rtvi-vlm 8000:8000
The API is available at http://localhost:8000/docs.
Source Code Updates and Custom Container Build#
Use this workflow only when you have changed RT-VLM source files under
services/rtvi/rt-vlm/src and need those changes inside the runtime
container. Custom container testing is supported with the standalone Docker
Compose deployment.
Build the custom image from the RT-VLM service directory:
cd video-search-and-summarization/services/rtvi/rt-vlm docker build -f docker/Dockerfile -t <registry>/<repo>/vss-rt-vlm:3.2.0-custom .
Test the image with Docker Compose by setting
RTVI_IMAGEindocker/.env:RTVI_IMAGE=<registry>/<repo>/vss-rt-vlm:3.2.0-custom
Then restart the service:
cd docker docker compose down docker compose up
For DGX Spark/SBSA Docker Compose testing, build an ARM64/SBSA image from the
rt-vlm/ directory and load it into the local Docker image store. Export
IS_SBSA=true on the host shell before the build command so the Dockerfile
resolves the -sbsa base image automatically:
export IS_SBSA=true
docker buildx build --platform linux/arm64 \
--build-arg IS_SBSA \
-f docker/Dockerfile \
-t <registry>/<repo>/vss-rt-vlm:3.2.0-custom-sbsa \
--load .
For Jetson AGX Thor / IGX Thor (ARM64 but not SBSA), do not set
IS_SBSA. The default base image
(nvcr.io/nvidia/vss-core/vss-rt-vlm:3.2.0) is multi-arch, so a
linux/arm64 build pulls the Thor-compatible arm64 variant automatically:
docker buildx build --platform linux/arm64 \
-f docker/Dockerfile \
-t <registry>/<repo>/vss-rt-vlm:3.2.0-custom-thor \
--load .
Required Packages for Usage Examples#
The Python examples require the following packages. Install with:
pip install requests sseclient-py
requests – HTTP client for all examples
sseclient-py – Server-Sent Events client (required only for streaming examples)
The RTVI CLI client uses additional packages (tabulate, tqdm, pyyaml) for
enhanced output formatting; the examples below are self-contained and need only
requests and sseclient-py.
Usage Examples#
Note
Discovering the loaded model ID: The examples below use cosmos-reason2 as the
model field. When running a locally deployed model, the service loads it under its
full NGC artifact ID (e.g., nim_nvidia_cosmos-reason2-8b_0303-fp8-dynamic-kv8).
Use GET /v1/models to retrieve the exact ID before making inference requests:
import requests
response = requests.get("http://localhost:8000/v1/models")
model_id = response.json()["data"][0]["id"]
print(f"Loaded model: {model_id}") # use this as the "model" field
Replace cosmos-reason2 in the examples below with the returned id.
Dense Captioning Example#
The following example demonstrates dense captioning for a stored video file.
A video is uploaded, split into temporal chunks based on chunk_duration
and chunk_overlap_duration, and each chunk is processed by the VLM.
Workflow: For a video of duration D seconds with chunk_duration=60
and chunk_overlap_duration=10, the video is chunked into overlapping
segments (e.g., a 120-second video yields approximately 2 chunks). Each chunk
is decoded, frames are sampled, and the VLM generates a caption. With
stream=False (default), all chunks are processed and returned together
in a single JSON response.
import requests
import json
BASE_URL = "http://localhost:8000/v1"
# Step 1: Upload a video file
with open("video.mp4", "rb") as f:
response = requests.post(
f"{BASE_URL}/files",
files={"file": f},
data={
"purpose": "vision",
"media_type": "video",
"creation_time": "2024-06-09T18:32:11.123Z"
}
)
response.raise_for_status()
file_info = response.json()
file_id = file_info["id"]
print(f"Uploaded file: {file_id}")
# Step 2: Generate captions (chunks returned in full response)
caption_request = {
"id": file_id,
"prompt": "Describe what is happening in this video",
"model": "cosmos-reason2",
"chunk_duration": 60,
"chunk_overlap_duration": 10,
"enable_audio": False
}
response = requests.post(
f"{BASE_URL}/generate_captions",
json=caption_request
)
response.raise_for_status()
captions = response.json()
print(f"Generated {len(captions['chunk_responses'])} caption chunks")
# Step 3: Process results
for chunk in captions["chunk_responses"]:
print(f"[{chunk['start_time']} - {chunk['end_time']}]: {chunk['content']}")
# Step 4: Clean up
requests.delete(f"{BASE_URL}/files/{file_id}")
print("File deleted")
Dense Captioning (Streaming) Example#
The following example demonstrates dense captioning for a live RTSP stream with streaming output. As the stream is decoded in real time, it is split into chunks (e.g., 60-second segments with 10-second overlap). Each chunk is processed by the VLM as it becomes available.
Workflow: With stream=True, chunks are returned incrementally via
Server-Sent Events (SSE). Each SSE event contains chunk_responses for
chunks that have completed VLM inference. The client receives captions
as they are generated instead of waiting for the entire stream to finish.
The stream terminates with a [DONE] message.
Concurrent RTSP caption requests: each /v1/generate_captions request
for an RTSP stream ID gets its own request ID, prompt, SSE response stream,
and private server-side live decode pipeline. Multiple clients can caption the
same RTSP stream concurrently, and repeated requests no longer reconnect to an
existing live caption request. Because each request uses a separate decoder,
many concurrent requests for the same stream can reduce performance.
DELETE /v1/generate_captions/{stream_id} or deleting the stream stops all
active caption jobs for that stream ID.
import requests
import json
import sseclient
BASE_URL = "http://localhost:8000/v1"
# Step 1: Add live stream
stream_request = {
"streams": [{
"liveStreamUrl": "rtsp://example.com/stream",
"description": "Main warehouse camera"
}]
}
response = requests.post(
f"{BASE_URL}/streams/add",
json=stream_request
)
response.raise_for_status()
stream_info = response.json()
if stream_info.get("errors"):
raise RuntimeError(f"Failed to add stream: {stream_info['errors']}")
stream_id = stream_info["results"][0]["id"]
print(f"Added stream: {stream_id}")
# Step 2: Start caption generation with streaming
caption_request = {
"id": stream_id,
"prompt": "Describe what is happening in this live stream",
"model": "cosmos-reason2",
"stream": True,
"chunk_duration": 60,
"chunk_overlap_duration": 10
}
response = requests.post(
f"{BASE_URL}/generate_captions",
json=caption_request,
stream=True
)
response.raise_for_status()
# Step 3: Process streaming responses (chunks as they complete)
client = sseclient.SSEClient(response)
for event in client.events():
data = event.data.strip() if event.data else ""
if data == "[DONE]":
break
if not data:
continue
result = json.loads(data)
if "chunk_responses" in result:
for chunk in result["chunk_responses"]:
print(f"[{chunk['start_time']}]: {chunk['content']}")
# Step 4: Stop processing and remove stream
requests.delete(f"{BASE_URL}/generate_captions/{stream_id}")
requests.delete(f"{BASE_URL}/streams/delete/{stream_id}")
print("Stream removed")
Listing Live Streams#
Use GET /v1/streams/get-stream-info to list all currently registered live streams.
This is useful for verifying that a stream was added successfully or for retrieving
the stream ID of an existing stream.
import requests
BASE_URL = "http://localhost:8000/v1"
response = requests.get(f"{BASE_URL}/streams/get-stream-info")
response.raise_for_status()
streams = response.json() # list of LiveStreamInfo objects
for stream in streams:
print(f"ID: {stream['id']}, URL: {stream['liveStreamUrl']}")
CV-Compatible Stream API#
In addition to the /v1/streams/* endpoints, the RTVI VLM service exposes
a CV-schema-compatible stream API for cross-service interoperability with
RTVI-CV pipelines: POST /v1/stream/add, POST /v1/stream/remove, and
GET /v1/stream/get-stream-info. The request and response payloads follow
the CV schema (camera_id, url, metadata).
If metadata.prompt is supplied on POST /v1/stream/add, the service
auto-starts caption inference for the stream at add time; otherwise the
stream is registered without inference and can be driven later.
import requests
BASE_URL = "http://localhost:8000/v1"
# Register a stream with auto-inference enabled
payload = {
"camera_id": "camera-entrance-east-01",
"url": "rtsp://example.com/stream",
"metadata": {
"prompt": "Describe what is happening in this live stream"
}
}
response = requests.post(f"{BASE_URL}/stream/add", json=payload)
response.raise_for_status()
# Remove the stream
requests.post(
f"{BASE_URL}/stream/remove",
json={"camera_id": "camera-entrance-east-01"}
)
VLM Alert Example#
The following example demonstrates alert/anomaly detection using the VLM. Use a prompt that expects a structured Yes/No response for anomaly detection. When anomalies are detected, incidents can be published to the Kafka incident topic (see Kafka Integration). The Incident message payload is defined in Incident Messages.
import requests
BASE_URL = "http://localhost:8000/v1"
# Upload video or use existing stream ID
file_id = "your-file-id" # or stream_id for live streams
caption_request = {
"id": file_id,
"prompt": (
"You are a warehouse monitoring system focused on safety and "
"efficiency. Analyze the situation to detect any anomalies such as "
"workers not wearing safety gear, leaving items unattended, or "
"wasting time. Respond in the following structured format:\n"
"Anomaly Detected: Yes/No\n"
"Reason: [Brief explanation]"
),
"system_prompt": "Answer the user's question correctly in yes or no",
"model": "cosmos-reason2",
"chunk_duration": 60,
"chunk_overlap_duration": 10
}
response = requests.post(
f"{BASE_URL}/generate_captions",
json=caption_request
)
captions = response.json()
for chunk in captions["chunk_responses"]:
content = chunk.get("content", "")
if "Anomaly Detected: Yes" in content:
print(f"ALERT [{chunk['start_time']} - {chunk['end_time']}]: {content}")
Chat Completions API Example#
The OpenAI-compatible /v1/chat/completions endpoint supports three input
modes for video/image: pre-uploaded file ID, HTTP/HTTPS URL, and base64 data URL.
1. Using pre-uploaded file ID (id field):
import requests
BASE_URL = "http://localhost:8000/v1"
file_id = "your-uploaded-file-uuid" # From POST /v1/files
response = requests.post(
f"{BASE_URL}/chat/completions",
json={
"model": "cosmos-reason2",
"id": file_id,
"messages": [{"role": "user", "content": "Describe what is happening in this video."}],
},
)
result = response.json()
print(result["choices"][0]["message"]["content"])
2. Using HTTP URL (image_url or video_url in message content):
import requests
BASE_URL = "http://localhost:8000/v1"
response = requests.post(
f"{BASE_URL}/chat/completions",
json={
"model": "cosmos-reason2",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": "What is in this image?"},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.png"},
},
],
}
],
},
)
result = response.json()
print(result["choices"][0]["message"]["content"])
# For video, use "video_url" instead:
# {"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
3. Using base64 data URL (inline media in message content):
import requests
import base64
BASE_URL = "http://localhost:8000/v1"
# Read and encode image as base64
with open("image.png", "rb") as f:
b64_data = base64.b64encode(f.read()).decode("utf-8")
data_url = f"data:image/png;base64,{b64_data}"
response = requests.post(
f"{BASE_URL}/chat/completions",
json={
"model": "cosmos-reason2",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": "Describe this image."},
{"type": "image_url", "image_url": {"url": data_url}},
],
}
],
},
)
result = response.json()
print(result["choices"][0]["message"]["content"])
# For video: data:video/mp4;base64,<base64_string>
URL-Based Processing#
POST /v1/generate_captions and POST /v1/files accept a url
field for direct server-side ingestion without a prior upload step.
Supported schemes: http://, https://, s3://, and file://.
New request fields on /v1/generate_captions:
url— media URL (any supported scheme).media_type—"video"(default) or"image".creation_time— ISO 8601 timestamp used as the frame-time offset baseline (useful for live-correlated archive playback).url_headers— per-request authorization headers (dict). HTTPS only; cross-domain redirects strip these headers.
New response field: each chunk in chunk_responses includes a
zero-based chunk_id for ordering.
Security:
file://URLs are rejected unlessFILE_URL_ALLOWED_DIRSis set (comma-separated absolute directories). Paths are resolved viarealpathto prevent traversal escapes.HTTP/HTTPS URLs are validated against SSRF rules. Per-domain SSL skip is opt-in via
ASSET_DOWNLOAD_SSL_SKIP_VERIFY_DOMAINS. Redirect hops are disabled by default; raise the cap viaASSET_DOWNLOAD_MAX_REDIRECTS(max 10). Server-level auth tokens can be set per domain viaASSET_DOWNLOAD_AUTH_TOKENS(format:domain1=Bearer token1;domain2=Basic xyz).
import requests
BASE_URL = "http://localhost:8000/v1"
caption_request = {
"url": "https://example.com/video.mp4",
"media_type": "video",
"creation_time": "2024-06-09T18:32:11.123Z",
"prompt": "Describe what is happening in this video",
"model": "cosmos-reason2",
"chunk_duration": 60,
"chunk_overlap_duration": 10
}
response = requests.post(
f"{BASE_URL}/generate_captions",
json=caption_request
)
response.raise_for_status()
for chunk in response.json()["chunk_responses"]:
print(f"[chunk {chunk['chunk_id']}] {chunk['content']}")
Implementation Details#
Server Class#
The RT VLM Server implements the FastAPI application and manages all API endpoints.
Timestamp Handling#
The server handles timestamps differently based on media type, for live stream uses NTP timestamps (ISO 8601 format).
Streaming Implementation#
For streaming responses, the server uses Server-Sent Events (SSE):
Events are sent as JSON objects
Each event contains chunk responses as they become available
Final event contains usage statistics (if requested)
Stream terminates with
[DONE]messageMultiple clients can caption the same RTSP stream concurrently. Each
/v1/generate_captionscall gets its own request ID, prompt, SSE response stream, and private server-side live decode pipeline. Multiple decoders for the same stream can reduce performance.
Kafka Integration#
The RTVI VLM Server can publish messages to Kafka topics for downstream processing. This enables integration with other microservices, analytics pipelines, and real-time alerting systems.
Kafka Topics#
The server publishes to the following Kafka topics:
VisionLLM Messages: Contains VisionLLM protobuf messages with VLM caption results.
Incidents: Contains Incident protobuf messages when anomalies or incidents are detected.
Configuration:
Kafka integration is controlled by the following environment variables:
KAFKA_ENABLED: Enable/disable Kafka integration (
true/false). Default:trueKAFKA_BOOTSTRAP_SERVERS: Comma-separated list of Kafka broker addresses (e.g.,
localhost:9092orkafka:9092for Docker)KAFKA_TOPIC: Topic for VisionLLM messages.
KAFKA_INCIDENT_TOPIC: Topic for incident messages.
How Alerts and Incidents Are Sent to Kafka#
When generate_captions processes video chunks, the server publishes
messages to Kafka as each chunk completes VLM inference:
VisionLLM messages are always sent to
KAFKA_TOPIC. Each message contains the VLM caption, frame metadata, sensor info, and anincidentDetectedflag in theinfomap ("true"or"false"). When reasoning is enabled and parsed from the VLM output, the reasoning is also added to theinfomap as bothreasoningandreasoningDescription.Incident messages are sent to
KAFKA_INCIDENT_TOPIConly when an anomaly is detected. The server detects incidents by checking the VLM response for trigger phrases such as"yes"or"true"(case-insensitive). Use prompts that expect structured Yes/No answers (see Enabling Incidents). For the full Incident message payload (protobuf schema and example), see Incident Messages. When reasoning is available, it is also added toIncident.infoas bothreasoningandreasoningDescription.Publishing flow (per chunk):
After VLM inference completes, the server builds a VisionLLM protobuf and optionally an Incident protobuf if the response triggers an alert.
Each message is sent asynchronously with a key
{request_id}:{chunk_idx}for partitioning and ordering.A
message_typeheader ("vision_llm"or"incident") identifies the payload type for consumers.VisionLLM and Incident messages are published independently; an incident is sent only when the VLM output indicates an anomaly.
Requirement: Set
KAFKA_ENABLED=trueand configureKAFKA_BOOTSTRAP_SERVERSfor Kafka publishing to occur.
Message Formats#
Incident Messages#
Incident messages are serialized as Protocol Buffer (protobuf) messages
using the Incident message type from the protobuf schema.
Message Header:
message_type:
"incident"
Message Structure:
message Incident {
string sensorId = 1;
google.protobuf.Timestamp timestamp = 2;
google.protobuf.Timestamp end = 3;
repeated string objectIds = 4;
repeated string frameIds = 5;
Place place = 6;
AnalyticsModule analyticsModule = 7;
string category = 8;
repeated Embedding embeddings = 9;
bool isAnomaly = 10;
LLM llm = 12;
map<string, string> info = 11;
}
Key Fields:
sensorId: Identifier of the sensor/stream
timestamp: Start timestamp of the incident
end: End timestamp of the incident
objectIds: Array of object IDs involved in the incident
category: Category of the incident (e.g.,
"safety_non_compliance")isAnomaly: Boolean indicating if the incident is an anomaly
llm: LLM query and response information
info: Additional metadata map containing fields like: *
request_id: Request ID associated with the incident *chunk_idx: Chunk index where the incident was detected *incident_detected: Alert flag *reasoning: Parsed VLM reasoning, when available *reasoningDescription: Parsed VLM reasoning, when available *priority: Priority level (e.g.,"high")
Example Incident JSON (for reference):
{
"sensorId": "camera-entrance-east-01",
"timestamp": "2025-11-19T06:22:20Z",
"end": "2025-11-19T06:22:32Z",
"objectIds": [],
"frameIds": ["frame-10512", "frame-10518"],
"place": {
"id": "dock-entrance-east",
"name": "Dock Entrance - East",
"type": "warehouse-bay"
},
"analyticsModule": {
"id": "inc-activity-detector",
"description": "Forklift safety compliance detector",
"source": "VLM",
"version": "2.0.0"
},
"category": "safety_non_compliance",
"isAnomaly": true,
"info": {
"priority": "high",
"request_id": "req_1234567890",
"chunk_idx": "5"
},
"llm": {
"queries": [{
"response": "Operator entered the high-risk loading area without a high-visibility vest while a forklift was active."
}]
}
}
VisionLLM Messages#
VisionLLM messages contain VLM caption results and are serialized as
Protocol Buffer messages using the VisionLLM message type.
Message Header:
message_type:
"vision_llm"(default, if not specified)
Message Structure:
See the protobuf schema documentation for complete VisionLLM message
structure. Key fields include:
version: Message version
timestamp: Start timestamp
end: End timestamp
startFrameId: Start frame identifier
endFrameId: End frame identifier
sensor: Sensor information
llm: LLM queries, responses, and embeddings
info: Additional metadata map. When reasoning is enabled and parsed from the VLM output, this map includes both
reasoningandreasoningDescription.
Redis Error Messages#
By default, error messages are sent to Kafka. To use Redis for error
messages, set the following environment variables in your .env file:
ENABLE_REDIS_ERROR_MESSAGES=true
REDIS_HOST=redis.example.com
REDIS_PORT=6379
REDIS_DB=0
REDIS_PASSWORD=your_password # Optional, only if Redis requires authentication
ERROR_MESSAGE_TOPIC=vision-llm-errors # Redis channel name for error messages
Error messages will be published to the Redis channel specified in
ERROR_MESSAGE_TOPIC. The message format remains JSON with the following
fields: streamId, timestamp, type, source, event.
Using Remote Endpoints#
The RTVI VLM Microservice supports using remote endpoints with NVIDIA NIM or OpenAI-compatible models:
NVIDIA NIM:
VLM_MODEL_TO_USE=openai-compat
OPENAI_API_KEY=nvapi-XXXXXXX
VIA_VLM_ENDPOINT="https://integrate.api.nvidia.com/v1"
VIA_VLM_OPENAI_MODEL_DEPLOYMENT_NAME="nvidia/nemotron-nano-12b-v2-vl"
For local deployments, update VIA_VLM_ENDPOINT to point to your local
deployment.
GPT-4o:
OPENAI_API_KEY=<openai key>
VLM_MODEL_TO_USE=openai-compat
VIA_VLM_OPENAI_MODEL_DEPLOYMENT_NAME="gpt-4o"
Hugging Face Models Locally#
For models downloaded from Hugging Face and served locally via vLLM:
Qwen3-VL:
If HF_TOKEN is already set:
VLM_MODEL_TO_USE=vllm-compatible
MODEL_PATH=git:https://huggingface.co/Qwen/Qwen3-VL-30B-A3B-Instruct
If HF_TOKEN is not set, embed the token directly in the URL:
VLM_MODEL_TO_USE=vllm-compatible
MODEL_PATH=git:https://user:<huggingface_token>@huggingface.co/Qwen/Qwen3-VL-30B-A3B-Instruct
Qwen3.5 / Qwen 3.5 MoE:
The service detects the Qwen3.5 architecture from the model config and
selects the bundled vLLM runtime automatically. No extra configuration is
required beyond MODEL_PATH.
VLM_MODEL_TO_USE=vllm-compatible
MODEL_PATH=git:https://huggingface.co/Qwen/Qwen3.5-27B
Cosmos Reason 3 Reasoner:
Cosmos Reason 3 Reasoner is served by setting
VLM_MODEL_TO_USE=cosmos-reason3 and pointing MODEL_PATH at the
NGC model artifact with the ngc: prefix. Two checkpoint repositories are
supported:
# Nano Reasoner
VLM_MODEL_TO_USE=cosmos-reason3
MODEL_PATH=ngc:nim/nvidia/cosmos3-nano-reasoner:bf16-final
# Super Reasoner
VLM_MODEL_TO_USE=cosmos-reason3
MODEL_PATH=ngc:nim/nvidia/cosmos3-super-reasoner:bf16-final
Omni Native Audio Support#
Omni models, including Nemotron Nano Omni, provide native single-model video +
audio understanding. When VLM_MODEL_SUPPORTS_AUDIO=true is set, audio is
decoded and consumed natively by the model alongside video frames.
Required environment:
VLM_MODEL_TO_USE=vllm-compatible
MODEL_PATH=<HF or NGC path to Nemotron Nano Omni>
VLM_TRUST_REMOTE_CODE=true
VLM_MODEL_SUPPORTS_AUDIO=true # omit for video-only
INSTALL_PROPRIETARY_CODECS=true # required for proprietary audio codecs
Note
Set INSTALL_PROPRIETARY_CODECS=true when audio inputs may contain
proprietary audio codecs. Without it, the service falls back to the
default codec set and may fail to decode the audio track of such
inputs. The flag has no effect when audio is disabled.
Request side: pass enable_audio: true on POST /v1/generate_captions
to use native audio. For reasoning checkpoints, set
enable_reasoning: true; the response includes a reasoning_description
field in each chunk.
Response side: each chunk in chunk_responses includes an
audio_transcript field (when enable_audio is set). Native audio
understanding is available only on Omni models; other VLM models support
video and text input only.
For LVS integration, see Optional: Use Nemotron-3-Nano-Omni (audio-aware VLM).
Efficient Video Sampling (EVS)#
EVS prunes redundant video tokens at the VLM input to lower per-chunk
inference cost. Configure with VLM_VIDEO_PRUNING_RATE=<0.0-1.0>
(leave unset to disable).
EVS is supported on Nemotron Nano VL and Qwen 2.5 VL. It is not supported on Cosmos Reason1 or Cosmos Reason2 — setting the variable on those models has no effect.
Environment Variables Reference#
The shared list below covers variables common to the standalone Docker Compose stack and standalone Helm override.
Docker Compose and Helm Variables#
The table lists variables in standalone Docker Compose stack and the standalone Helm override.
Variable |
Description |
Standalone default |
|---|---|---|
|
Model source |
|
|
Custom model implementation path |
Empty |
|
NGC API key |
Compose: Empty; Helm: |
|
Hugging Face token |
Compose: Empty; Helm: |
|
NVIDIA API key for hosted endpoints |
|
|
GPU device IDs exposed to the container |
|
|
OpenAI-compatible API key |
|
|
Azure OpenAI API version |
Empty |
|
OpenAI-compatible VLM API key |
Compose: Empty; Helm: |
|
Backend selector |
|
|
VLM inference batch size |
Empty |
|
Number of VLM inference processes |
Empty |
|
Number of GPUs to use |
Compose: Empty; Helm: |
|
Number of GPUs per VLM process |
Empty |
|
Input frame width |
Empty |
|
Input frame height |
Empty |
|
Frame sampling rate or fixed frames per chunk |
|
|
Default system prompt |
Empty |
|
Maximum user-prompt length in characters |
|
|
Maximum generated tokens |
|
|
Enable native audio support for Omni models |
|
|
Enable trust of model-supplied remote code |
|
|
Install proprietary codecs at container startup |
|
|
Force software AV1 decode |
Empty |
|
Service logging verbosity |
Compose: Empty; Helm: |
|
Additional RT-VLM runtime arguments |
Empty |
|
RTSP latency override |
Empty |
|
RTSP timeout override |
Empty |
|
Time to wait between RTSP reconnection attempts |
|
|
RTSP reconnection window in seconds |
|
|
Maximum RTSP reconnection attempts |
|
|
GStreamer jitterbuffer drop-on-latency setting |
|
|
GStreamer jitterbuffer fast-start packet threshold |
|
|
Enable timestamp filtering for live streams |
|
|
Enable timestamp filtering for file streams |
|
|
Add timestamp metadata to VLM prompts |
Empty |
|
Empty CUDA cache after result handling |
|
|
Blocking timeout for stream deletion cleanup |
|
|
Enable GOP-aligned decode optimization |
|
|
Skip input media validation |
Empty |
|
vLLM GPU memory utilization fraction |
Empty |
|
Efficient Video Sampling pruning rate |
Compose: Empty; Helm: |
|
vLLM MoE backend override |
Empty |
|
Multimodal processor cache size |
|
|
vLLM multimodal tensor IPC setting |
Empty |
|
vLLM multimodal tensor IPC setting |
Empty |
|
vLLM multimodal encoder attention backend |
Empty |
|
vLLM package root used by runtime patches |
|
|
Enable NVFP4 CT emulation |
|
|
Enable Kafka publishing |
Compose: |
|
Kafka bootstrap servers |
Compose: |
|
VisionLLM message topic |
|
|
Incident topic |
|
|
Bounded queue size for async Kafka sends |
|
|
Kafka topic or Redis channel for error messages |
|
|
Publish errors to Redis instead of Kafka |
|
|
Redis host |
Compose: |
|
Redis application port |
|
|
Redis database number |
|
|
Enable OpenTelemetry |
|
|
OpenTelemetry resource attributes |
Empty |
|
OpenTelemetry traces exporter |
|
|
OpenTelemetry OTLP endpoint |
|
|
OpenTelemetry metric export interval in milliseconds |
|
Additional Helm Chart Values#
The chart injects KAFKA_BOOTSTRAP_SERVERS, REDIS_HOST,
REDIS_PORT, REDIS_DB, MODEL_PATH, NGC_API_KEY, and
VIA_VLM_API_KEY from chart values or Kubernetes secrets. When
useSharedNim=true, it also injects VIA_VLM_ENDPOINT and
VIA_VLM_OPENAI_MODEL_DEPLOYMENT_NAME.
Top-level Helm values
enabled: Enable the chart. Default:false; standalone override:true.image.repository,image.tag, andimage.pullPolicy: Image settings. Defaults:nvcr.io/nvidia/vss-core/vss-rt-vlm,3.2.0, andIfNotPresent.replicas: Number of replicas. Default:1.useSharedNim: Use a shared OpenAI-compatible NIM instead of loading a model in this pod. Default:false.modelPath: Model path whenuseSharedNim=false. Standalone override:ngc:nim/nvidia/cosmos-reason2-8b:0303-fp8-dynamic-kv8.sharedNimService,sharedNimPort,vlmBaseUrl,vlmName,viaVlmOpenAiModelDeploymentName, andnims.enabled: Shared or remote NIM routing values.ngcApiSecret.name,ngcApiSecret.key,hfTokenSecret.name, andhfTokenSecret.key: Secret references for NGC and Hugging Face tokens. The standalone override useshfTokenSecret.name=hf-token-secret.global.imagePullSecrets,global.ngcApiSecret.name,global.ngcApiSecret.key, andglobal.useReleaseNamePrefix: Umbrella chart global values.kafkaBootstrapServers,waitForKafka.enabled,waitForKafka.image.repository,waitForKafka.image.tag,waitForKafka.imagePullPolicy,waitForKafka.timeoutSeconds, andwaitForKafka.topics: Kafka connection and startup ordering values.redisHost,redisPort,redisDb, andredisPassword: Redis connection values.service.portandservice.type: Kubernetes service settings. Defaults:8000andClusterIP.securityContext.runAsUser,securityContext.runAsGroup,shmSize,resources.requests.nvidia.com/gpu, andresources.limits.nvidia.com/gpu: Pod security, shared memory, and GPU settings.env: List of RT-VLM environment variables.nodeSelectorandtolerations: Scheduling controls.
Frame Selection Modes#
RTVI VLM supports two frame selection modes for sampling frames from video chunks:
FPS-based Selection:
Enable
--use-fps-for-chunkingflagSet
--num-frames-per-second-or-fixed-frames-chunkto the desired frames per second (e.g.,0.05for 0.05 FPS)The system will sample frames at the specified rate based on chunk duration
Fixed Frame Selection (default):
Do not set
--use-fps-for-chunkingflag (disabled by default)Set
--num-frames-per-second-or-fixed-frames-chunkto the desired number of frames per chunk (e.g.,8for 8 frames)The system will sample a fixed number of equally-spaced frames from each chunk
Enabling Incidents#
To enable incident detection, set appropriate --prompt or --system-prompt
with clear Yes or No expectation. Incidents will be pushed to the incident Kafka
topic.
Example prompt:
--prompt "You are a warehouse monitoring system focused on safety and
efficiency. Analyze the situation to detect any anomalies such as workers
not wearing safety gear, leaving items unattended, or wasting time.
Respond in the following structured format:
Anomaly Detected: Yes/No
Reason: [Brief explanation]"
--system-prompt "Answer the user's question correctly in yes or no"
Troubleshooting#
Common Issues#
Container fails to start
Check
docker logs <container_name>for error messagesVerify GPU access: Ensure NVIDIA Container Toolkit is installed and
nvidia-smiworks
Out of Memory error
For example, larger models such as
Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 may need these
settings on NVIDIA RTX 4500, L40S, or Thor systems.
Set
NVIDIA_VISIBLE_DEVICES=<gpuid>to a free GPUReduce batch size: Try
VLM_BATCH_SIZE=32Default is auto-calculatedTune GPU memory utilization: Lower
VLLM_GPU_MEMORY_UTILIZATIONwhen model startup OOMs. Increase it only when KV-cache capacity is too low and free GPU memory remains.Reduce max sequences: Lower
VLLM_MAX_NUM_SEQSReduce concurrent processes: Lower
NUM_VLM_PROCSReduce max model length on lower-memory GPUs: Reduce
VLM_MAX_MODEL_LENCap generation length: Lower
VLM_MAX_GENERATION_TOKENS(default16384) to bound peak per-request memory.On Jetson Thor or DGX systems, ensure that the cache cleaner script is running.
Thor workaround for huge-model OOM
When running huge models such as
Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 on AGX Thor or
IGX Thor, allocate host swap before starting the RTVI VLM service:
sudo fallocate -l 96G /swapfile-nemotron
sudo chmod 600 /swapfile-nemotron
sudo mkswap /swapfile-nemotron
sudo swapon --priority 10 /swapfile-nemotron
Use conservative vLLM memory settings in Docker Compose .env or Helm
env values:
VLM_MAX_MODEL_LEN=2560
VLLM_GPU_MEMORY_UTILIZATION=0.55
Also ensure that the cache cleaner script is running on Thor.
System memory grows over time
For long-running workloads with many distinct videos or streams, keep the multimodal preprocessor cache disabled.
Docker Compose .env:
VLLM_DISABLE_MM_PREPROCESSOR_CACHE=true
Helm chart env values:
env:
- name: VLLM_DISABLE_MM_PREPROCESSOR_CACHE
value: "true"
Restart the service after changing these values. Re-enable the multimodal preprocessor cache only after validating memory behavior for your workload.
Port conflicts
Change
BACKEND_PORTif port 8000 is already in use
Kafka Connection Issues
Use
kafka:9092as bootstrap server when connecting from within Docker networkVerify Kafka is running:
docker ps | grep kafka
Health Check Failures
Check logs with
docker compose logs rtvi-vlm
Known Issues#
High concurrency with 8K vision tokens on Jetson Thor / DGX Spark
When running more than 2 concurrent live streams with a high vision-token budget (~8K vision tokens, i.e., 448×448 at 80 frames with Cosmos Reason2), the device may reboot or the microservice may crash due to memory pressure on resource-constrained edge platforms.
Recommendation: Limit concurrent live streams to 2 or fewer when using 8K vision tokens on Jetson Thor or DGX Spark.
Alternatively, reduce the vision-token budget by lowering the input resolution from 448×448 to 372×372 at 30 frames (~2K vision tokens) using
VLM_INPUT_WIDTH=372,VLM_INPUT_HEIGHT=372,VLM_DEFAULT_NUM_FRAMES_PER_SECOND_OR_FIXED_FRAMES_CHUNK=30to support higher concurrency.
Stream deletion latency under high concurrent load
When multiple live streams are being processed concurrently and the VLM
inference latency exceeds the chunk duration (e.g., processing takes longer
than the configured chunk_duration), deleting a stream via
DELETE /v1/streams/delete/{id} may take longer than expected. The delete
operation waits for the in-flight VLM inference request to complete before
the stream resources are released.
This is expected behavior — the server ensures the current inference cycle completes cleanly before tearing down the stream.
The delay is proportional to the VLM inference time at the current load. Reducing concurrency or increasing
chunk_durationwill reduce delete latency.
Duplicate live-stream / camera IDs rejected with HTTP 409
In 3.2.0, adding a stream with a camera_id (CV API) or streamId
that is already registered returns HTTP 409 (DuplicateCameraId /
DuplicateStreamId). In 3.1.0 the existing registration was silently
overwritten. Update client code to either remove the prior stream first
or surface the 409 to the caller.
Version Information#
The API version is v1. Check the service version using the health
check endpoints or by examining the OpenAPI schema at /docs.
API Reference