Overview
NVIDIA TAO Toolkit is a low-code AI toolkit built on TensorFlow and PyTorch, which simplifies and accelerates the model training process by abstracting away the complexity of AI models and the deep learning framework. With TAO, users can select one of 100+ pre-trained vision AI models from NGC and fine-tune and customize on their own dataset without writing a single line of code. The output of TAO is a trained model in ONNX format that can be deployed on any platform that supports ONNX.
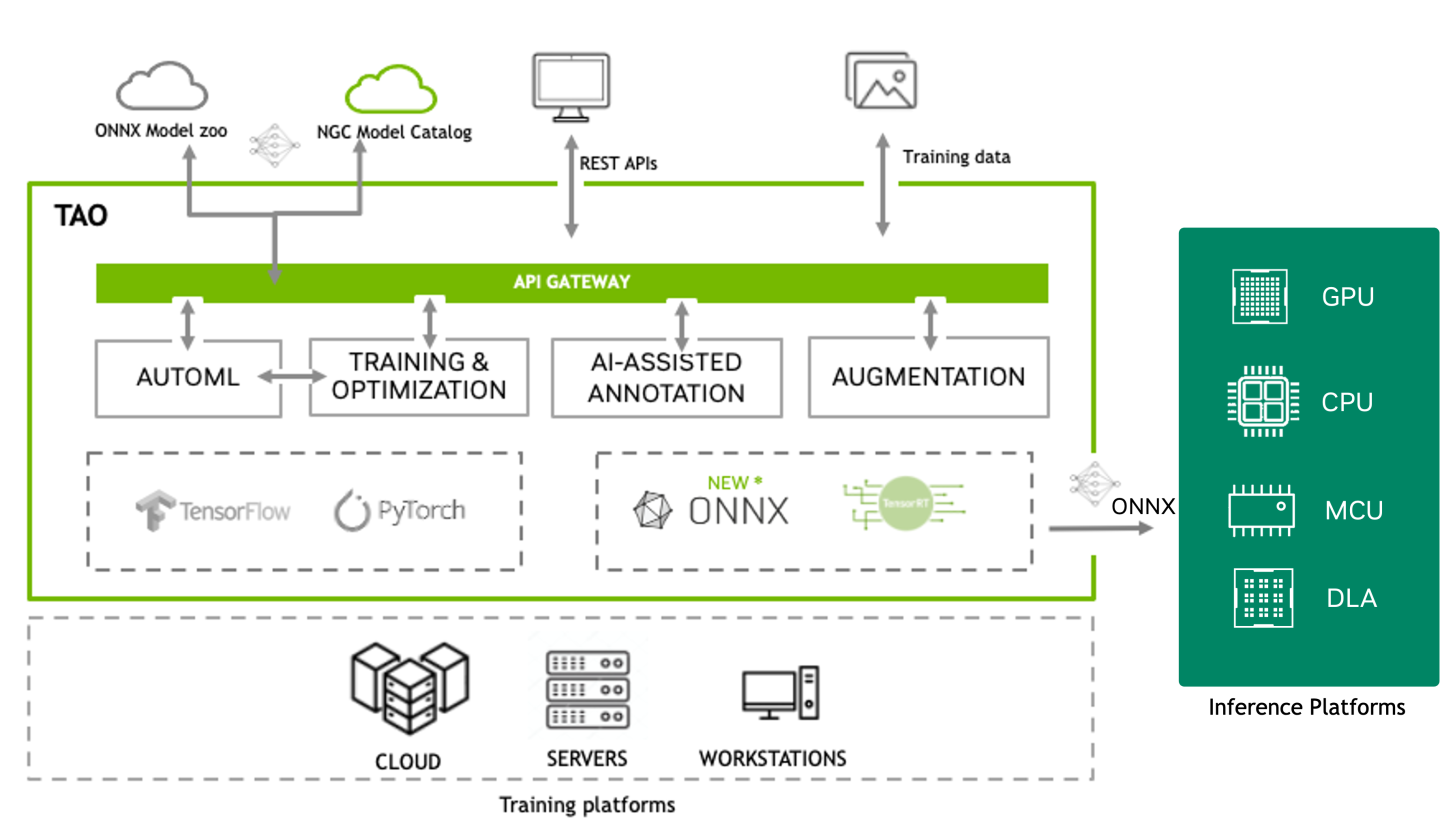
TAO Overview Image
TAO supports most of the popular CV tasks such as:
Image Classification
Object Detection
Instance Segmentation
Semantic Segmentation
Optical character detection & recognition (OCD/OCR)
Body Pose Estimation
Key point estimation
Action Recognition
Siamese network
Change Detection
CenterPose
For image classification, object detection and segmentation, users can choose one of the many feature extractors and use it with one of many heads for classification, detection and segmentation tasks, opening a possibility of 100+ model combinations. TAO supports some of the leading Vision Transformers (ViT) like FAN, GC-ViT, DINO, D-DETR and SegFormer.
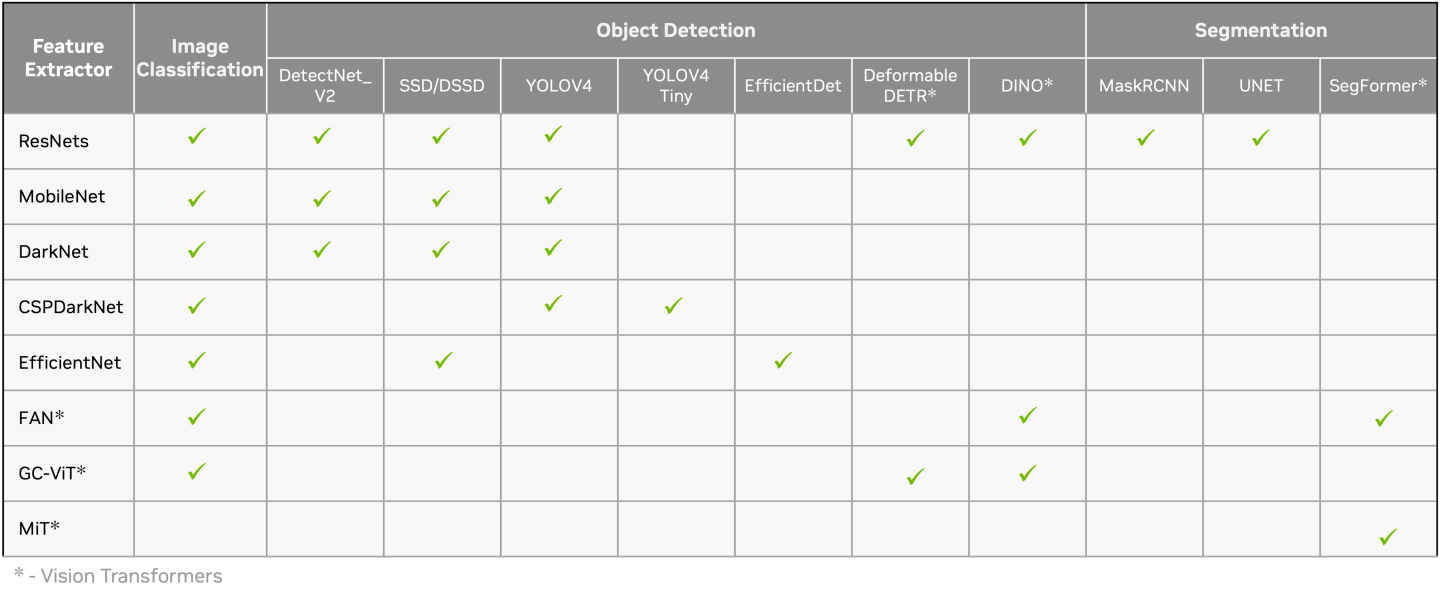
Model Matrix
TAO Toolkit provides means to enhance a user’s dataset. These class of features and tasks are included under the Data Services modality.
TAO Toolkit 5.2.0 introduces finetuning and inference support for Open Vocabulary Image Segmentation through a new and optimized version of the ODISE model released earlier by NVLABs as a Developer Preview feature. For more information about the model, refer to the TAO Toolkit PyTorch backend GitHub repository. NVIDIA also includes a gradio app to try out zero-shot inference of Open Vocabulary segmentation. Instructions to launch the gradio demo app are captured in this section of the GitHub repository.
As of version 5.2.0, the TAO Toolkit containers run only on x86 platforms with discrete GPUs. For more information about the supported GPUs, refer to the Quick Start Guide.
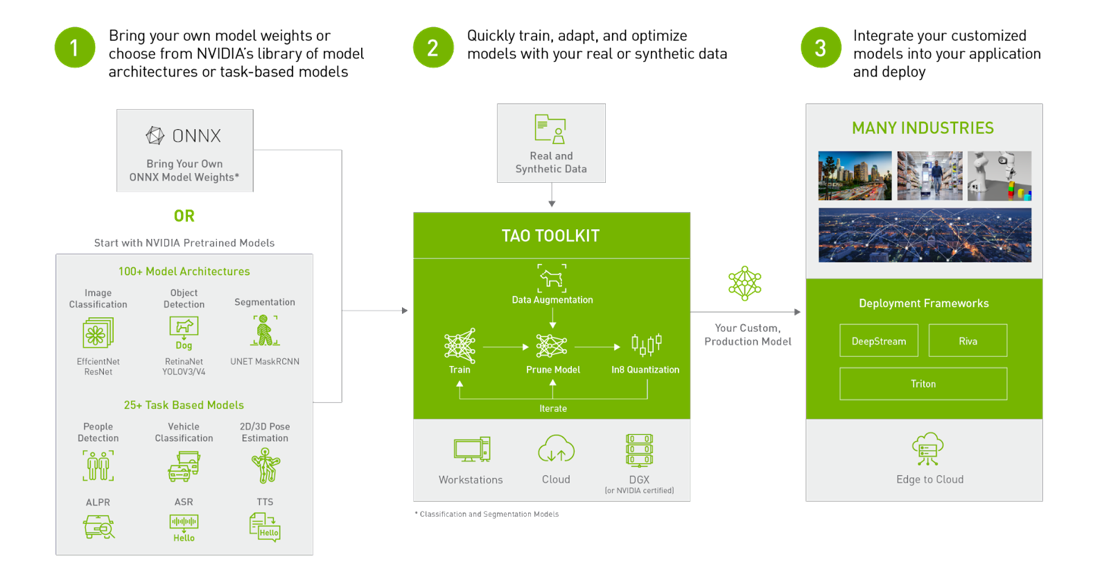
TAO has an extensive selection of pre-trained models either trained on public datasets like ImageNet, COCO, OpenImages or on proprietary datasets for task specific use cases like People detection, vehicle detection and action recognition and more. The task specific models can be used directly for inference but can also be fine-tuned on custom datasets for better accuracy.
Go to Model Zoo section to learn more about all the pre-trained models.
TAO packages several key features to help developers accelerate their AI training and optimization. Here are few of the key features:
Computer vision worflows
Model Pruning - Reduce the number of parameters in a model to reduce model size and improve accuracy
ONNX export - Supports model output in industry standard ONNX format which can then be used directly with any platforms
Quantization Aware Training - Emulates lower precision quantization during training to reduce accuracy loss from training to lower precision inference
Multi-GPU - Accelerate training by parallelizing training jobs across multiple GPUs on a single node
Multi-Node - Accelerate training by parallelizing training jobs across multiple nodes
Training Visualization - Visualize training graphs and metrics in Tensorboard or in 3rd party services
Data Services
Data Augmentation - Offline and online augmentation to add data diversity to your dataset which can then generalize the model
AI-assisted annotation - Class agnostic auto-labeler to generate segmentation masks provided the bounding box.
Data Analytics - Analyzes object-detection annotation files and image files, calculates insights, and generate graphs and a summary.
TAO also provides several features for service providers and NVIDIA partners looking to integrate TAO with their workflow to provide added services.
AutoML - Automatic hyperparameter sweeps and optimization to generate best accuracy on a given dataset.
REST APIs - Use cloud API endpoints to call into your managed TAO services in the cloud.
Kubernetes deployment - Deploy TAO services in K8s cluster either on-prem or with one of cloud managed Kubernetes services.
Source code availability - Access source code for TAO to add your own customization
The detail getting started is provided in TAO getting started guide.
The getting started package contains install scripts, Jupyter notebooks and model configuration files for training and optimization. There are Jupyter notebooks for all the models that can be used as templates to run your training. All notebooks comes with a call to download sample dataset to run training jobs. These can be replaced with your own datasets.
TAO Toolkit is a Python package hosted on the NVIDIA Python Package Index. It interacts with lower-level TAO dockers available from the NVIDIA GPU Accelerated Container Registry (NGC); TAO containers come pre-installed with all dependencies required for training. The CLI is run from Jupyter notebooks packaged inside each docker container and consists of a few simple commands, such as train, evaluate, infer, prune, export, and augment (i.e. data augmentation). The output of the TAO workflow is a trained model that can be deployed for inference on NVIDIA devices using DeepStream and TensorRT
The TAO application layer is built on top of CUDA-X, which contains all the lower-level NVIDIA libraries, including NVIDIA Container Runtime for GPU acceleration, CUDA and cuDNN for deep learning (DL) operations, and TensorRT (the NVIDIA inference optimization and runtime engine) for optimizing models. Models that are generated with TAO Toolkit are completely compatible with and accelerated for TensorRT, which ensures maximum inference performance without any extra effort.
Model pruning is one of the key differentiators for TAO Toolkit. Pruning involves removing from the neural network nodes that contribute less to the overall accuracy of the model, reducing the overall size of the model, significantly reducing the memory footprint, and increasing inference throughput–all factors that are very important for edge deployment.
Currently, pruning is supported on most CV models, but not on Conversational AI models. The following graph provides an example of performance gains achieved when going from an unpruned CV model to a pruned CV model (inference was run on an NVIDIA T4; TrafficCamNet, DashCamNet, and PeopleNet are three of the custom pre-trained models that are available on NGC).
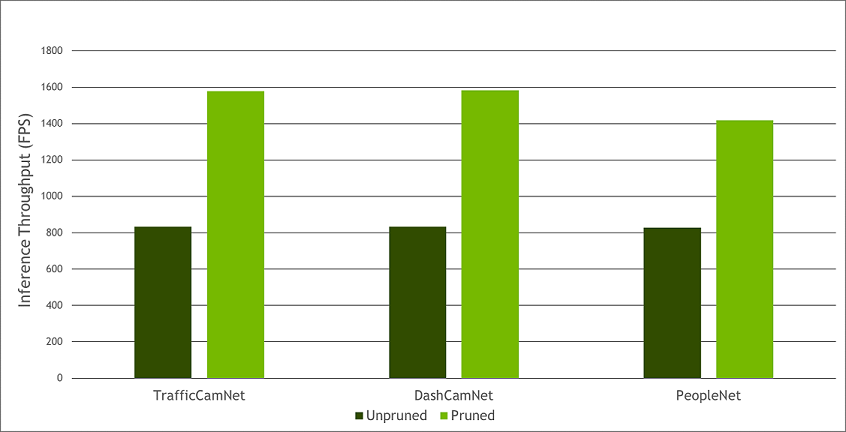
Pruned vs Unpruned Performance
Tutorial Videos
Developer blogs
To learn more about using TAO Toolkit, read the technical blogs, which provide a step-by-step guide to training with TAO:
Learn about the latest features in TAO Toolkit 5.0
Learn how to train like a pro using TAO AutoML
Learn how to train with PeopleNet and other pre-trained models using TAO Toolkit.
Learn how to create custom AI models with TAO on AzureML
Learn how to improve INT8 accuracy using quantization aware training (QAT) with TAO Toolkit.
Learn how to create a real time license plate detection and recognition app
Learn how to prepare state of the art models for classification and object detection with TAO Toolkit
Learn how to train and optimize a 2D body-pose estimation model with TAO: 2D Pose Estimation Part 1 | 2D Pose Estimation Part 2.
Read about the different use cases with this Whitepaper
Webinars
If you have any questions when using TAO Toolkit to train a model and deploy to Riva or DeepStream, post them here: