Facial Landmarks Estimation
The FPENet model described in this card is a facial keypoints estimator network, which aims to predict the (x,y) location of keypoints for a given input face image.
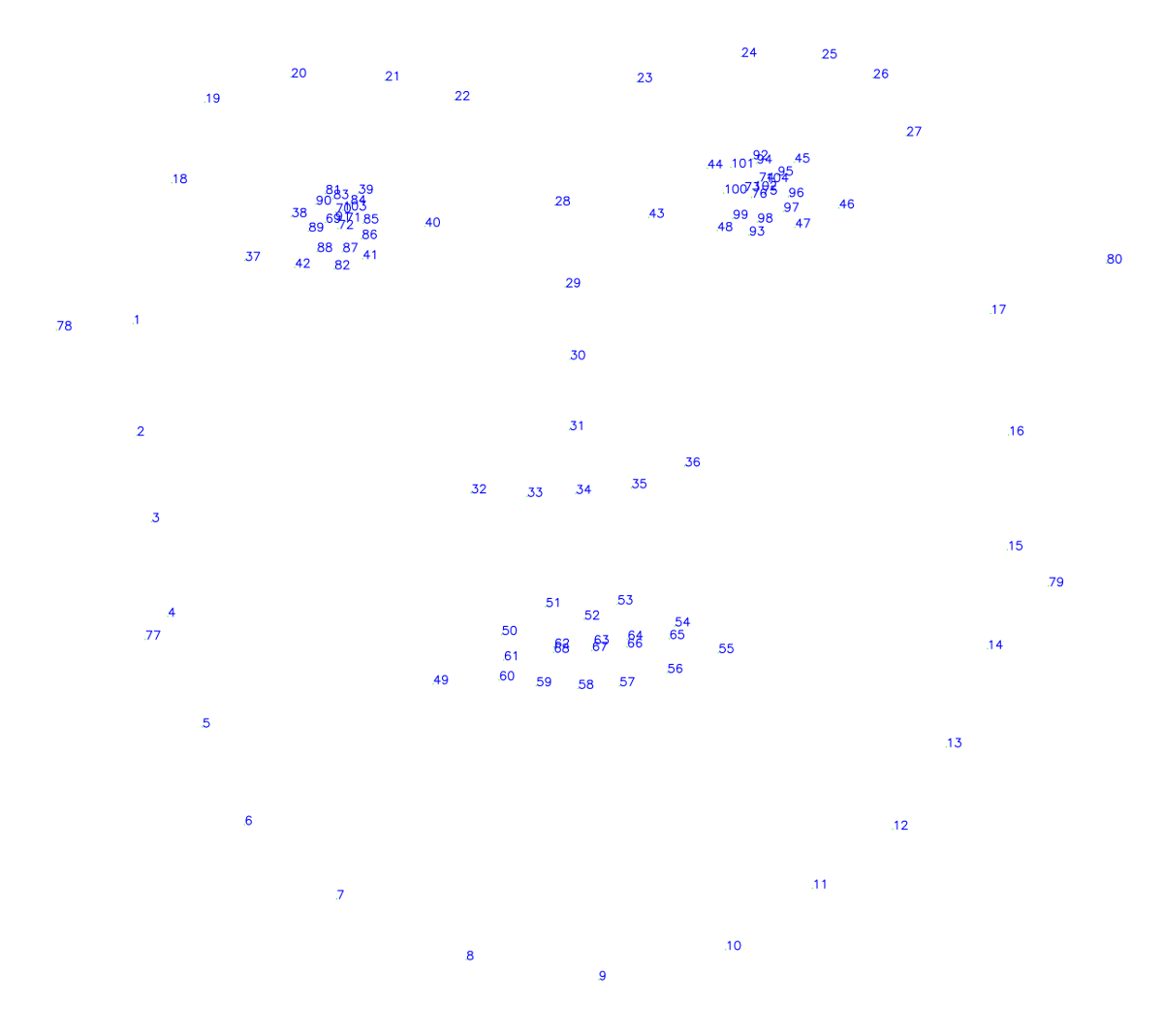
This model predicts 68, 80, or 104 keypoints for a given face:
Chin: 1-17
Eyebrows: 18-27
Nose: 28-36
Eyes: 37-48
Mouth: 49-61
Inner Lips: 62-68
Pupil: 69-76
Ears: 77-80
Additional eye landmarks: 81-104
It can also handle visible or occluded flags for each keypoint. An example of the keypoints is shown below:
This is a classification model with a recombinator network backbone. Recombinator networks are a family of CNN architectures that are suited for fine-grained pixel-level predictions (as opposed to image-level prediction like classification). The model recombines the layer inputs such that convolutional layers in the finer branches get inputs from both coarse and fine layers.
The training algorithm optimizes the network to minimize the manhattan distance (L1), squared euclidean (L2) or the Wing Loss over the keypoints. Individual face regions can be weighted based on the ‘eyes’, the ‘mouth’, the ‘pupil’ and the rest of the ‘face’. This model was trained using the Facial Landmarks Estimation training app in TAO Toolkit v3.0.
Honari, S., Yosinski, J., Vincent, P., & Pal, C. (2016). Recombinator networks: Learning coarse-to-fine feature aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 5743-5752).
Honari, S., Molchanov, P., Tyree, S., Vincent, P., Pal, C., & Kautz, J. (2018). Improving landmark localization with semi-supervised learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1546-1555).
Feng, Z. H., Kittler, J., Awais, M., Huber, P., & Wu, X. J. (2018). Wing loss for robust facial landmark localisation with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2235-2245).
FPEnet is generally used in conjunction with a face detector, and the output is commonly used for face alignment, head pose estimation, emotion detection, eye-blink detection, gaze estimation, etc.
Input
Images of 80 X 80 X 1
Output
N X 2 keypoint locations
N X 1 keypoint confidence
N is the number of keypoints. It can have a value of 68, 80, or 104.
The datasheet for the model is captured in its model card hosted on NGC.