RetinaNet
With RetinaNet, the following tasks are supported:
dataset_convert
train
evaluate
prune
inference
export
These tasks may be invoked from the TAO Toolkit Launcher by following the below mentioned convention from command line:
tao model retinanet <sub_task> <args_per_subtask>
where, args_per_subtask are the command line arguments required for a given subtask. Each
of these sub-tasks are explained in detail below.
The object detection apps in TAO Toolkit expect data in KITTI format for training and evaluation.
See the Data Annotation Format page for more information about the KITTI data format.
The RetinaNet dataloader supports the raw KITTI formatted data as well as TFrecords.
To use TFRecords for optimized iteration across the data batches, the the raw input data need to be converted to TFRecords format first.
This can be done using the dataset_convert subtask. Currently, the KITTI and COCO formats are supported.
The dataset_convert tool requires a configuration file as input. Details of the
configuration file and examples are included in the following sections.
Configuration File for Dataset Converter
The dataset_convert tool provides several configurable parameters. The parameters are encapsulated in
a spec file to convert data from the original annotation format to the TFRecords format which the trainer can ingest.
KITTI and COCO formats can be configured by using either kitti_config or coco_config
respectively. You may use only one of the two in a single spec file.
The spec file is a prototxt format file with following global parameters:
kitti_config: A nested prototxt configuration with multiple input parameterscoco_config: A nested prototxt configuration with multiple input parametersimage_directory_path: The path to the dataset root. Theimage_dir_nameis appended to this path to get the input images and must be the same path specified in the experiment spec file.target_class_mapping: The prototxt dictionary that maps the class names in the tfrecords to the target class to be trained in the network.
kitti_config
Here are descriptions of the configurable parameters for the kitti_config field:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
| root_directory_path | string | – | The path to the dataset root directory | – |
| image_dir_name | string | – | The relative path to the directory containing images from the path in root_directory_path. | – |
| label_dir_name | string | – | The relative path to the directory containing labels from the path in root_directory_path. | – |
| partition_mode | string | – | The method employed when partitioning the data to multiple folds. Two methods are supported:
|
|
| num_partitions | int | 2 (if partition_mode is random) | The number of partitions to use to split the data (N folds). This field is ignored when the partition model is set to random, as by default only two partitions are generated: val and train. In sequence mode, the data is split into n-folds. The number of partitions is ideally fewer than the total number of sequences in the kitti_sequence_to_frames file. | n=2 for random partition n< number of sequences in the kitti_sequence_to_frames_file |
| image_extension | str | .png | The extension of the images in the image_dir_name parameter. | .png .jpg .jpeg |
| val_split | float | 20 | The percentage of data to be separated for validation. This only works under “random” partition mode. This partition is available in fold 0 of the TFrecords generated. Set the validation fold to 0 in the dataset_config. | 0-100 |
| kitti_sequence_to_frames_file | str | The name of the KITTI sequence to frame mapping file. This file must be present within the dataset root as mentioned in the root_directory_path. | ||
| num_shards | int | 10 | The number of shards per fold. | 1-20 |
The sample configuration file shown below converts the 100% KITTI dataset to the training set.
kitti_config {
root_directory_path: "/workspace/tao-experiments/data/"
image_dir_name: "training/image_2"
label_dir_name: "training/label_2"
image_extension: ".png"
partition_mode: "random"
num_partitions: 2
val_split: 0
num_shards: 10
}
image_directory_path: "/workspace/tao-experiments/data/"
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
target_class_mapping {
key: "truck"
value: "car"
}
coco_config
Here are descriptions of the configurable parameters for the coco_config field:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
| root_directory_path | string | – | The path to the dataset root directory | – |
| image_dir_names | string (repated) | – | The relative path to the directory containing images from the path in root_directory_path for each partition. | – |
| annotation_files | string (repated) | – | The relative path to the directory containing JSON file from the path in root_directory_path for each partition. | – |
| num_partitions | int | 2 | The number of partitions in the data. The number of partition must match the length of the list for image_dir_names and annotation_files. By default, two partitions are generated: val and train. | n==len(annotation_files) |
| num_shards | int (repeated) | [10] | The number of shards per partitions. If only one value is provided, same number of shards is applied in all partitions |
The sample configuration file shown below converts the COCO dataset with training and validation data where number of shard is 32 for validation and 256 for training.
coco_config {
root_directory_path: "/workspace/tao-experiments/data/coco"
image_dir_names: ["val2017", "train2017"]
annotation_files: ["annotations/instances_val2017.json", "annotations/instances_train2017.json"]
num_partitions: 2
num_shards: [32, 256]
}
image_directory_path: "/workspace/tao-experiments/data/coco"
Sample Usage of the Dataset Converter Tool
The dataset_convert tool is described below:
tao model retinanet dataset-convert [-h] -d DATASET_EXPORT_SPEC
-o OUTPUT_FILENAME
[-v]
You can use the following arguments:
-h, --help: Show this help message and exit-d, --dataset-export-spec: The path to the detection dataset spec containing the config for exporting.tfrecordfiles-o, --output_filename: The output filename-v: Enable verbose mode to show debug messages
The following example shows how to use the command with the dataset:
tao model retinanet dataset_convert -d /path/to/spec.txt
-o /path/to/tfrecords/train
Below is a sample for the RetinaNet spec file. It has 6 major components:
retinanet_config, training_config, eval_config, nms_config,
augmentation_config and dataset_config. The format of the spec file is a protobuf
text (prototxt) message and each of its fields can be either a basic data type or a nested
message. The top level structure of the spec file is summarized in the table below:
random_seed: 42
retinanet_config {
aspect_ratios_global: "[1.0, 2.0, 0.5]"
scales: "[0.045, 0.09, 0.2, 0.4, 0.55, 0.7]"
two_boxes_for_ar1: false
clip_boxes: false
loss_loc_weight: 0.8
focal_loss_alpha: 0.25
focal_loss_gamma: 2.0
variances: "[0.1, 0.1, 0.2, 0.2]"
arch: "resnet"
nlayers: 18
n_kernels: 1
n_anchor_levels: 1
feature_size: 256
freeze_bn: false
freeze_blocks: 0
}
training_config {
enable_qat: False
batch_size_per_gpu: 24
num_epochs: 100
pretrain_model_path: "YOUR_PRETRAINED_MODEL"
optimizer {
sgd {
momentum: 0.9
nesterov: True
}
}
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 4e-5
max_learning_rate: 1.5e-2
soft_start: 0.15
annealing: 0.5
}
}
regularizer {
type: L1
weight: 2e-5
}
}
eval_config {
validation_period_during_training: 10
average_precision_mode: SAMPLE
batch_size: 24
matching_iou_threshold: 0.5
}
nms_config {
confidence_threshold: 0.01
clustering_iou_threshold: 0.6
top_k: 200
}
augmentation_config {
output_width: 384
output_height: 1248
output_channel: 3
image_mean {
key: 'b'
value: 103.9
}
image_mean {
key: 'g'
value: 116.8
}
image_mean {
key: 'r'
value: 123.7
}
}
dataset_config {
data_sources: {
# option 1
tfrecords_path: "/workspace/tao-experiments/data/tfrecords/kitti_train*"
# option 2
# label_directory_path: "/workspace/tao-experiments/data/training/label_2"
# image_directory_path: "/workspace/tao-experiments/data/training/image_2"
}
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_data_sources: {
label_directory_path: "/workspace/tao-experiments/data/val/label"
image_directory_path: "/workspace/tao-experiments/data/val/image"
}
}
Training Config
The training configuration(training_config) defines the parameters needed for the training,
evaluation and inference. Details are summarized in the table below.
| Field | Description | Data Type and Constraints | Recommended/Typical Value |
| batch_size_per_gpu | The batch size for each GPU, so the effective batch size is batch_size_per_gpu * num_gpus. | Unsigned int, positive | |
| num_epochs | The number of epochs to train the network | Unsigned int, positive. | – |
| enable_qat | Whether to use quantization aware training.
RetinaNet does not support loading a pruned non-QAT model and retraining it with QAT
enabled, or vice versa. To get a pruned QAT model, perform the initial training
with QAT enabled or enable_qat=True. |
Boolean | |
| learning_rate | Only soft_start_annealing_schedule with the following nested parameters is supported:
|
Message type. | – |
| regularizer | This parameter configures the regularizer to be used while training and contains
the following nested parameters.
|
Message type. | L1 (Note: NVIDIA suggests using L1 regularizer when training a network before pruning as L1 regularization helps making the network weights more prunable.) |
| optimizer | This parameter can be either “adam”, “sgd”, or “rmsprop”. Each type has following parameters:
The definition of the above parameters is the same as those in Keras (keras.io/api/optimizers) |
Message type. | – |
| pretrain_model_path | The path to the pretrained model, if any. At most one of pretrain_model_path, resume_model_path, pruned_model_path may present. | String | – |
| resume_model_path | The path to the TAO checkpoint model to resume training, if any. At most one of pretrain_model_path, resume_model_path, pruned_model_path may present. | String | – |
| pruned_model_path | The path to a TAO pruned model for re-training, if any. At most one of pretrain_model_path, resume_model_path, pruned_model_path may present. | String | – |
| checkpoint_interval | The number of training epochs that should run per one model checkpoint/validation | Unsigned int, positive | 10 |
| max_queue_size | The number of prefetch batches in data loading | Unsigned int, positive | – |
| n_workers | The number of workers for data loading (set to less than 4 when using tfrecords as data ingestiion) | Unsigned int, positive | – |
| use_multiprocessing | Whether to use multiprocessing mode of keras sequence data loader | Boolean | – |
| visualizer | The training visualization config | Message type | – |
| early_stopping | The early stopping config | Message type | – |
The learning rate is automatically scaled with the number of GPUs used during training, or the effective learning rate is learning_rate * n_gpu.
Training Visualization Config
Visualization during training is configured with the visualizer parameter, which contains the parameters described
below.
| Parameter | Description | Data Type and Constraints | Recommended/Typical Value |
| enabled | Whether to enable or disable visualization | Boolean | – |
| num_images | The maximum number of images to be visualized in TensorBoard | Integer | 3 |
If visualization is enabled, the tensorboard log will be produced during training including the graphs for learning rate, training loss, validation loss, validation mAP and validation AP of each class. The augmented images with bboxes will also be produced in the tensorboard.
Early Stopping
The parameters for early stopping are described in the table below.
| Parameter | Description | Data Type and Constraints | Recommended/Typical Value |
| monitor | The metric to monitor in order to enable early stopping | String | loss |
| patience | The number of checks of the monitor value before stopping the training |
Integer | |
| min_delta | The delta of the minimum value of the monitor value below which it is classified as not decreasing |
Float |
Evaluation Config
The evaluation configuration (eval_config) defines the parameters needed for the evaluation
either during training or standalone. Details are summarized in the table below.
| Field | Description | Data Type and Constraints | Recommended/Typical Value |
| validation_period_during_training | The number of training epochs per which one validation should run. | Unsigned int, positive | 10 |
| average_precision_mode | Average Precision (AP) calculation mode can be either SAMPLE or INTEGRATE. SAMPLE is used as VOC metrics for VOC 2009 or before. INTEGRATE is used for VOC 2010 or after that. | ENUM type ( SAMPLE or INTEGRATE) | SAMPLE |
| matching_iou_threshold | The lowest IoU of predicted box and ground truth box that can be considered a match. | Boolean | 0.5 |
NMS Config
The NMS configuration (nms_config) defines the parameters needed for the NMS postprocessing.
NMS config applies to the NMS layer of the model in training, validation, evaluation, inference
and export. Details are summarized in the table below.
| Field | Description | Data Type and Constraints | Recommended/Typical Value |
| confidence_threshold | Boxes with a confidence score less than confidence_threshold are discarded before applying NMS. | float | 0.01 |
| cluster_iou_threshold | The IoU threshold below which boxes will go through the NMS process. | float | 0.6 |
| top_k | top_k boxes will be output after the NMS keras layer. If the number of valid boxes is less than k, the returned array will be padded with boxes whose confidence score is 0. | Unsigned int | 200 |
| infer_nms_score_bits | The number of bits to represent the score values in NMS plugin in TensorRT OSS. The valid range is integers in [1, 10]. Setting it to any other values will make it fall back to ordinary NMS. Currently this optimized NMS plugin is only available in FP16 but it should also be selected by INT8 data type as there is no INT8 NMS in TensorRT OSS and hence this fastest implementation in FP16 will be selected. If falling back to ordinary NMS, the actual data type when building the engine will decide the exact precision(FP16 or FP32) to run at. | int. In the interval [1, 10]. | 0 |
Augmentation Config
The augmentation_config parameter defines the image size after preprocessing.
The augmentation methods in the SSD paper will be performed during training, including random flip, zoom-in,
zoom-out and color jittering. And the augmented images will be resized to the output shape defined
in augmentation_config. In evaluation process, only the resize will be performed.
The details of augmentation methods can be found in setcion 2.2 and 3.6 of the paper.
| Field | Description | Data Type and Constraints | Recommended/Typical Value |
| output_channel | Output image channel of augmentation pipeline. | integer | – |
| output_width | The width of preprocessed images and the network input. | integer, multiple of 32 | – |
| output_height | The height of preprocessed images and the network input. | integer, multiple of 32 | – |
| random_crop_min_scale | Minimum patch scale of RandomCrop augmentation. Default:0.3 | float <= 1.0 | – |
| random_crop_max_scale | Maximum patch scale of RandomCrop augmentation. Default:1.0 | float >= 1.0 | – |
| random_crop_min_ar | Minimum aspect ratio of RandomCrop augmentation. Default:0.5 | float > 0 | – |
| random_crop_max_ar | Maximum aspect ratio of RandomCrop augmentation. Default:2.0 | float > 0 | – |
| zoom_out_min_scale | Minimum scale of ZoomOut augmentation. Default:1.0 | float >= 1.0 | – |
| zoom_out_max_scale | Maximum scale of ZoomOut augmentation. Default:4.0 | float >= 1.0 | – |
| brightness | Brightness delta in color jittering augmentation. Default:32 | integer >= 0 | – |
| contrast | Contrast delta factor in color jitter augmentation. Default:0.5 | float of [0, 1) | – |
| saturation | Saturation delta factor in color jitter augmentation. Default:0.5 | float of [0, 1) | – |
| hue | Hue delta in color jittering augmentation. Default:18 | integer >= 0 | – |
| random_flip | Probablity of performing random horizontal flip. Default:0.5 | float of [0, 1) | – |
| image_mean | A key/value pair to specify image mean values. If omitted, ImageNet mean will be used for image preprocessing. If set, depending on output_channel, either ‘r/g/b’ or ‘l’ key/value pair must be configured. | dict | – |
If set random_crop_min_scale = random_crop_max_scale = 1.0, RandomCrop augmentation will be disabled. Similarly, set zoom_out_min_scale = zoom_out_max_scale = 1, ZoomOut augmentation will be disabled. And all color jitter delta values are set to 0, color jittering augmentation will be disabled.
Dataset Config
The RetinaNet dataloader assumes data are prepared in KITTI format (images and labels in two separate folders where each image in image folder has a txt label file with same filename in label folder. The label file content follows KITTI format) and training/validation split is already done.
The parameters in dataset_config are defined as follows:
data_sources: Captures the path to datasets to train on. If you have multiple data sources for training, you may use multipledata_sources. This field contains 3 parameters: *label_directory_path: Path to the data source label folder *image_directory_path: Path to the data source image folder *tfrecords_path: Path to the TFRecordsWhen using raw KTTTI formatted data as input, only
label_directory_pathandimage_directory_pathare required. When using TFRecords as data ingestion, onlytfrecords_pathis required.include_difficult_in_training: Whether to include difficult boxes in training. If set to false, difficult boxes will be ignored. Difficult boxes are those with occlusion level 2 in KITTI labels. (only applicable with raw KITTI formatted data)target_class_mapping: This parameter maps the class names in the labels to the target class to be trained in the network. An element is defined for every source class to target class mapping. This field was included with the intention of grouping similar class objects under one umbrella. For example: car, van, heavy_truck etc. may be grouped under automobile. The “key” field is the value of the class name in the tfrecords file, and the “value” field corresponds to the value that the network is expected to learn.validation_data_sources: Captures the path to datasets to validate on. If you have multiple data sources for validation, you may use multiplevalidation_data_sources. This field contains 2 parameters:label_directory_path: Path to the data source label folderimage_directory_path: Path to the data source image folder
The class names key in the target_class_mapping must be identical to the one shown in the KITTI labels so that the correct classes are picked up for training.
Class Weighting Config
RetinaNet supports class-level weighting on the loss function during training. The following is an example of
the class weighting configuration (class_weighting_config) to set weights for two classes.
class_weighting_config {
class_weighting{
key: "person"
value: 1.0
}
class_weighting{
key: "bus"
value: 5.0
}
}
The parameters in class_weighting_config are defined as follows:
class_weighting: This parameter maps the class name to the corresponding class weight on the loss function. The class weightvalueshould be greater than 0. If a class weight is not explicitly set in the config, a default value of1.0will be assigned implicitly.
RetinaNet Config
The RetinaNet configuration (retinanet_config) defines the parameters needed for
building the RetinaNet model. Details are summarized in the table below.
| Field | Description | Data Type and Constraints | Recommended/Typical Value |
| aspect_ratios_global | Anchor boxes of aspect ratios defined in aspect_ratios_global will be generated for each feature layer used for prediction. Note: Only one of aspect_ratios_global or aspect_ratios is required. | string | “[1.0, 2.0, 0.5]” |
| aspect_ratios | The length of the outer list must be equivalent to the number of feature layers used for anchor box generation. And the i-th layer will have anchor boxes with aspect ratios defined in aspect_ratios[i]. Note: Only one of aspect_ratios_global or aspect_ratios is required. | string | “[[1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0, 2.0, 0.5, 3.0, 0.33]]” |
| two_boxes_for_ar1 | This setting is only relevant for layers that have 1.0 as the aspect ratio. If two_boxes_for_ar1 is true, two boxes will be generated with an aspect ratio of 1. One whose scale is the scale for this layer and the other one whose scale is the geometric mean of the scale for this layer and the scale for the next layer. | Boolean | True |
| clip_boxes | If true, all corner anchor boxes will be truncated so they are fully inside the feature images. | Boolean | False |
| scales | scales is a list of positive floats containing scaling factors per convolutional predictor layer. This list must be one element longer than the number of predictor layers, so if two_boxes_for_ar1 is true, the second aspect ratio 1.0 box for the last layer can have a proper scale. Except for the last element in this list, each positive float is the scaling factor for boxes in that layer. For example, if for one layer the scale is 0.1, then the generated anchor box with aspect ratio 1 for that layer (the first aspect ratio 1 box if two_boxes_for_ar1 is true) will have its height and width as 0.1*min(img_h, img_w). min_scale and max_scale are two positive floats. If both of them appear in the config, the program can automatically generate the scales by evenly splitting the space between min_scale and max_scale. | string | “[0.05, 0.1, 0.25, 0.4, 0.55, 0.7, 0.85]” |
| min_scale/max_scale | If both appear in the config, scales will be generated evenly by splitting the space between min_scale and max_scale. | float | – |
| loss_loc_weight | This is a positive float controlling how much location regression loss should contribute to the final loss. The final loss is calculated as classification_loss + loss_loc_weight * loc_loss | float | 1.0 |
| focal_loss_alpha | Alpha is the focal loss equation. | float | 0.25 |
| focal_loss_gamma | Gamma is the focal loss equation. | float | 2.0 |
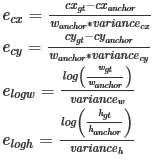
| variances | Variances should be a list of 4 positive floats. The four floats, in order, represent variances for box center x, box center y, log box height, log box width. The box offset for box center (cx, cy) and log box size (height/width) w.r.t. anchor will be divided by their respective variance value. Therefore, larger variances result in less significant differences between two different boxes on encoded offsets. | – | |
| steps | An optional list inside quotation marks whose length is the number of feature layers for prediction. The elements should be floats or tuples/lists of two floats. Steps define how many pixels apart the anchor box center points should be. If the element is a float, both vertical and horizontal margin is the same. Otherwise, the first value is step_vertical and the second value is step_horizontal. If steps are not provided, anchor boxes will be distributed uniformly inside the image. | string | – |
| offsets | An optional list of floats inside quotation marks whose length is the number of feature layers for prediction. The first anchor box will have offsets[i]*steps[i] pixels margin from the left and top borders. If offsets are not provided, 0.5 will be used as default value. | string | – |
| arch | Backbone for feature extraction. Currently, “resnet”, “vgg”, “darknet”, “googlenet”, “mobilenet_v1”, “mobilenet_v2” and “squeezenet”, “efficientnet_b0” are supported. | string | resnet |
| nlayers | Number of conv layers in specific arch. For “resnet”, 10, 18, 34, 50 and 101 are supported. For “vgg”, 16 and 19 are supported. For “darknet”, 19 and 53 are supported. All other networks don’t have this configuration and users should just delete this config from the config file. | Unsigned int | – |
| freeze_bn | Whether to freeze all batch normalization layers during training. | boolean | False |
| freeze_blocks | The list of block IDs to be frozen in the model during training. You can choose to freeze some of the CNN blocks in the model to make the training more stable and/or easier to converge. The definition of a block is heuristic for a specific architecture. For example, by stride or by logical blocks in the model, etc. However, the block ID numbers identify the blocks in the model in a sequential order so you don’t have to know the exact locations of the blocks when you do training. A general principle to keep in mind is: the smaller the block ID, the closer it is to the model input; the larger the block ID, the closer it is to the model output. | list(repeated integers)
|
– |
| n_kernels | This setting controls the number of convolutional layers in the RetinaNet subnets for classification and anchor box regression. A larger value generates a larger network and usually means the network is harder to train. | Unsigned int | 2 |
| feature_size | This setting controls the number of channels of the convolutional layers in the RetinaNet subnets for classification and anchor box regression. A larger value gives a larger network and usually means the network is harder to train. Note that RetinaNet FPN generates 5 feature maps, thus the scales field requires a list of 6 scaling factors. The last number is not used if two_boxes_for_ar1 is set to False. There are also three underlying scaling factors at each feature map level (2^0, 2^⅓, 2^⅔ ). | Unsigned int | 256 |
| n_anchor_levels | Number of anchor levels between two adjacent scales. | Unsigned int | 1 |
Focal loss is calculated as follows:

Variances:
Train the RetinaNet model using this command:
tao model retinanet train [-h] -e <experiment_spec>
-r <output_dir>
-k <key>
[--gpus <num_gpus>]
[--gpu_index <gpu_index>]
[--use_amp]
[--log_file <log_file_path>]
Required Arguments
-r, --results_dir: Path to the folder where the experiment output is written.-k, --key: Provide the encryption key to decrypt the model.-e, --experiment_spec_file: Experiment specification file to set up the evaluation experiment. This should be the same as the training specification file.
Optional Arguments
--gpus: The number of GPUs to be used in the training in a multi-GPU scenario (default: 1).--gpu_index: The GPU indices used to run the training. We can specify the GPU indices used to run training when the machine has multiple GPUs installed.--use_amp: A flag to enable AMP training.--log_file: Path to the log file. Defaults to stdout.-h, --help: Show this help message and exit.
Input Requirement
Input size: C * W * H (where C = 1 or 3, W >= 128, H >= 128, W, H are multiples of 32)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
Sample Usage
Here’s an example of using the train command on a RetinaNet model:
tao model retinanet train --gpus 2 -e /path/to/spec.txt -r /path/to/result -k $KEY
To run evaluation for a RetinaNet model use this command:
tao model retinanet evaluate [-h] -e <experiment_spec_file>
-m <model_file>
-k <key>
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments
-e, --experiment_spec_file: Experiment spec file to set up the evaluation experiment. This should be the same as the training specification file.-m, --model: Path to the model file to use for evaluation (supports both the TAO model and TensorRT engine).-k, --key: Provide the key to load the TAO model (it’s not needed if a TensorRT engine is used).
Optional Arguments
--gpu_index: The GPU index used to run the evaluation. We can specify the GPU index used to run evaluation when the machine has multiple GPUs installed. Note that evaluation can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.-h, --help: Show this help message and exit.
Sample Usage
Here’s an example of using the evaluate command on a RetinaNet model:
tao model retinanet evaluate -e /path/to/spec.txt -m /path/to/model.tlt -k $KEY
The inference tool for RetinaNet networks can be used to visualize bboxes, or generate frame by frame KITTI format labels on a directory of images. Two modes are supported, namely TAO model model and TensorRT engine mode. You can execute the TAO model mode using the following command:
tao model retinanet inference [-h] -i <input directory>
-o <output annotated image directory>
-e <experiment spec file>
-m <model file>
-k <key>
[-l <output label directory>]
[-t <visualization threshold>]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments
-m, --model: Path to the pretrained model (supports both the TAO model and TensorRT engine).-i, --in_image_dir: The directory of input images for inference.-o, --out_image_dir: The directory path to output annotated images.-k, --key: Key to load a TAO model (it’s not needed if a TensorRT engine is used).-e, --config_path: Path to an experiment spec file for training.
Optional Arguments
-t, --threshold: Threshold for drawing a bbox. default: 0.3-l, --out_label_dir: The directory to output KITTI labels.--gpu_index: The GPU index to run inference on. We can specify the GPU index used to run inference if the machine has multiple GPUs installed. Note that inference can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.-h, --help: Show this help message and exit
Sample Usage
Here’s an example of using the inference command on a RetinaNet model:
tao model retinanet inference -e /path/to/spec.txt -m /path/to/model.tlt -k $KEY
-o /path/to/output_dir -i /path/to/input_dir
Pruning removes parameters from the model to reduce the model size without compromising the
integrity of the model itself using the tao model retinanet prune command.
The tao model retinanet prune command includes these parameters:
tao model retinanet prune [-h] -m <retinanet model>
-o <output_file>
-k <key>
[-n <normalizer>]
[-eq <equalization_criterion>]
[-pg <pruning_granularity>]
[-pth <pruning threshold>]
[-nf <min_num_filters>]
[-el [<excluded_list>]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments
-m, --model: Path to a pretrained RetinaNet model.-o, --output_file: Path to output checkpoints.-k, --key: Key to load a :code`.tlt` model.
Optional Arguments
-n, –normalizer:maxto normalize by dividing each norm by the maximum norm within a layer;L2to normalize by dividing by the L2 norm of the vector comprising all kernel norms. (default: max)-eq, --equalization_criterion: Criteria to equalize the stats of inputs to an element wise op layer, or depth-wise convolutional layer. This parameter is useful for resnets and mobilenets. Options arearithmetic_mean,geometric_mean,union, andintersection. (default:union)-pg, -pruning_granularity: Number of filters to remove at a time. (default:8)-pth: Threshold to compare normalized norm against. (default:0.1)NoteNVIDIA recommends changing the threshold to keep the number of parameters in the model to within 10-20% of the original unpruned model.
-nf, --min_num_filters: Minimum number of filters to keep per layer (default:16)-el, --excluded_layers: List of excluded_layers. Examples: -i item1 item2 (default: [])--gpu_index: The GPU index to run pruning on. We can specify the GPU index used to run pruning if the machine has multiple GPUs installed. Note that pruning can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.-h, --help: Show this help message and exit.
After pruning, the model needs to be retrained. See Re-training the Pruned Model for more details.
Using the Prune Command
Here’s an example of using the tao model retinanet prune command:
tao model retinanet prune -m /workspace/output/weights/resnet_003.tlt \
-o /workspace/output/weights/resnet_003_pruned.tlt \
-eq union \
-pth 0.7 -k $KEY
Once the model has been pruned, there might be a slight decrease in accuracy. This happens
because some previously useful weights may have been removed. In order to regain the accuracy,
NVIDIA recommends that you retrain this pruned model over the same dataset. To do this, use
the tao model retinanet train command as documented in Training the model,
with an updated spec file that points to the newly pruned model as the pretrained model file.
Users are advised to turn off the regularizer in the training_config for RetinaNet to recover
the accuracy when retraining a pruned model. You may do this by setting the regularizer type
to NO_REG as mentioned Training config. All the other parameters may be retained in
the spec file from the previous training.
RetinaNet does not support loading a pruned non-QAT model and retraining it with QAT
enabled, or vice versa. For example, to get a pruned QAT model, perform the initial training with
QAT enabled or enable_qat=True.
Exporting the model decouples the training process from inference and allows conversion to
TensorRT engines outside the TAO environment. TensorRT engines are specific to each hardware
configuration and should be generated for each unique inference environment.
The exported model may be used universally across training and deployment hardware.
The exported model format is referred to as .etlt. Like .tlt, the .etlt model
format is also a encrypted model format with the same key of the .tlt model that it is
exported from. This key is required when deploying this model.
INT8 Mode Overview
TensorRT engines can be generated in INT8 mode to improve performance, but require a calibration
cache at engine creation-time. The calibration cache is generated using a calibration tensor
file, if tao model retinanet export is run with the --data_type flag set to int8.
Pre-generating the calibration information and caching it removes the need for calibrating the
model on the inference machine. Moving the calibration cache is usually much more convenient than
moving the calibration tensorfile, since it is a much smaller file and can be moved with the
exported model. Using the calibration cache also speeds up engine creation as building the
cache can take several minutes to generate depending on the size of the Tensorfile and the model
itself.
The export tool can generate INT8 calibration cache by ingesting training data using either of these options:
Option 1: Using the training data loader to load the training images for INT8 calibration. This option is now the recommended approach to support multiple image directories by leveraging the training dataset loader. This also ensures two important aspects of data during calibration:
Data pre-processing in the INT8 calibration step is the same as in the training process.
The data batches are sampled randomly across the entire training dataset, thereby improving the accuracy of the INT8 model.
Option 2: Pointing the tool to a directory of images that you want to use to calibrate the model. For this option, make sure to create a sub-sampled directory of random images that best represent your training dataset.
FP16/FP32 Model
The calibration.bin is only required if you need to run inference at INT8 precision. For
FP16/FP32 based inference, the export step is much simpler. All that is required is to provide
a .tlt model from the training/retraining step to be converted into an .etlt.
Exporting the RetinaNet Model
Here’s an example of the command line arguments of the tao model retinanet export command:
tao model retinanet export [-h] -m <path to the .tlt model file>
--experiment_spec <path to experiment spec file>
-k <key>
[-o <path to output file>]
[--cal_data_file <path to tensor file>]
[--cal_image_dir <path to the directory images to calibrate the model]
[--cal_cache_file <path to output calibration file>]
[--data_type <Data type for the TensorRT backend during export>]
[--batches <Number of batches to calibrate over>]
[--max_batch_size <maximum trt batch size>]
[--max_workspace_size <maximum workspace size]
[--batch_size <batch size to TensorRT engine>]
[--engine_file <path to the TensorRT engine file>]
[--gen_ds_config]
[--strict_type_constraints]
[--force_ptq]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
[--verbose]
Required Arguments
-m, --model: Path to the .tlt model file to be exported.-k, --key: Key used to save the.tltmodel file.-e, --experiment_spec: Path to the spec file.
Optional Arguments
-o, --output_file: Path to save the exported model to. The default is./<input_file>.etlt.--gen_ds_config: A Boolean flag indicating whether to generate the template DeepStream related configuration (“nvinfer_config.txt”) as well as a label file (“labels.txt”) in the same directory as theoutput_file. Note that the config file is NOT a complete configuration file and requires the user to update the sample config files in DeepStream with the parameters generated.--gpu_index: The index of (discrete) GPUs used for exporting the model. We can specify the GPU index to run export if the machine has multiple GPUs installed. Note that export can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.-h, --help: Show this help message and exit.
QAT Export Mode Required Arguments
--cal_json_file: The path to the json file containing tensor scale for QAT models. This argument is required if engine for QAT model is being generated.
When exporting a model trained with QAT enabled, the tensor scale factors to calibrate
the activations are peeled out of the model and serialized to a JSON file defined by the
cal_json_file argument.
Sample usage
Here’s a sample command to export a RetinaNet model.
tao model retinanet export -m /ws/retinanet_resnet18_epoch_100.tlt \
-o /ws/retinanet_resnet18_epoch_100_int8.etlt \
-e /ws/retinanet_retrain_resnet18_kitti.txt \
-k $KEY
For TensorRT engine generation, validation, and int8 calibration, please refer to the TAO Deploy documentation.
Refer to the Integrating a RetinaNet Model page for more information about deploying a RetinaNet model to DeepStream.