Facial Landmarks Estimation
The facial landmarks estimator network aims to predict the (x,y) location of landmarks (keypoints) for a given input face image. FPENet (Fiducial Points Estimator Network) is generally used in conjunction with a face detector and the output is commonly used for face alignment, head pose estimation, emotion detection, eye blink detection, gaze estimation, among others. Besides the facial landmarks, key points estimator can also be used to predict the keypoints for general-purpose applications.
The FPENet app requires the data to be in a specific json format to be converted to TFRecords. To do so, the tool requires a configuration file as input. Configuration file details and sample usage examples are included in the following sections.
The ground truth dataset is created by labeling ground-truth facial keypoints by human labelers. If you are looking to re-train with your own dataset, follow the guideline below.
Label the keypoints in the correct order as accuractely as possible. The human labeler would be able to zoom in to a face region to correctly localize the keypoint.
For keypoints that are not easily distinguishable such as chin or nose, the best estimate should be made by the human labeler. Some keypoints are easily distinguishable such as mouth corners or eye corners.
Label a keypoint as “occluded” if the keypoint is not visible due to an external object or due to extreme head pose angles. A keypoint is considered occluded when the keypoint is in the image but not visible.
To reduce discrepancy in labeling between multiple human labelers, the same keypoint ordering and instructions should be used across labelers. An independent human labeler may be used to test the quality of the annotated landmarks and potential corrections.
The Sloth and Label Studio tools may be used for labeling.
The dataset format is described in the Labeling Data Format section.
Configuration File for Dataset Converter
A sample dataset configuration file is shown below.
sets: [dataset1, dataset2]
gt_path: 'GT'
save_path: 'models/tfrecords'
gt_root_path: '/workspace/tao-experiments/data/'
save_root_path: '/workspace/tao-experiments/'
image_root_path: '/workspace/tao-experiments/'
tfrecord_folder: 'FpeTfRecords'
tfrecord_name: 'data.tfrecords'
num_keypoints: 80
bbox_enlarge_ratio: 1.0
Parameter |
Datatype |
Description |
Default |
Supported Values |
|---|---|---|---|---|
sets |
list | Set IDs to extract as a list. Example- [set1, set2, set3]. | – | – |
gt_path |
string | Ground truth json path. | – | – |
save_path |
string | Save path for TF Records. | – | – |
gt_root_path |
string | Root path for ground truth jsons (if any). This path is pre-pended to the gt_path while reading jsons. | – | – |
save_root_path |
string | Root path for saving tfrecords data (if any). This path is pre-pended to the save_path for each set. | – | – |
image_root_path |
string | Root path for the images (if any). This path will be pre-pended to the image paths in jsons. | – | – |
tfrecord_folder |
string | TF record folder name to generate. This folder will be created if not exists. | – | – |
tfrecord_name |
string | TF record file name to generate. | – | – |
num_keypoints |
int | Number of keypoints. | – | >0 |
bbox_enlarge_ratio |
float | Scale to enlarge face bounding box with. | – | – |
Sample Usage of the Dataset Converter Tool
tao model fpenet dataset_convert -e dataset_config.yaml
To do training, evaluation and inference for FPENet, several components need to be configured, each with their own parameters. The commands for a FPENet experiments share the same configuration file.
The specification file configures these components:
Trainer
Model
Loss
Dataloader
Optimizer
Trainer Config
The Trainer config consists of some common args for running the FPENet app and it also encompasses the other configs: model, loss, dataloader, and optimizer.
__class_name__: FpeNetTrainer
checkpoint_dir: /workspace/tlt-expertiments/fpenet/
checkpoint_n_epoch: 1
enable_visualization: true
log_every_n_secs: 10
num_epoch: 20
num_keypoints: 80
random_seed: 35
visualize_num_images: 3
model:
...
loss:
...
optimizer:
...
dataloader:
...
Argument |
Datatype |
Description |
Default |
Supported Values |
|---|---|---|---|---|
checkpoint_dir |
string | The directory to save/load model checkpoints. | None | – |
checkpoint_n_epoch |
int | Number of epoch at which checkpoint is saved. | 1 | 1 to num_epoch |
enable_visualization |
boolean | Enable visualization in tensorboard. | True | True/False |
log_every_n_secs |
int | Logging frequency in seconds. | 60 | – |
num_epoch |
int | Total number of epochs to train. | 40 | – |
num_keypoints |
int | Number of keypoints. | 80 | > 0 |
random_seed |
int | Random seed for initialization. | 42 | – |
visualize_num_images |
int | Number of images to visualize per epoch. | 3 | – |
| model | Model config. | – | – | |
| loss | Loss config. | – | – | |
| optimizer | Optimizer config. | – | – | |
| dataloader | Dataloader config. | – | – |
Model Config
Configuration section to provide model related parameters.
Sample model config is shown below.
model:
__class_name__: FpeNetBaseModel
model_parameters:
beta: 0.01
pretrained_model_path: /workspace/tao-experiments/pretrained_models/public/model.tlt
regularizer_type: l2
regularizer_weight: 1.0e-05
type: FpeNet_public
| Parameter | Datatype | Description | Default | Supported Values |
pretrained_model_path |
string | Path to pre-trained model to load weights from. | None | – |
regularizer_type |
string | Type of weights regularizer. | – | “l1”, “l2” |
regulaizer_weight |
float | Weight for regularizer. | – | – |
type |
string | Model type. | – | “FpeNet_public”, “FpeNet_release” |
Loss Config
Configuration section to provide loss related parameters.
Sample loss config is shown below.
loss:
__class_name__: FpeLoss
kpts_coeff: 0.01
loss_type: square_euclidean
mask_occ: true
weights_dict: null
elt_loss_info:
elt_alpha: 0.5
enable_elt_loss: true
modulus_spatial_augmentation:
hflip_probability: 0.0
rotate_rad_max: 0.35
translate_max_x: 10
translate_max_y: 10
zoom_max: 1.2
zoom_min: 0.8
Parameter |
Datatype |
Description |
Default |
Supported Values |
|---|---|---|---|---|
kpts_coeff |
float | Coefficient the loss is multiplied with. | 0.01 | – |
loss_type |
string | Type of loss to use. | “l1” | “l1”, “square_euclidean”, “wing_loss” |
mask_occ |
boolean | If True, will mask all occluded points. | False | – |
weights_dict |
dictionary | Contains the weights for the “eyes”, the “mouth”, and the rest of the “face”. These dict keys must be present, and the elements must sum up to 1 | None | – |
elt_loss_info |
elt loss config | Dictionary about ELT loss. | – |
The parameter weights_dict only supports 68, 80, or 104 facial landmarks.
ELT Loss configuration used by FpeNet.
Defined in- Improving Landmark Localization with Semi-Supervised Learning” CVPR’2018
Parameter |
Datatype |
Description |
Default |
Supported Values |
|---|---|---|---|---|
elt_alpha |
float | Weight for ELT loss. | None | – |
enable_elt_loss |
boolean | Flag to enable ELT loss. | None | True/False |
| modulus_spatial_augmentation | dictionary | Spatial augmentation configuration parameters. hflip_probability: Probability for horizontal flipping. rotate_rad_max: Maximum rotation in radians. translate_max_x: Maximum pixel translate in x direction. translate_max_y: Maximum pixel translate in y direction. zoom_max: Zoom ratio maximum. zoom_min: Zoom ratio minimum. | hflip_probability: 0.0 rotate_rad_max: 0.0 translate_max_x: 0.0 translate_max_y: 0.0 zoom_max: 1.0 zoom_min: 1.0 | hflip_proability: 0.0 - 1.0 rotate_rad_max: - translate_max_x: 0 - image dims translate_max_y: 0 - image dims zoom_max: - zoom_min: - |
The parameter hflip_probability should be set to 0.0 when using FPENet for general-purpose applications.
Dataloader Config
Configuration section to provide data related parameters.
Sample dataloader config is shown below.
dataloader:
__class_name__: FpeNetDataloader
augmentation_info:
augmentation_resize_probability: 0.5
augmentation_resize_scale: 1.6
enable_occlusion_augmentation: true
enable_online_augmentation: true
enable_resize_augmentation: true
gamma_augmentation:
gamma_max: 1.6
gamma_min: 0.6
gamma_probability: 0.1
gamma_type: uniform
modulus_spatial_augmentation:
hflip_probability: 0.25
rotate_rad_max: 0.35
translate_max_x: 10
translate_max_y: 10
zoom_max: 1.2
zoom_min: 0.8
patch_probability: 0.5
size_to_image_ratio: 0.5
mask_augmentation_patch: true
batch_size: 64
dataset_info:
image_extension: png
no_occlusion_masking_sets: s578-usercalibration-incar-0 s578-usercalibration-incar-1
root_path: /workspace/tao-experiments/
tfrecord_folder_name: FpeTfRecords
tfrecords_directory_path: /workspace/tao-experiments/models/tfrecords
tfrecords_set_id_train: s578-usercalibration-incar-0
tfrecords_set_id_val: s578-usercalibration-incar-0
tfrecord_file_name: data.tfrecords
image_info:
image:
channel: 1
height: 80
width: 80
kpiset_info:
tfrecords_set_id_kpi: s578-usercalibration-incar-1
num_keypoints: 80
Parameter |
Datatype |
Description |
Default |
|---|---|---|---|
batch_size |
int | The batch size for training/evaluation | – |
|
|
dataset proto config |
Information about the input dataset
* image_extension (string): The image extension. Currently, FPENet only supports the |
– |
|
|
image_info proto config |
Information about the input image
* channel (int): The number of channels. Options include 1 (grayscale image) and 3 (RGB image). |
– |
|
|
kpiset_info proto config |
Information for KPI evaluation * tfrecords_set_id_kpi (string): The space separated names of the datasets |
– |
num_keypoints |
int | The number of keypoints | – |
|
|
augmentation proto config |
Information on augmentation config
* enable_resize_augmentation (boolean): A flag to enable resize augmentation
* gamma_max (float): The maximum value for gamma uniform distribution * modulus_spatial_augmentation
* hflip_probability (float): Probability for horizontal flipping. It should be set to 0.0 when using FPENet for general-purpose applications.
* patch_probability (float): The probability for adding occlusion augmentation |
– |
Optimizer Config
Configuration section to provide optimizer related parameters. The optimizer can be conifigured in the under the optimizer section in the config.
Sample optimizer config is shown below.
optimizer:
__class_name__: AdamOptimizer
beta1: 0.9
beta2: 0.999
epsilon: 1.0e-08
learning_rate_schedule:
__class_name__: SoftstartAnnealingLearningRateSchedule
annealing: 0.5
base_learning_rate: 0.0005
last_step: 1000000
min_learning_rate: 1.0e-07
soft_start: 0.3
| Parameter | Datatype | Description | Default | Supported Values |
| optimizer | optimizer proto config | This parameter defines which optimizer to use for training, and the parameters to configure it, namely:
|
epsilon - NA beta1 - 0.0 - 1.0 beta2 - 0.0 - 1.0 | |
| learning rate | learning rate scheduler proto | This parameter configures the learning rate schedule for the trainer.
Currently FPENet only supports softstart annealing learning rate schedule,
and maybe configured using the following parameters:
|
soft_start _annealing _schedule | soft_start - 0.0 - 1.0 annealing - 0.0 - 1.0 minimum_learning_rate - 0.0 - 1.0 maximum_learning_rate - 0.0 - 1.0 |
The soft-start annealing learning rate schedule- the learning rate when plotted as a function of the training progress (0.0, 1.0) results in the following curve.
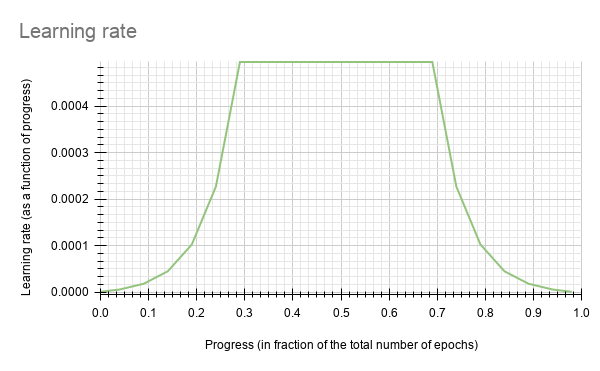
In the above figure, the soft start was set as 0.3 and annealing as 0.7 with minimum learning rate as 5e-6 and a maximum learning rate or base_lr as 5e-4.
Complete Sample Experiment Spec File
__class_name__: FpeNetTrainer
checkpoint_dir: /workspace/tlt-expertiments/fpenet/
checkpoint_n_epoch: 1
dataloader:
__class_name__: FpeNetDataloader
augmentation_info:
augmentation_resize_probability: 0.5
augmentation_resize_scale: 1.6
enable_occlusion_augmentation: true
enable_online_augmentation: true
enable_resize_augmentation: true
gamma_augmentation:
gamma_max: 1.6
gamma_min: 0.6
gamma_probability: 0.1
gamma_type: uniform
modulus_spatial_augmentation:
hflip_probability: 0.25
rotate_rad_max: 0.35
translate_max_x: 10
translate_max_y: 10
zoom_max: 1.2
zoom_min: 0.8
patch_probability: 0.5
size_to_image_ratio: 0.5
mask_augmentation_patch: true
batch_size: 64
dataset_info:
image_extension: png
no_occlusion_masking_sets: s578-usercalibration-incar-0 s578-usercalibration-incar-1
root_path: /workspace/tao-experiments/
test_file_name: data.tfrecords
tfrecord_folder_name: FpeTfRecords
tfrecords_directory_path: /workspace/tao-experiments/models/tfrecords
tfrecords_set_id_train: s578-usercalibration-incar-0
tfrecords_set_id_val: s578-usercalibration-incar-0
tfrecord_file_name: data.tfrecords
use_extra_dataset: false
image_info:
image:
channel: 1
height: 80
width: 80
kpiset_info:
tfrecords_set_id_kpi: s578-usercalibration-incar-1
num_keypoints: 80
enable_visualization: true
hooks: null
infrequent_summary_every_n_steps: 0
log_every_n_secs: 10
loss:
__class_name__: FpeLoss
kpts_coeff: 0.01
loss_type: square_euclidean
mask_occ: true
weights_dict: null
elt_loss_info:
elt_alpha: 0.5
enable_elt_loss: true
modulus_spatial_augmentation:
hflip_probability: 0.0
rotate_rad_max: 0.35
translate_max_x: 10
translate_max_y: 10
zoom_max: 1.2
zoom_min: 0.8
model:
__class_name__: FpeNetBaseModel
model_parameters:
beta: 0.01
dropout_rate: 0.5
freeze_Convlayer: null
pretrained_model_path: /workspace/tao-experiments/pretrained_models/public/model.tlt
regularizer_type: l2
regularizer_weight: 1.0e-05
train_fpe_model: true
type: FpeNet_public
use_less_face_layers: false
use_upsampling_layer: false
visualization_parameters: null
num_epoch: 20
num_keypoints: 80
optimizer:
__class_name__: AdamOptimizer
beta1: 0.9
beta2: 0.999
epsilon: 1.0e-08
learning_rate_schedule:
__class_name__: SoftstartAnnealingLearningRateSchedule
annealing: 0.5
base_learning_rate: 0.0005
last_step: 1000000
min_learning_rate: 1.0e-07
soft_start: 0.3
random_seed: 35
visualize_num_images: 3
A utility to train a model with the specified parameters.
Input: Images of (80, 80, 1)
Output: (N, 2) keypoint locations. (N, 1) keypoint confidence. N is the number of keypoints.
Sample Usage of the Train tool
tao model fpenet train -e <Experiment_Spec_File.yaml> -r <Results Folder> -k <Encode Key>
-e: Path to experiment spec file.-r: Results folder directory to save models.-k: Encryption key for model saving/loading.
A utility to evaluate a trained model on test data and generate KPI information.
The metric is the region keypoints pixel error. The region keypoint pixel error is the mean euclidean error in pixel location prediction as compared to the ground truth. We bucketize and average the error per face region (eyes, mouth, chin, etc.).
Sample Usage of the Evaluate tool
tao model fpenet evaluate -m <Results Folder> -k <Encode Key>
-m: Path to trained model folder.-e: Experiment spec filename (if different from “experiment_spec.yam”).-k: Encryption key for model loading.
A utility to run inferences in sample images using a trained model. The utility inputs images with ground truth face bounding box information and generates the list of predictions for each image.
[
{
"filename": "image1.png",
"annotations": [
{
"face_tight_bboxx": 415.10368330073106,
"face_tight_bboxy": 243.97163120567382,
"tool-version": "1.0",
"face_tight_bboxwidth": 320.35730960707053,
"face_tight_bboxheight": 329.25550579091134,
"class": "FaceBbox"
}
],
"class": "image"
},
{
"filename": "image2.png",
"annotations": [
{
"face_tight_bboxx": 414.44551830055445,
"face_tight_bboxy": 243.935820979011,
"tool-version": "1.0",
"face_tight_bboxwidth": 321.0993074943171,
"face_tight_bboxheight": 340.87266938197325,
"class": "FaceBbox"
}
],
"class": "image"
}
]
Sample Usage of the Inference tool
tao model fpenet inference -e <Experiment Spec File> -i <Json File With Images> -m <Trained TAO Model Path> -k <Encode Key> -o <Output Folder> -r <Images Root Directory>
-e: Path to experiment spec file.-i: Path to json file with inference image paths and face bounding box information.-m: Path to the trained model path to infer images with. The model can be in.tltor.engineformat.-k: Encryption key for model loading.-o: The directory to save the output images and predictions.-r: Parent directory (if any) for the image paths in inference jsons.
TAO Toolkit provides a utility for exporting a trained model to an encrypted onnx format or a TensorRT deployable engine format.
The export sub-task optionally generates the calibration cache for TensorRT INT8 engine
calibration.
Exporting the model decouples the training process from deployment and allows for conversion to
TensorRT engines outside the TAO environment. TensorRT engines are specific to each hardware
configuration and should be generated for each unique inference environment. This may be
interchangeably referred to as a .trt or .engine file. The same exported TAO model
may be used universally across training and deployment hardware. This is referred to as the
.etlt file, or encrypted TAO file. During model export, the TAO model is encrypted with a
private key, which is required when you deploy this model for inference.
INT8 Mode Overview
TensorRT engines can be generated in INT8 mode to run with lower precision, thus improving
performance. This process requires a cache file that contains scale factors
for the tensors to help combat quantization errors, which may arise due to low-precision arithmetic.
The calibration cache is generated using a calibration tensorfile when export is
run with the --data_type flag set to int8. Pre-generating the calibration
information and caching it removes the need for calibrating the model on the inference machine.
Moving the calibration cache is usually much more convenient than moving the calibration tensorfile
since it is a much smaller file and can be moved with the exported model. Using the calibration
cache also speeds up engine creation, as building the cache can take several minutes to generate
depending on the size of the Tensorfile and the model itself.
The export tool can generate an INT8 calibration cache by ingesting a sampled subset of training data. You need to create a sub-sampled directory of random images that best represent your test dataset. We recommend using at least 10-20% of the training data. The more data provided during calibration, the closer int8 inferences are to fp32 inferences. A helper script is provided with the sample notebook to select the subset data from the given training data.
Based on the evaluation results of the INT8 model, you might need to adjust the number of sampled images or the kind of selected to images to better represent the test dataset. You can also use a portion of data from the test data for calibration to improve the results.
FP16/FP32 Model
The calibration.bin is only required if you need to run inference at INT8 precision. For
FP16/FP32 based inference, the export step is much simpler. All that is required is to provide
a model from the train step to export to convert it into an encrypted TAO
model.
Sample Usage of the Export tool
tao model fpenet export -m <Trained TAO Model Path> -k <Encode Key> -o <Output file .etlt>
-m: The path to the trained model to be exported-k: The encryption key for model loading-o: The path to the output.etltfile (.etltis appended to model path otherwise)-t: The target opset value for onnx conversion. The default value is 10--cal_data_file: The path to the calibration data file (.tensorfile)--cal_image_dirThe path to a directory with calibration image samples--cal_cache_fileThe path to the calibration file (.bin)--data_type: The data type for the TensorRT export. The options arefp32andint8.--batches: The number of images per batch. The default value is 1.--max_batch_size: The maximum batch size for the TensorRT engine builder. The default value is 1.--max_workspace_size: The maximum workspace size to be set for the TensorRT engine builder--batch_size: The number of batches to calibrate over. The default value is 1.--engine_file: The path to the exported TRT engine. Generates an engine file if specified.--input_dims: Input dims in channels first(CHW) or channels last (HWC) format as comma separated integer values. Default 1,80,80.--backend: The model type to export to.
INT8 Export Mode Required Arguments
--cal_image_dir: The directory of images that is preprocessed and used for calibration.--cal_data_file: The tensorfile generated using images incal_image_dirfor calibrating the engine. If this already exists, it is directly used to calibrate the engine. The INT8 tensorfile is a binary file that contains the preprocessed training samples.
The --cal_image_dir parameter applies the necessary preprocessing
to generate a tensorfile at the path mentioned in the --cal_data_file
parameter, which is in turn used for calibration. The number of generated batches in the
tensorfile is obtained from the value set to the --batches parameter,
and the batch_size is obtained from the value set to the --batch_size
parameter. Ensure that the directory mentioned in --cal_image_dir has at least
batch_size * batches number of images in it. The valid image extensions are
.jpg, .jpeg, and .png.
INT8 Export Optional Arguments
--cal_cache_file: The path to save the calibration cache file to. The default value is./cal.bin. If this file already exists, the calibration step is skipped.--batches: The number of batches to use for calibration and inference testing. The default value is 10.--batch_size: The batch size to use for calibration. The default value is 1.--max_batch_size: The maximum batch size of the TensorRT engine. The default value is 1.--max_workspace_size: The maximum workspace size of the TensorRT engine. The default value is2 * (1 << 30).--experiment_spec: The experiment_spec used for training. This argument is used to obtain the parameters to preprocess the data used for calibration.--engine_file: The path to the serialized TensorRT engine file. Note that this file is hardware specific and cannot be generalized across GPUs. Use this argument to quickly test your model accuracy using TensorRT on the host. As the TensorRT engine file is hardware specific, you cannot use this engine file for deployment unless the deployment GPU is identical to the training GPU.
For instructions on generating a TensorRT engine using the trtexec command, refer to the
trtexec guide for Facial Landmarks Estimation.
Deploying to DeepStream
The pretrained model for FPENet provided through NGC is available by default with DeepStream 6.0.
For more details, refer to DeepStream TAO Integration for FPENet.