Overview#
The primary goal of nvmath-python is to bring the power of the NVIDIA math libraries to the Python ecosystem. The package aims to provide intuitive Pythonic APIs giving users full access to all the features offered by our libraries in a variety of execution spaces.
We hope to empower a wide range of Python users by providing easy access to high-performance core math operations such as FFT, dense and sparse linear algebra, and more. This includes the following groups of users:
Practitioners: Researchers and application programmers who require robust, high-performance mathematical tools.
Library Package Developers: Developers crafting libraries that rely on advanced mathematical operations.
CUDA Kernel Authors: Programmers who write CUDA kernels and need customized mathematical functionality.
The APIs provided by nvmath-python can be categorized into:
Host APIs: Invoked from the host and executed in the chosen space. While all host APIs support the GPU execution space, select APIs also support CPU and distributed (multi-node multi-GPU) execution spaces.
Device APIs: Called directly from within CUDA kernels.
The nvmath-python library is dedicated to delivering the following key features and commitments:
Interoperability with array and tensor libraries: nvmath-python provides seamless interoperability with widely-used array libraries such as NumPy, CuPy, and PyTorch, through APIs compatible with their data representations. nvmath-python should not be regarded as a replacement, but rather as a complementary tool to these libraries.
Logical Feature Parity: While the Pythonic API surface (the number of APIs and the complexity of each) is more concise compared to that of the C libraries, it provides access to their complete functionality.
Consistent Design Patterns: Uniform design across all modules to simplify user experience.
Transparency and Explicitness: Avoiding implicit, costly operations such as copying data across the same memory space, automatic type promotion, and alterations to the user environment or state (current device, current stream, etc.). This allows users to perform the required conversion once for use in all subsequent operations instead of incurring hidden costs on each call.
Clear, Actionable Error Messages: Ensuring that errors are informative and helpful in resolving the problem.
DRY Principle Compliance: Automatically utilizing available information such as the current stream and memory pool to avoid redundant specification (“don’t repeat yourself”).
With nvmath-python, a few lines of code are sufficient to unlock the extensive performance capabilities of the NVIDIA math libraries. Explore our sample Python codes and more detailed examples in the examples directory on GitHub.
Architecture#
nvmath-python is designed to support integration at any level desired by the user. This flexibility allows:
Alice, a Python package developer, to utilize core math operations to compose into higher-level algorithms or adapt these operations into her preferred interfaces.
Bob, an application developer, to use core operations directly from nvmath-python or indirectly through other libraries that leverage nvmath-python.
Carol, a researcher, to write kernels entirely in Python that call core math operations such as FFT.
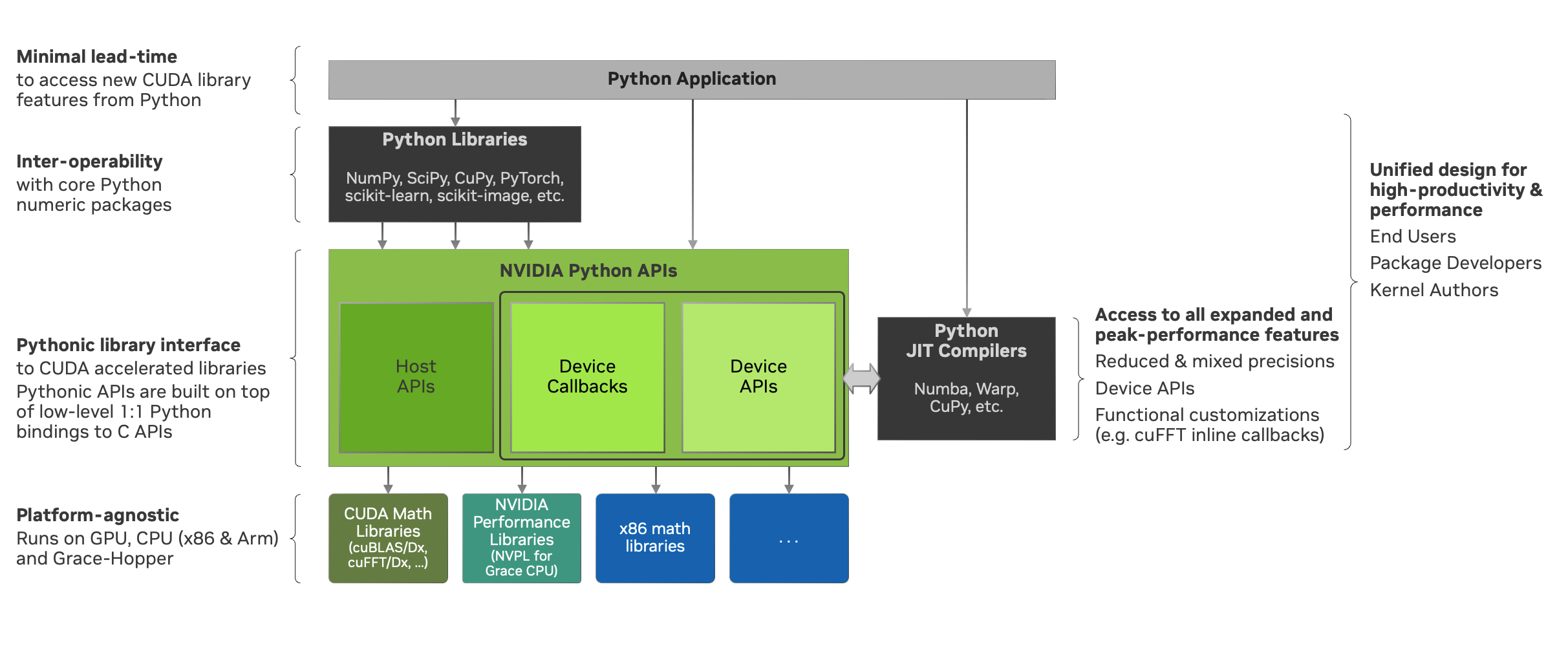
Additionally, we offer Python bindings that provide a 1:1 mapping with the C APIs. These bindings, which serve as wrappers with API signatures similar to their C counterparts, are ideal for library developers looking to integrate the capabilities of the NVIDIA Math Libraries in a customized manner, in the event that the Pythonic APIs don’t meet their specific requirements. Conversely, our high-level Pythonic APIs deliver a fully integrated solution suitable for native Python users as well as library developers, encompassing both host and device APIs. Select host APIs accept callback functions written in Python, which are compiled into supported formats such as LTO-IR, using compilers like Numba.
Host APIs#
nvmath-python provides a collection of APIs that can be directly invoked from the CPU (host). At present, these APIs encompass a selection of functionalities within the following categories:
Fast Fourier Transform in
nvmath.. Refer to Fast Fourier Transform for details.fft Dense Linear Algebra in
nvmath.. Refer to Linear Algebra for details.linalg Sparse Linear Algebra in
nvmath.. Refer to Sparse Linear Algebra for details.sparse Tensor Algebra in
nvmath.. Refer to Tensor Operations for details.tensor
Effortless Interoperability#
All host APIs support input arrays/tensors from NumPy, CuPy, and PyTorch while returning output operands using the same package, thus offering effortless interoperability with these frameworks. One example for the interoperability is shown below:
import numpy as np
import nvmath
# Create a numpy.ndarray as input
a = np.random.random(128) + 1.j * np.random.random(128)
# Call nvmath-python Pythonic APIs
b = nvmath.fft.fft(a)
# Verify that output is also a numpy.ndarray
assert isinstance(b, np.ndarray)
Stateless and Stateful APIs#
The host APIs within nvmath-python can be generally categorized into two types: stateless function-form APIs and stateful class-form APIs.
Stateless function-form APIs, such as nvmath. and
nvmath., are designed for end-to-end results
with a single function call. These APIs are ideal for one-off computations without the
need for intermediate steps, customization of algorithm selection, or cost amortization of
preparatory steps.
Note
By design, nvmath-python does NOT cache plans with stateless function-form APIs. This is to enable library developers and others to use their own caching mechanisms with nvmath-python. Therefore users should use the stateful object APIs for repeated use as well as benchmarking to avoid incurring repeated preparatory costs, or use a cached API (see caching.py for an example implementation).
Stateful class-form APIs, like nvmath. and
nvmath., offer a more flexible approach.
These APIs follow a multi-phase design pattern: problem specification,
preparation (planning), execution, and resource release.
The planning phase can potentially be expensive, but once completed, it can be reused
across multiple executions by resetting operands as needed.
As such, they not only encompass the functionality found in their
function-form counterparts but also allow for amortization of one-time costs,
making them ideal for repeated operations and performance-critical code.
For detailed information on the design principles, lifecycle phases, and best practices for using stateful APIs, please refer to Stateful APIs Design Principles.
Generic and Specialized APIs#
Another way of categorizing the host APIs within nvmath-python is by splitting them into generic and specialized APIs, based on their flexibility and the scope of their functionality:
Generic APIs are designed to accommodate a broad range of operands and customization with these APIs is confined to options that are universally applicable across all supported operand types. For instance, the generic matrix multiplication API can handle structured matrices (such as triangular and banded, in full or packed form) in addition to dense full matrices, but the available options are limited to those applicable to all these matrix types.
Specialized APIs, on the other hand, are tailored for specific types of operands, allowing for full customization that is available to this kind. A prime example is the specialized matrix multiplication API for dense matrices, which provides numerous options specifically suited to dense matrices.
It should be noted that the notion of generic and specialized APIs is orthogonal to the
notion of stateful versus stateless APIs. Currently, nvmath-python offers the specialized
interface for dense matrix multiplication, in stateful and stateless
forms.
Full Logging Support#
nvmath-python provides integration with the Python standard library logger from the logging module to offer full logging of the computational details at various levels, for example debug, information, warning and error. An example illustrating the use of the global Python logger is shown below:
import logging
# Turn on logging with level set to "debug" and use a custom format for the log
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s %(levelname)-8s %(message)s',
datefmt='%m-%d %H:%M:%S'
)
# Call nvmath-python Pythonic APIs
out = nvmath.linalg.advanced.matmul(...)
Alternatively, for APIs that contain the options argument, users can set a custom logger
by directly passing it inside a dictionary or as part of the corresponding Options
object, for example nvmath. for nvmath. and
nvmath.. An example based on FFT is shown below:
import logging
# Create a custom logger
logger = logging.getLogger('userlogger')
...
# Call nvmath-python Pythonic APIs
out = nvmath.fft.fft(..., options={'logger': logger})
For the complete examples, refer to global logging example and custom user logging example.
Note
The Python logging is orthogonal to the logging provided by certain NVIDIA math libraries,
which encapsulates low level implementation details and can be activated via either
specific environment variables (for example CUBLASLT_LOG_LEVEL for cuBLASLt) or
programmatically through the Python bindings (for example
nvmath. for cuSOLVER).
Call Blocking Behavior#
By default, calls to all Pythonic host APIs that require GPU execution are non-blocking if
the input operands reside on the device. This means that free functions like
nvmath. or stateful class
methods like nvmath., nvmath.
will return immediately after the operation is launched on the GPU without waiting
for it to complete. Users are therefore responsible for
properly synchronizing the stream when needed. The default behavior can be modified by
setting the blocking attribute (default 'auto') of the relevant Options object
to True. For example, users may set nvmath. to True
and pass this options object to the corresponding FFT API calls. If the input operands are
on the host, the Pythonic API calls will always block since the computation yields an output
operand that will also reside on the host. Meanwhile, APIs that execute on the host (such as
nvmath.) always block.
Stream Semantics#
Stream semantics depend on two aspects: whether execution is blocking or non-blocking (see Call Blocking Behavior) and whether the API is a free function or a stateful class. When execution is blocking, stream ordering is automatically handled by nvmath-python for operations performed within the package. When execution is non-blocking, it is the user’s responsibility to ensure correct stream ordering. In both cases, if all operations use the default stream (or a single user-provided stream), no explicit stream ordering is needed.
For a detailed discussion of stream semantics — including the differences between free-function and stateful-class APIs, code examples for blocking and non-blocking scenarios, and stream-ordered deallocation pitfalls — see the dedicated Stream Semantics page. For examples on stream ordering, refer to FFT with multiple streams.
Memory Management#
By default, the host APIs use the memory pool from the package that their operands belong
to. This ensures that there is no contention for memory or spurious out-of-memory errors.
However, the user also has the ability to provide their own memory allocator if they choose
to do so. In our Pythonic APIs, we support an EMM-like interface as proposed and
supported by Numba for users to set their Python mempool. Taking FFT as an example, users
can set the option nvmath. to a Python object complying with
the nvmath. protocol, and pass the options to the high-level
APIs like nvmath. or nvmath.. Temporary memory allocations
will then be done through this interface. Internally, we use the same interface to use CuPy
or PyTorch’s mempool depending on the operands.
Note
nvmath’s BaseCUDAMemoryManager protocol is slightly different from
Numba’s EMM interface (numba.cuda.BaseCUDAMemoryManager), but duck typing with
an existing EMM instance (not type!) at runtime should be possible.
Host APIs with Callbacks#
Certain host APIs (such as nvmath. and nvmath.) allow the
user to provide prolog or epilog functions written in Python, resulting in a fused
kernel. This improves performance by avoiding extra roundtrips to global memory and
effectively increases the arithmetic intensity of the operation.
import cupy as cp
import nvmath
# Create the data for the batched 1-D FFT.
B, N = 256, 1024
a = cp.random.rand(B, N, dtype=cp.float64) + 1j * cp.random.rand(B, N, dtype=cp.float64)
# Compute the normalization factor.
scale = 1.0 / N
# Define the epilog function for the FFT.
def rescale(data_out, offset, data, user_info, unused):
data_out[offset] = data * scale
# Compile the epilog to LTO-IR (in the context of the execution space).
with a.device:
epilog = nvmath.fft.compile_epilog(rescale, "complex128", "complex128")
# Perform the forward FFT, applying the filter as an epilog...
r = nvmath.fft.fft(a, axes=[-1], epilog={"ltoir": epilog})
Device APIs#
The device APIs enable the user to call core mathematical operations in their Python CUDA kernels, resulting in a fully fused kernel. Fusion is essential for performance in latency-dominated cases to reduce the number of kernel launches, and in memory-bound operations to avoid the extra roundtrip to global memory.
We currently offer support for calling FFT, matrix multiplication, and random number generation APIs in kernels written using Numba, with plans to offer more core operations and support other compilers in the future. The design of the device APIs closely mimics that of the C++ APIs from the corresponding NVIDIA Math Libraries (MathDx libraries cuFFTDx and cuBLASDx for FFT and matrix multiplication, and cuRAND device APIs for random number generation).
Compatibility Policy#
nvmath-python is no different from any Python package, in that we would not succeed without depending on, collaborating with, and evolving alongside the Python community. Given these considerations, we strive to meet the following commitments:
For the low-level Python bindings,
if the library to be bound is part of CUDA Toolkit, we support the library from the most recent two CUDA major versions (currently CUDA 12/13)
otherwise, we support the library within its major version
Note that all bindings are currently experimental.
For the high-level Pythonic APIs, we maintain backward compatibility to the greatest extent feasible. When a breaking change is necessary, we issue a runtime warning to alert users of the upcoming changes in the next major release. This practice ensures that breaking changes are clearly communicated and reserved for major version updates, allowing users to prepare and adapt without surprises.
We comply with NEP-29 and support a community-defined set of core dependencies (CPython, NumPy, etc).
Note
The policy on backwards compatibility will apply starting with release 1.0.0.