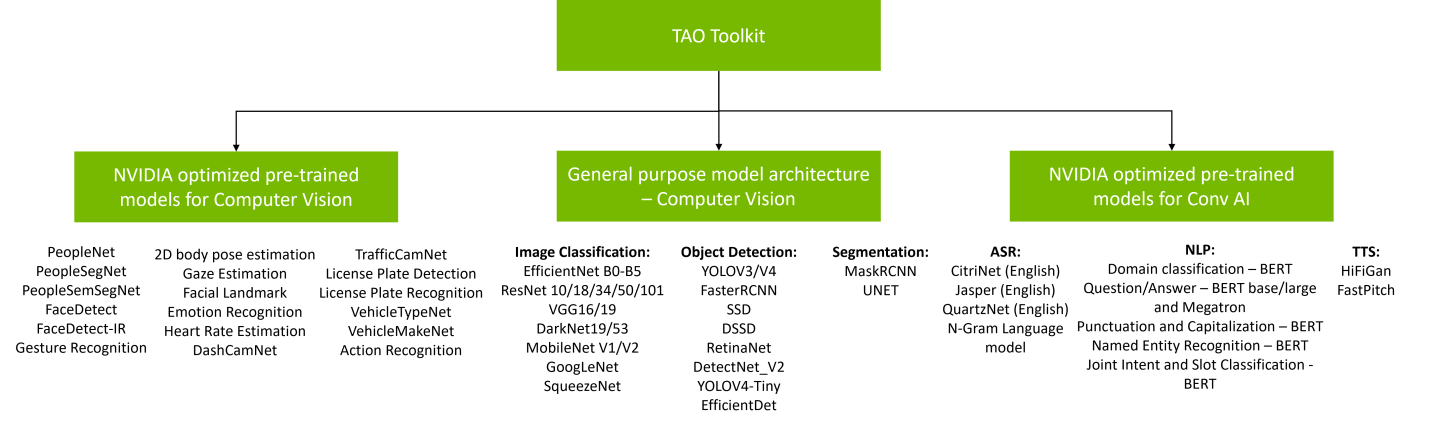
Overview
TAO Toolkit provides an extensive model zoo containing pretrained models for computer vision use cases.
There are two types of pre-trained models that you can start with:
General-purpose vision models: The pre-trained weights for these models merely act as a starting point to build more complex models. For computer vision use cases, these pre-trained weights are trained on Open Image datasets, and they provide a much better starting point for training versus starting from a random initialization of weights.
Purpose-built pre-trained models: These are highly accurate models that are trained on thousands of data inputs for a specific task. These domain-focused models can either be used directly for inference or can be used with TAO Toolkit for transfer learning on your own dataset.
* New in TAO Toolkit 3.0-21.08 GA
You can choose from 100+ permutations of model architecture and backbone with the general purpose vision models.
Purpose-built models
Purpose-built models are built for high accuracy and performance. You can deploy these models out of the box for applications such as smart city, retail, public safety, and healthcare, or you can retrain them with your own data. All models are trained on thousands of proprietary images and achieve very high accuracy on NVIDIA test data. More information about each of these models is available in ndividual model cards. Typical use cases and some model KPIs are provided in the table below. PeopleNet can be used for detecting and counting people in smart buildings, retail, hospitals, etc. For smart traffic applications, TrafficCamNet and DashCamNet can be used to detect and track vehicles on the road.
Model Name |
Network Architecture |
Number of classes |
Accuracy |
Use Case |
|---|---|---|---|---|
| TrafficCamNet | DetectNet_v2-ResNet18 | 4 | 84% mAP | Detect and track cars. |
| PeopleNet | DetectNet_v2-ResNet18/34 | 3 | 84% mAP | People counting, heatmap generation, social distancing. |
| DashCamNet | DetectNet_v2-ResNet18 | 4 | 80% mAP | Identify objects from a moving object. |
| FaceDetectIR | DetectNet_v2-ResNet18 | 1 | 96% mAP | Detect face in a dark environment with IR camera. |
| VehicleMakeNet | ResNet18 | 20 | 91% mAP | Classifying car models. |
| VehicleTypeNet | ResNet18 | 6 | 96% mAP | Classifying type of cars as coupe, sedan, truck, etc. |
| PeopleSegNet | MaskRCNN-ResNet50 | 1 | 85% mAP | Creates segmentation masks around people, provides pixel |
| PeopleSemSegNet | Vanilla Unet Dynamic | 2 | 92% mIOU | Creates semantic segmentation masks for people. |
| PeopleSemSegNet | Shuffle Unet | 2 | 87% mIOU | Creates semantic segmentation masks for people. |
| License Plate Detection | DetectNet_v2-ResNet18 | 1 | 98% mAP | Detecting and localizing License plates on vehicles |
| License Plate Recognition | Tuned ResNet18 | 36(US) / 68(CH) | 97%(US)/99%(CH) | Recognize License plates numbers |
| Gaze Estimation | Four branch AlexNet based model | NA | 6.5 RMSE | Detects person’s eye gaze |
| Facial Landmark | Recombinator networks | NA | 6.1 pixel error | Estimates key points on person’s face |
| Heart Rate Estimation | Two branch model with attention | NA | 0.7 BPM | Estimates person’s heartrate from RGB video |
| Gesture Recognition | ResNet18 | 6 | 0.85 F1 score | Recognize hand gestures |
| Emotion Recognition | 5 Fully Connected Layers | 6 | 0.91 F1 score | Recognize facial Emotion |
| FaceDetect | DetectNet_v2-ResNet18 | 1 | 85.3 mAP | Detect faces from RGB or grayscale image |
| BodyPoseNet | Single shot bottom-up | 18 | 56.1% mAP* | Estimates body key points for persons in the image |
| PoseClassificationNet | ST-Graph Convolutional Network | 6 | 89.53% | Classify poses of people from their skeletons |
| PointPillarNet | PointPillars | 65.22 mAP | Detect objects from Lidar point cloud | |
| CitySemSegFormer | Segformer | 19 | 70% mIOU | Creates semantic segmentation masks for the classes in Cityscapes Dataset |
| PeopleNet Transformer | Deformable DETR | 1 | 82% mAP | People counting, heatmap generation, social distancing. |
| ReIdentificationNet | ResNet50 | 64-d, 128-d | 93.9% mAP | People re-identification |
| RetailObjectDetection | EfficientDet | 100-class | 77.9% mAP | Detecting objects on a retail checkout. |
| RetailObjectDetection | EfficientDet | binary | 95.9% mAP | Detecting objects on a retail checkout. |
| RetailObjectRecognition | ResNet-101 | 83.66% mAP | Object recognition in a retail checkout. | |
| Optical Inspection | custom | binary | 97.4%/0.1%(FPR) | Classifying defect between test and golden images. |
| Visual ChangeNet Classification | Visual ChangeNet-FAN | binary | 97.4%/0.3%(FPR) | Classifying defect between test and golden images. |
| Visual ChangeNet Segmentation | Visual ChangeNet(Segment)-FAN | binary | 99.17% | Defect/Change segmentation between test and golden images. |
The accuracy reported for BodyPoseNet is based on a model trained using the COCO dataset. To reproduce the same accuracy, use the sample notebook.
Performance Metrics
The performance of these pretrained models across various NVIDIA platforms is summarized in the table below. The numbers in the table are the inference performance measured using the trtexec tool in TensorRT samples.
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
DLA1 + DLA2 BS |
DLA1 + DLA2 FPS |
||||
|---|---|---|---|---|---|---|---|---|---|---|
| PeopleNet-ResNet18 | 960x544x3 | INT8 | 8 | 218 | 8 | 128 | ||||
| PeopleNet-ResNet34 (v2.3) | 960x544x3 | INT8 | 8 | 169 | 8 | 94 | ||||
| PeopleNet-ResNet34 (v2.5 unpruned) | 960x544x3 | INT8 | 8 | 79 | 8 | 46 | ||||
| TrafficCamNet | 960x544x3 | INT8 | 8 | 251 | 8 | 174 | ||||
| DashCamNet | 960x544x3 | INT8 | 16 | 251 | 32 | 172 | ||||
| FaceDetect-IR | 384x240x3 | INT8 | 32 | 1407 | 32 | 974 | ||||
| VehilceMakeNet | 224x224x3 | INT8 | 32 | 2434 | 32 | 1166 | ||||
| VehicleTypeNet | 224x224x3 | INT8 | 32 | 1781 | 32 | 1064 | ||||
| FaceDetect (pruned) | 736x416x3 | INT8 | 16 | 395 | 16 | 268 | ||||
| License Plate Detection | 640x480x3 | INT8 | 16 | 784 | 16 | 388 | ||||
| License Plate Recognition | 96x48x3 | FP16 | 16 | 706 | – | – | ||||
| Facial landmark | 80x80x1 | FP16 | 16 | 1105 | – | – | ||||
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 32 | 812 | – | – | ||||
| GestureNet | 160x160x3 | FP16 | 32 | 2585 | – | – | ||||
| BodyPose | 288x384x3 | INT8 | 4 | 104 | – | – | ||||
| Action Recognition 2D RGB | 224x224x96 | FP16 | 16 | 245 | – | – | ||||
| Action Recognition 3D RGB | 224x224x32x3 | FP16 | 4 | 21 | – | – | ||||
| Action Recognition 2D OF | 224x224x96 | FP16 | 16 | 317 | – | – | ||||
| Action Recognition 3D OF | 224x224x32x3 | FP16 | 8 | 25 | – | – | ||||
| Point Pillar | FP16 | 1 | 25 | – | – | |||||
| Pose classification | FP16 | 8 | 87 | – | – | |||||
| 3D Pose - Accuracy | FP16 | 16 | 117 | – | – | |||||
| 3D Pose - Performance | FP16 | 16 | 147 | – | – | |||||
| PeopleSemSegNet_v2 - Shuffle | 960x544x3 | FP16 | 16 | 199 | – | – | ||||
| PeopleSemSegNet_v2 - Vanilla | 960x544x3 | FP16 | 4 | 15 | – | – | ||||
| PeopleNet Transformer | 960x544x3 | FP16 | 2 | 9 | – | – | ||||
| ReidentificationNet | 3x256x18 | FP16 | 32 | 502 | – | – | ||||
| RetailObjectDetection-100 class | 416x416x3 | FP16 | 8 | 29 | – | – | ||||
| RetailObjectDetection-binary | 416x416x3 | FP16 | 8 | 27 | – | – | ||||
| RetailObjectEmbedding | 3x224x224 | FP16 | 32 | 259 | – | – | ||||
| CitySemSegFormer | FP16 | 1 | 0.4 | – | – |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
DLA1 + DLA2 BS |
DLA1 + DLA2 FPS |
|---|---|---|---|---|---|---|---|
| PeopleNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 16 | 390 | 16 | 164 |
| PeopleNet (v2.3) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 16 | 296 | 16 | 122 |
| PeopleNet (v2.5 unpruned) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 8 | 136 | 4 | 58 |
| TrafficCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 16 | 458 | 16 | 220 |
| DashCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 16 | 442 | 16 | 228 |
| FaceDetect-IR | DetectNet_v2 - ResNet18 | 384x240x3 | INT8 | 64 | 2575 | 64 | 1266 |
| VehilceMakeNet | ResNet18 | 224x224x3 | INT8 | 64 | 4342 | 64 | 1508 |
| VehicleTypeNet | ResNet18 | 224x224x3 | INT8 | 64 | 3281 | 64 | 1412 |
| FaceDetect (pruned) | DetectNet_v2 - ResNet18 | 736x416x3 | INT8 | 32 | 719 | 32 | 354 |
| License Plate Detection v1.0 | DetectNet_v2 - ResNet18 | 640x480x3 | INT8 | 32 | 1370 | 32 | 512 |
| License Plate Recognition | ResNet | 96x48x3 | FP16 | 32 | 1190 | – | – |
| Facial landmark | 80x80x1 | FP16 | 32 | 2069 | – | – | |
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 64 | 1387 | – | – | |
| GestureNet | 160x160x3 | FP16 | 64 | 4429 | – | – | |
| BodyPose | 288x384x3 | INT8 | 8 | 172 | – | – | |
| Action Recognition 2D RGB | 2D CNN | 224x224x96 | FP16 | 16 | 471 | – | – |
| Action Recognition 3D RGB | 3D CNN | 224x224x32x3 | FP16 | 4 | 32 | – | – |
| Action Recognition 2D OF | 2D Optical Flow | 224x224x96 | FP16 | 16 | 658 | – | – |
| Action Recognition 3D OF | 3D Optical Flow | 224x224x32x3 | FP16 | 4 | 41 | – | – |
| Point Pillar | Point Pillar | FP16 | 1 | 40 | – | – | |
| Pose classification | ST-GCN | FP16 | 8 | 150 | – | – | |
| 3D Pose - Accuracy | FP16 | 16 | 188 | – | – | ||
| 3D Pose - Performance | FP16 | 16 | 235 | – | – | ||
| PeopleSemSegNet_v2 - Shuffle | UNET - Shuffle | 960x544x3 | FP16 | 16 | 356 | – | – |
| PeopleSemSegNet_v2 - Vanilla | UNET - Vanilla | 960x544x3 | FP16 | 4 | 25 | – | – |
| PeopleNet Transformer | D-DETR | 960x544x3 | FP16 | 2 | 15 | – | – |
| ReidentificationNet | ResNet50 | 3x256x18 | FP16 | 64 | 854 | – | – |
| RetailObjectDetection v1.0 - 100 class | EfficientNet-D5 | 416x416x3 | FP16 | 16 | 48 | – | – |
| RetailObjectDetection v1.0 - binary | EfficientNet-D5 | 416x416x3 | FP16 | 16 | 45 | – | – |
| RetailObjectEmbedding v1.0 | ResNet101 | 3x224x224 | FP16 | 32 | 423 | – | – |
| CitySemSegFormer v1.0 | SegFormer | FP16 | 1 | 0.7 | – | – |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 16 | 4249 |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 8 | 2647 |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 8 | 1720 |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 8 | 1154 |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 8 | 1005 |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 16 | 6282 |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 16 | 4632 |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 16 | 3118 |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | 8 | 2022 |
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 8 | 1282 |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 4 | 628 |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 2 | 247 |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 4 | 558 |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | 4 | 366 |
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 32 | 19577 |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 16 | 7723 |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 16 | 7234 |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 16 | 5063 |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 16 | 3740 |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 16 | 2671 |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 1 | 283 |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 1 | 182 |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 1 | 215 |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 1 | 119.5 |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 1 | 151 |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 1 | 68.5 |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | 8 | 1985 |
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | 8 | 1510 |
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | 8 | 1144 |
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | 8 | 840 |
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 1 | 88.5 |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 1 | 88.6 |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 8 | 1648 |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 8 | 1124 |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 32 | 9407 |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 128 | 10390 |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 4 | 940 |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | 4 | 445 |
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 128 | 18971 |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 256 | 13950 |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 16 | 6619 |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 1 | 47.3 |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 1 | 40.9 |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | 2 | 210 |
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 4 | 980 |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 8 | 364 |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 106.70 |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 56.65 |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 8 | 1604 |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 8 | 949 |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 4 | 632 |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 4 | 442 |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 4 | 365 |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 8 | 2440 |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 8 | 1797 |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 16 | 1266 |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | 8 | 817 |
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 8 | 546 |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 8 | 268 |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 4 | 101 |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 4 | 207 |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | 4 | 145 |
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 16 | 7072 |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 16 | 2454 |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 16 | 2306 |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 16 | 1527 |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 16 | 1134 |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 16 | 780 |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 1 | 107 |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 1 | 70 |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 1 | 79.6 |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 1 | 44 |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 1 | 56.6 |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 1 | 26.4 |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | 4 | 750 |
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | 4 | 581 |
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | 4 | 442 |
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | 4 | 341 |
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 1 | 34.1 |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 1 | 34.1 |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 4 | 603 |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 4 | 430 |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 16 | 4375 |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 32 | 2821 |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 1 | 333 |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | 1 | 169 |
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 128 | 8036 |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 64 | 6045 |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 8 | 2543 |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 1 | 17.8 |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 1 | 15.7 |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | 1 | 83.4 |
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 4 | 344 |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 8 | 131.48 |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 40.68 |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 18.69 |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 128 | 6555 |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 128 | 4393 |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 64 | 2833 |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 64 | 1982 |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 32 | 1692 |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 128 | 11942 |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 128 | 9094 |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 128 | 6381 |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | 64 | 4145 |
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 64 | 3040 |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 64 | 1618 |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 32 | 613 |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 64 | 985 |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | 64 | 681 |
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 256 | 28765 |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 256 | 11363 |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 256 | 10830 |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 256 | 8115 |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 64 | 5915 |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 256 | 4323 |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 32 | 526 |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 32 | 317 |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 32 | 442 |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 32 | 213 |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 32 | 290 |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 32 | 125.5 |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | 64 | 4189 |
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | 64 | 3143 |
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | 64 | 2306 |
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | 64 | 1732 |
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 32 | 167 |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 32 | 167 |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 64 | 2686 |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 64 | 1919 |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 64 | 29070 |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 128 | 24107 |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 64 | 1468 |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | 64 | 706 |
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 512 | 55717 |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 512 | 48492 |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 128 | 12273 |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 8 | 108 |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 8 | 89.5 |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | 32 | 454 |
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 64 | 1581 |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 32 | 841 |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 105.84 |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 76.26 |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 4 | 99.1 |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 4 | 64.5 |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 4 | 42.3 |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 4 | 29.8 |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 4 | 27 |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 8 | 146 |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 8 | 111 |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 8 | 75 |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | ||
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 4 | 35.2 |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 4 | 19.8 |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | ||
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 4 | 16 |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | ||
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 32 | 571 |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 32 | 227 |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 16 | 208 |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 16 | 155 |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 16 | 116 |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 8 | 81 |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 1 | 6.6 |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 1 | 3.6 |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 1 | 5.7 |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 1 | 3.1 |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 1 | 3.3 |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 1 | 1.8 |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | ||
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | ||
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | ||
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 1 | 2.3 |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 1 | 2.3 |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 4 | 40.2 |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 4 | 28.4 |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 16 | 393 |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 16 | 399 |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | ||
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | ||
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 64 | 935 |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 64 | 715 |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 4 | 133.9 |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 1 | 1.36 |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 1 | 1.2 |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | ||
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 16 | 31 |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 16 | 15.2 |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 19.16 |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 7.94 |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| PeopleNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 1379 |
| PeopleNet (v2.3) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 1064 |
| PeopleNet (v2.5 unpruned) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 465 |
| TrafficCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 1725 |
| DashCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 1676 |
| FaceDetect-IR | DetectNet_v2 - ResNet18 | 384x240x3 | INT8 | 128 | 9810 |
| VehilceMakeNet | ResNet18 | 224x224x3 | INT8 | 256 | 16500 |
| VehicleTypeNet | ResNet18 | 224x224x3 | INT8 | 128 | 12500 |
| FaceDetect (pruned) | DetectNet_v2 - ResNet18 | 736x416x3 | INT8 | 64 | 2578 |
| License Plate Detection v1.0 | DetectNet_v2 - ResNet18 | 640x480x3 | INT8 | 128 | 6123 |
| License Plate Recognition | ResNet | 96x48x3 | FP16 | 128 | 3959 |
| Facial landmark | 80x80x1 | FP16 | 128 | 4622 | |
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 512 | 4563 | |
| GestureNet | 160x160x3 | FP16 | 512 | 15377 | |
| BodyPose | 288x384x3 | INT8 | 32 | 598 | |
| Action Recognition 2D RGB | 2D CNN | 224x224x96 | FP16 | 16 | 1897 |
| Action Recognition 3D RGB | 3D CNN | 224x224x32x3 | FP16 | 4 | 139 |
| Action Recognition 2D OF | 2D Optical Flow | 224x224x96 | FP16 | 32 | 3320 |
| Action Recognition 3D OF | 3D Optical Flow | 224x224x32x3 | FP16 | 16 | 192 |
| Point Pillar | Point Pillar | FP16 | 1 | 111 | |
| Pose classification | ST-GCN | FP16 | 64 | 376.4 | |
| 3D Pose - Accuracy | FP16 | 32 | 614.98 | ||
| 3D Pose - Performance | FP16 | 32 | 712.94 | ||
| PeopleSemSegNet_v2 - Shuffle | UNET - Shuffle | 960x544x3 | FP16 | 64 | 1027.85 |
| PeopleSemSegNet_v2 - Vanilla | UNET - Vanilla | 960x544x3 | FP16 | 16 | 79.08 |
| PeopleNet Transformer | D-DETR | 960x544x3 | FP16 | 4 | 48 |
| ReidentificationNet | ResNet50 | 3x256x18 | FP16 | 64 | 2586 |
| RetailObjectDetection v1.0 - 100 class | EfficientNet-D5 | 416x416x3 | FP16 | 32 | 162 |
| RetailObjectDetection v1.0 - binary | EfficientNet-D5 | 416x416x3 | FP16 | 32 | 151 |
| RetailObjectEmbedding v1.0 | ResNet101 | 3x224x224 | FP16 | 32 | 1270 |
| CitySemSegFormer v1.0 | SegFormer | FP16 | 1 | 2 | |
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 16 | 624 |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 8 | 403 |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 8 | 259 |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 16 | 188 |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 16 | 166 |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 16 | 999 |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 32 | 739 |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 16 | 517 |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | 8 | 335 |
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 4 | 223 |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 16 | 122 |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 4 | 45.1 |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 8 | 91 |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | 4 | 62 |
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 64 | 2735 |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 64 | 1099 |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 32 | 1006 |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 32 | 753 |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 16 | 526 |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 16 | 375 |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 1 | 46.5 |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 4 | 30.3 |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 4 | 38.9 |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 4 | 20 |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 8 | 26.7 |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 4 | 10.9 |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | 16 | 374 |
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | 8 | 272 |
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | 8 | 198 |
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | 16 | 156.7 |
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 2 | 15.2 |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 4 | 15.4 |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 8 | 253 |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 16 | 184 |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 16 | 1838 |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 32 | 2314 |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 16 | 155 |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | 1 | 72.5 |
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 128 | 3649 |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 128 | 2673 |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 16 | 1012 |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 1 | 9.4 |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 1 | 7.3 |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | 4 | 39.6 |
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 16 | 146 |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 16 | 59.7 |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 24.27 |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 9.77 |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
DLA1 + DLA2 BS |
DLA1 + DLA2 FPS |
|---|---|---|---|---|---|---|---|
| PeopleNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 16 | 400 | 16 | 300 |
| PeopleNet (v2.3) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 314 | 32 | 226 |
| PeopleNet (v2.5 unpruned) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 16 | 140 | 32 | 70 |
| TrafficCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 16 | 457 | 16 | 352 |
| DashCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 32 | 479 | 64 | 358 |
| FaceDetect-IR | DetectNet_v2 - ResNet18 | 384x240x3 | INT8 | 64 | 2588 | 64 | 1700 |
| VehilceMakeNet | ResNet18 | 224x224x3 | INT8 | 64 | 4261 | 64 | 2218 |
| VehicleTypeNet | ResNet18 | 224x224x3 | INT8 | 64 | 3391 | 64 | 2044 |
| FaceDetect (pruned) | DetectNet_v2 - ResNet18 | 736x416x3 | INT8 | 32 | 613 | 32 | 492 |
| License Plate Detection v1.0 | DetectNet_v2 - ResNet18 | 640x480x3 | INT8 | 32 | 32 | ||
| License Plate Recognition | ResNet | 96x48x3 | FP16 | 128 | 1498 | – | – |
| Facial landmark | 80x80x1 | FP16 | 32 | 1606 | – | – | |
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 64 | 1241 | – | – | |
| GestureNet | 160x160x3 | FP16 | 64 | 5420 | – | – | |
| BodyPose | 288x384x3 | INT8 | 16 | 195 | – | – | |
| Action Recognition 2D RGB | 2D CNN | 224x224x96 | FP16 | 32 | 577 | – | – |
| Action Recognition 3D RGB | 3D CNN | 224x224x32x3 | FP16 | 4 | 38 | – | – |
| Action Recognition 2D OF | 2D Optical Flow | 224x224x96 | FP16 | 16 | 826 | – | – |
| Action Recognition 3D OF | 3D Optical Flow | 224x224x32x3 | FP16 | 4 | 42 | – | – |
| Point Pillar | Point Pillar | FP16 | 1 | 38 | – | – | |
| Pose classification | ST-GCN | FP16 | 8 | 105 | – | – | |
| 3D Pose - Accuracy | FP16 | 16 | 241 | – | – | ||
| 3D Pose - Performance | FP16 | 16 | 295 | – | – | ||
| PeopleSemSegNet_v2 - Shuffle | UNET - Shuffle | 960x544x3 | FP16 | 16 | 289 | – | – |
| PeopleSemSegNet_v2 - Vanilla | UNET - Vanilla | 960x544x3 | FP16 | 4 | 27 | – | – |
| PeopleNet Transformer | D-DETR | 960x544x3 | FP16 | 2 | 13 | – | – |
| ReidentificationNet | ResNet50 | 3x256x18 | FP16 | 64 | 1049 | – | – |
| RetailObjectDetection v1.0 - 100 class | EfficientNet-D5 | 416x416x3 | FP16 | 16 | 48 | – | – |
| RetailObjectDetection v1.0 - binary | EfficientNet-D5 | 416x416x3 | FP16 | 16 | 45 | – | – |
| RetailObjectEmbedding v1.0 | ResNet101 | 3x224x224 | FP16 | 32 | 544 | – | – |
| CitySemSegFormer v1.0 | SegFormer | FP16 | 1 | 0.6 | – | – | |
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 4 | 146.6 | – | – |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 4 | 94.5 | – | – |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 4 | 62 | – | – |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 4 | 43.9 | – | – |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 4 | 39.9 | – | – |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 8 | 212 | – | – |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 8 | 163 | – | – |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 8 | 110 | – | – |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | – | – | ||
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 4 | 51.2 | – | – |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 4 | 28.8 | – | – |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 1 | 10.4 | – | – |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 4 | 23.4 | – | – |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | – | – | ||
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 64 | 870 | – | – |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 64 | 344 | – | – |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 32 | 313 | – | – |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 32 | 234 | – | – |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 32 | 175 | – | – |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 16 | 123 | – | – |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 1 | 9.6 | – | – |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 1 | 5.2 | – | – |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 1 | 8.4 | – | – |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 1 | 4.4 | – | – |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 1 | 4.9 | – | – |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 1 | 2.6 | – | – |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | – | – | ||
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | – | – | ||
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | – | – | ||
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | – | – | ||
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | – | – | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 1 | 3.4 | – | – |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 1 | 3.4 | – | – |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 4 | 59.8 | – | – |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 4 | 41.9 | – | – |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 16 | 575 | – | – |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 16 | 482 | – | – |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 2 | 45 | – | – |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | 2 | 22 | – | – |
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 64 | 1373 | – | – |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 64 | 1051 | – | – |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 4 | 198 | – | – |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 1 | 1.9 | – | – |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 1 | 1.78 | – | – |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | – | – | ||
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 16 | 44.7 | – | – |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 16 | 21.92 | – | – |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 27.74 | – | – |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 11.35 | – | – |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
DLA1 + DLA2 BS |
DLA1 + DLA2 FPS |
|---|---|---|---|---|---|---|---|
| PeopleNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 32 | 1116 | 32 | 528 |
| PeopleNet (v2.3) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 890 | 32 | 404 |
| PeopleNet (v2.5 unpruned) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 16 | 421 | 32 | 104 |
| TrafficCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 32 | 1268 | 32 | 594 |
| DashCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 32 | 1308 | 64 | 587 |
| FaceDetect-IR | DetectNet_v2 - ResNet18 | 384x240x3 | INT8 | 128 | 7462 | 128 | 2720 |
| VehilceMakeNet | ResNet18 | 224x224x3 | INT8 | 128 | 11872 | 128 | 3956 |
| VehicleTypeNet | ResNet18 | 224x224x3 | INT8 | 128 | 9815 | 128 | 3494 |
| FaceDetect (pruned) | DetectNet_v2 - ResNet18 | 736x416x3 | INT8 | 64 | 1700 | 64 | 870 |
| License Plate Detection v1.0 | DetectNet_v2 - ResNet18 | 640x480x3 | INT8 | 64 | 64 | ||
| License Plate Recognition | ResNet | 96x48x3 | FP16 | 128 | 4118 | – | – |
| Facial landmark | 80x80x1 | FP16 | 64 | – | – | ||
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 128 | 3226 | – | – | |
| GestureNet | 160x160x3 | FP16 | 128 | 15133 | – | – | |
| BodyPose | 288x384x3 | INT8 | 16 | 559 | – | – | |
| Action Recognition 2D RGB | 2D CNN | 224x224x96 | FP16 | 64 | 1577 | – | – |
| Action Recognition 3D RGB | 3D CNN | 224x224x32x3 | FP16 | 8 | 105 | – | – |
| Action Recognition 2D OF | 2D Optical Flow | 224x224x96 | FP16 | 32 | 1702 | – | – |
| Action Recognition 3D OF | 3D Optical Flow | 224x224x32x3 | FP16 | 4 | 109 | – | – |
| Point Pillar | Point Pillar | FP16 | 1 | 90 | – | – | |
| Pose classification | ST-GCN | FP16 | 16 | 262 | – | – | |
| 3D Pose - Accuracy | FP16 | 16 | 597 | – | – | ||
| 3D Pose - Performance | FP16 | 16 | 711 | – | – | ||
| PeopleSemSegNet_v2 - Shuffle | UNET - Shuffle | 960x544x3 | FP16 | 32 | 703 | – | – |
| PeopleSemSegNet_v2 - Vanilla | UNET - Vanilla | 960x544x3 | FP16 | 4 | 75 | – | – |
| PeopleNet Transformer | D-DETR | 960x544x3 | FP16 | 2 | 33 | – | – |
| ReidentificationNet | ResNet50 | 3x256x18 | FP16 | 64 | 2772 | – | – |
| RetailObjectDetection v1.0 - 100 class | EfficientNet-D5 | 416x416x3 | FP16 | 16 | 121 | – | – |
| RetailObjectDetection v1.0 - binary | EfficientNet-D5 | 416x416x3 | FP16 | 16 | 114 | – | – |
| RetailObjectEmbedding v1.0 | ResNet101 | 3x224x224 | FP16 | 32 | 1355 | – | – |
| CitySemSegFormer v1.0 | SegFormer | FP16 | 1 | 1.5 | – | – | |
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 8 | 385 | – | – |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 8 | 255 | – | – |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 8 | 166 | – | – |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 8 | 117 | – | – |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 8 | 106 | – | – |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 16 | 559 | – | – |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 16 | 431 | – | – |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 16 | 293 | – | – |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | – | – | ||
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 8 | 138 | – | – |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 8 | 80.7 | – | – |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 4 | 28.1 | – | – |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 8 | 61.2 | – | – |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | – | – | ||
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 64 | 2152 | – | – |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 64 | 860 | – | – |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 64 | 811 | – | – |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 64 | 609 | – | – |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 64 | 451 | – | – |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 32 | 318 | – | – |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 4 | 25.8 | – | – |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 4 | 14.2 | – | – |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 4 | 22 | – | – |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 4 | 11.2 | – | – |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 4 | 13 | – | – |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 1 | 6.2 | – | – |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | – | – | ||
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | – | – | ||
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | – | – | ||
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | – | – | ||
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | – | – | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 1 | 8.1 | – | – |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 1 | 8.1 | – | – |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 8 | 161 | – | – |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 8 | 112 | – | – |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 32 | 1541 | – | – |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 32 | 1538 | – | – |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 4 | 120 | – | – |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | – | – | ||
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 128 | 3876 | – | – |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 128 | 2950 | – | – |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 16 | 560 | – | – |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 1 | 4.8 | – | – |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 1 | 4.4 | – | – |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | – | – | ||
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 16 | 113.2 | – | – |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 16 | 55 | – | – |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 57.04 | – | – |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 28.03 | – | – |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| PeopleNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 3819 |
| PeopleNet (v2.3) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 2568 |
| PeopleNet (v2.5 unpruned) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 1007 |
| TrafficCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 4754 |
| DashCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 4600 |
| FaceDetect-IR | DetectNet_v2 - ResNet18 | 384x240x3 | INT8 | 128 | 26900 |
| VehilceMakeNet | ResNet18 | 224x224x3 | INT8 | 256 | 44800 |
| VehicleTypeNet | ResNet18 | 224x224x3 | INT8 | 256 | 31500 |
| FaceDetect (pruned) | DetectNet_v2 - ResNet18 | 736x416x3 | INT8 | 64 | 6000 |
| License Plate Detection v1.0 | DetectNet_v2 - ResNet18 | 640x480x3 | INT8 | 256 | 13900 |
| License Plate Recognition | ResNet | 96x48x3 | FP16 | 256 | 9000 |
| Facial landmark | 80x80x1 | FP16 | 512 | 9600 | |
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 512 | 10718 | |
| GestureNet | 160x160x3 | FP16 | 512 | 35371 | |
| BodyPose | 288x384x3 | INT8 | 32 | 1334 | |
| Action Recognition 2D RGB | 2D CNN | 224x224x96 | FP16 | 16 | 4600 |
| Action Recognition 3D RGB | 3D CNN | 224x224x32x3 | FP16 | 4 | 265 |
| Action Recognition 2D OF | 2D Optical Flow | 224x224x96 | FP16 | 32 | 6500 |
| Action Recognition 3D OF | 3D Optical Flow | 224x224x32x3 | FP16 | 16 | 284 |
| Point Pillar | Point Pillar | FP16 | 1 | 246 | |
| Pose classification | ST-GCN | FP16 | 64 | 825.75 | |
| 3D Pose - Accuracy | FP16 | 32 | 1286.05 | ||
| 3D Pose - Performance | FP16 | 32 | 1558.21 | ||
| PeopleSemSegNet_v2 - Shuffle | UNET - Shuffle | 960x544x3 | FP16 | 64 | 2429.62 |
| PeopleSemSegNet_v2 - Vanilla | UNET - Vanilla | 960x544x3 | FP16 | 16 | 180.04 |
| PeopleNet Transformer | D-DETR | 960x544x3 | FP16 | 16 | 106 |
| ReidentificationNet | ResNet50 | 3x256x18 | FP16 | 128 | 6129 |
| RetailObjectDetection v1.0 - 100 class | EfficientNet-D5 | 416x416x3 | FP16 | 64 | 367 |
| RetailObjectDetection v1.0 - binary | EfficientNet-D5 | 416x416x3 | FP16 | 64 | 341 |
| RetailObjectEmbedding v1.0 | ResNet101 | 3x224x224 | FP16 | 64 | 3105 |
| CitySemSegFormer v1.0 | SegFormer | FP16 | 1 | 4.5 |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| PeopleNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 32 | 749 |
| PeopleNet (v2.3) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 581 |
| PeopleNet (v2.5 unpruned) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 231 |
| TrafficCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 32 | 916 |
| DashCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 32 | 865 |
| FaceDetect-IR | DetectNet_v2 - ResNet18 | 384x240x3 | INT8 | 64 | 4982 |
| VehilceMakeNet | ResNet18 | 224x224x3 | INT8 | 128 | 8000 |
| VehicleTypeNet | ResNet18 | 224x224x3 | INT8 | 128 | 6302 |
| FaceDetect (pruned) | DetectNet_v2 - ResNet18 | 736x416x3 | INT8 | 32 | 1174 |
| License Plate Detection v1.0 | DetectNet_v2 - ResNet18 | 640x480x3 | INT8 | 128 | 2570 |
| License Plate Recognition | ResNet | 96x48x3 | FP16 | 128 | 2180 |
| Facial landmark | 80x80x1 | FP16 | 256 | 2800 | |
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 256 | 2488 | |
| GestureNet | 160x160x3 | FP16 | 256 | 7690 | |
| BodyPose | 288x384x3 | INT8 | 16 | 278 | |
| Action Recognition 2D RGB | 2D CNN | 224x224x96 | FP16 | 8 | 1044 |
| Action Recognition 3D RGB | 3D CNN | 224x224x32x3 | FP16 | 4 | 56 |
| Action Recognition 2D OF | 2D Optical Flow | 224x224x96 | FP16 | 16 | 1419 |
| Action Recognition 3D OF | 3D Optical Flow | 224x224x32x3 | FP16 | 2 | 58 |
| Point Pillar | Point Pillar | FP16 | 1 | 63 | |
| Pose classification | ST-GCN | FP16 | 64 | 211.5 | |
| 3D Pose - Accuracy | FP16 | 32 | 370.13 | ||
| 3D Pose - Performance | FP16 | 32 | 471.81 | ||
| PeopleSemSegNet_v2 - Shuffle | UNET - Shuffle | 960x544x3 | FP16 | 16 | 631.31 |
| PeopleSemSegNet_v2 - Vanilla | UNET - Vanilla | 960x544x3 | FP16 | 16 | 44.09 |
| PeopleNet Transformer | D-DETR | 960x544x3 | FP16 | 4 | 27 |
| ReidentificationNet | ResNet50 | 3x256x18 | FP16 | 64 | 1570 |
| RetailObjectDetection v1.0 - 100 class | EfficientNet-D5 | 416x416x3 | FP16 | 32 | 106 |
| RetailObjectDetection v1.0 - binary | EfficientNet-D5 | 416x416x3 | FP16 | 32 | 99 |
| RetailObjectEmbedding v1.0 | ResNet101 | 3x224x224 | FP16 | 32 | 803 |
| CitySemSegFormer v1.0 | SegFormer | FP16 | 1 | 1.3 | |
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 16 | 399 |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 16 | 256 |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 16 | 168 |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 16 | 118 |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 8 | 103 |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 16 | 666 |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 32 | 492 |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 32 | 336 |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | 16 | 213 |
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 16 | 137 |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 16 | 67 |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 2 | 26 |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 8 | 55.5 |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | 1 | 38 |
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 64 | 1870 |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 64 | 726 |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 64 | 690 |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 64 | 518 |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 32 | 363 |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 32 | 265 |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 1 | 27.7 |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 1 | 17.9 |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 1 | 22.5 |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 1 | 11.7 |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 1 | 15.7 |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 1 | 6.7 |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | 16 | 230 |
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | 16 | 174 |
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | 16 | 129 |
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | 16 | 97.7 |
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 1 | 8.9 |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 1 | 8.8 |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 16 | 161 |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 16 | 113 |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 16 | 1200 |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 32 | 1391 |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 8 | 93 |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | 1 | 45.5 |
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 128 | 2094 |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 128 | 1482 |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 32 | 688 |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 1 | 5.8 |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 1 | 4.4 |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | 1 | 23.3 |
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 16 | 95.81 |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 16 | 36.02 |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 15.69 |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 5.80 |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| PeopleNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 128 | 8500 |
| PeopleNet (v2.3) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 64 | 6245 |
| PeopleNet (v2.5 unpruned) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 64 | 3291 |
| TrafficCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 256 | 9717 |
| DashCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 256 | 9500 |
| FaceDetect-IR | DetectNet_v2 - ResNet18 | 384x240x3 | INT8 | 256 | 51600 |
| VehilceMakeNet | ResNet18 | 224x224x3 | INT8 | 1024 | 88300 |
| VehicleTypeNet | ResNet18 | 224x224x3 | INT8 | 512 | 72300 |
| FaceDetect (pruned) | DetectNet_v2 - ResNet18 | 736x416x3 | INT8 | 256 | 14900 |
| License Plate Detection v1.0 | DetectNet_v2 - ResNet18 | 640x480x3 | INT8 | 256 | 23200 |
| License Plate Recognition | ResNet | 96x48x3 | FP16 | 256 | 27200 |
| Facial landmark | 80x80x1 | FP16 | 256 | 19600 | |
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 1024 | 25394 | |
| GestureNet | 160x160x3 | FP16 | 1024 | 94555 | |
| BodyPose | 288x384x3 | INT8 | 16 | 3180 | |
| Action Recognition 2D RGB | 2D CNN | 224x224x96 | FP16 | 32 | 12600 |
| Action Recognition 3D RGB | 3D CNN | 224x224x32x3 | FP16 | 16 | 797 |
| Action Recognition 2D OF | 2D Optical Flow | 224x224x96 | FP16 | 64 | 17535 |
| Action Recognition 3D OF | 3D Optical Flow | 224x224x32x3 | FP16 | 16 | 899 |
| Point Pillar | Point Pillar | FP16 | 1 | 425 | |
| Pose classification | ST-GCN | FP16 | 64 | 2144.84 | |
| 3D Pose - Accuracy | FP16 | 32 | 3466.34 | ||
| 3D Pose - Performance | FP16 | 32 | 4176.37 | ||
| PeopleSemSegNet_v2 - Shuffle | UNET - Shuffle | 960x544x3 | FP16 | 64 | 5745.79 |
| PeopleSemSegNet_v2 - Vanilla | UNET - Vanilla | 960x544x3 | FP16 | 16 | 496.34 |
| PeopleNet Transformer | D-DETR | 960x544x3 | FP16 | 16 | 267 |
| ReidentificationNet | ResNet50 | 3x256x18 | FP16 | 256 | 20781 |
| RetailObjectDetection v1.0 - 100 class | EfficientNet-D5 | 416x416x3 | FP16 | 64 | 1012 |
| RetailObjectDetection v1.0 - binary | EfficientNet-D5 | 416x416x3 | FP16 | 64 | 947 |
| RetailObjectEmbedding v1.0 | ResNet101 | 3x224x224 | FP16 | 64 | 9851 |
| CitySemSegFormer v1.0 | SegFormer | FP16 | 4 | 13 | |
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 128 | 3867 |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 128 | 2576 |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 64 | 1692 |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 64 | 1196 |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 32 | 1046 |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 128 | 6863 |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 128 | 5162 |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 128 | 3600 |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | 64 | 2435 |
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 64 | 1663 |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 64 | 917 |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 32 | 344 |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 64 | 577 |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | 64 | 402 |
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 256 | 17909 |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 256 | 6994 |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 256 | 6665 |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 256 | 4987 |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 64 | 3577 |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 256 | 2583 |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 32 | 296 |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 32 | 184 |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 32 | 244 |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 32 | 121 |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 32 | 165 |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 16 | 70.6 |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | 64 | 2381 |
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | 64 | 1808 |
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | 64 | 1338 |
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | 64 | 1000 |
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 32 | 94.3 |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 32 | 94.2 |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 64 | 1621 |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 64 | 1155 |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 64 | 15584 |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 128 | 15660 |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 64 | 724 |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | 64 | 351 |
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 512 | 28297 |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 512 | 21212 |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 128 | 7095 |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 8 | 62.2 |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 8 | 50.4 |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | 32 | 254 |
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 16 | 920 |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 16 | 435 |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 82.16 |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 49.99 |
Model Name |
Arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|---|
| PeopleNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 4228 |
| PeopleNet (v2.3) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 3160 |
| PeopleNet (v2.5 unpruned) | DetectNet_v2 - ResNet34 | 960x544x3 | INT8 | 32 | 1603 |
| TrafficCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 5082 |
| DashCamNet | DetectNet_v2 - ResNet18 | 960x544x3 | INT8 | 64 | 4900 |
| FaceDetect-IR | DetectNet_v2 - ResNet18 | 384x240x3 | INT8 | 128 | 27100 |
| VehilceMakeNet | ResNet18 | 224x224x3 | INT8 | 256 | 46200 |
| VehicleTypeNet | ResNet18 | 224x224x3 | INT8 | 128 | 37200 |
| FaceDetect (pruned) | DetectNet_v2 - ResNet18 | 736x416x3 | INT8 | 64 | 7700 |
| License Plate Detection v1.0 | DetectNet_v2 - ResNet18 | 640x480x3 | INT8 | 128 | 12500 |
| License Plate Recognition | ResNet | 96x48x3 | FP16 | 128 | 12400 |
| Facial landmark | 80x80x1 | FP16 | 128 | 12400 | |
| GazeNet | 224x224x1, 224x224x1, 224x224x1, 25x25x1 | FP16 | 512 | 12321 | |
| GestureNet | 160x160x3 | FP16 | 512 | 47361 | |
| BodyPose | 288x384x3 | INT8 | 32 | 1596 | |
| Action Recognition 2D RGB | 2D CNN | 224x224x96 | FP16 | 16 | 6000 |
| Action Recognition 3D RGB | 3D CNN | 224x224x32x3 | FP16 | 4 | 380 |
| Action Recognition 2D OF | 2D Optical Flow | 224x224x96 | FP16 | 32 | 8940 |
| Action Recognition 3D OF | 3D Optical Flow | 224x224x32x3 | FP16 | 16 | 461 |
| Point Pillar | Point Pillar | FP16 | 1 | 271 | |
| Pose classification | ST-GCN | FP16 | 64 | 1121.68 | |
| 3D Pose - Accuracy | FP16 | 32 | 1913.92 | ||
| 3D Pose - Performance | FP16 | 32 | 2241.83 | ||
| PeopleSemSegNet_v2 - Shuffle | UNET - Shuffle | 960x544x3 | FP16 | 64 | 2862.76 |
| PeopleSemSegNet_v2 - Vanilla | UNET - Vanilla | 960x544x3 | FP16 | 16 | 253.77 |
| PeopleNet Transformer | D-DETR | 960x544x3 | FP16 | 16 | 135 |
| ReidentificationNet | ResNet50 | 3x256x18 | FP16 | 128 | 9649 |
| RetailObjectDetection v1.0 - 100 class | EfficientNet-D5 | 416x416x3 | FP16 | 64 | 485 |
| RetailObjectDetection v1.0 - binary | EfficientNet-D5 | 416x416x3 | FP16 | 64 | 450 |
| RetailObjectEmbedding v1.0 | ResNet101 | 3x224x224 | FP16 | 64 | 4791 |
| CitySemSegFormer v1.0 | SegFormer | FP16 | 1 | 6.4 | |
| ImageNet Classification | FAN-T-H | 224x224x3 | FP16 | 32 | 1806 |
| ImageNet Classification | FAN-S-H | 224x224x3 | FP16 | 32 | 1185 |
| ImageNet Classification | FAN-B-H | 224x224x3 | FP16 | 16 | 769 |
| ImageNet Classification | FAN-L-H | 224x224x3 | FP16 | 16 | 548 |
| ImageNet Classification | FAN-XL-H | 224x224x3 | FP16 | 16 | 423 |
| ImageNet Classification | GC-ViT-xxTiny | 224x224x3 | FP16 | 32 | 3105 |
| ImageNet Classification | GC-ViT-xTiny | 224x224x3 | FP16 | 32 | 2339 |
| ImageNet Classification | GC-ViT-T | 224x224x3 | FP16 | 32 | 1658 |
| ImageNet Classification | GC-ViT-S | 224x224x3 | FP16 | 16 | 1077 |
| ImageNet Classification | GC-ViT-B | 224x224x3 | FP16 | 16 | 711 |
| ImageNet Classification | GC-ViT-L | 224x224x3 | FP16 | 16 | 388 |
| ImageNet Classification | GC-ViT-L-384 | 384x384x3 | FP16 | 8 | 151 |
| ImageNet Classification | FAN-B-H-384 (384 resolution) | 384x384x3 | FP16 | 16 | 260 |
| ImageNet Classification | FAN-L-H-384 | 384x384x3 | FP16 | 8 | 179 |
| ImageNet Classification | EfficientNetB0 | 224x224x3 | FP16 | 64 | 8361 |
| ImageNet Classification | EfficientNetB1 | 224x224x3 | FP16 | 64 | 3245 |
| ImageNet Classification | EfficientNetB2 | 224x224x3 | FP16 | 64 | 3078 |
| ImageNet Classification | EfficientNetB3 | 224x224x3 | FP16 | 64 | 2320 |
| ImageNet Classification | EfficientNetB4 | 224x224x3 | FP16 | 64 | 1669 |
| ImageNet Classification | EfficientNetB5 | 224x224x3 | FP16 | 64 | 1203 |
| COCO Object Detection | DDETR+RN50 | 960x544x3 | FP16 | 8 | 141 |
| COCO Object Detection | DDETR + GCViT-T | 960x544x3 | FP16 | 8 | 87 |
| COCO Object Detection | DINO + RN50 | 960x544x3 | FP16 | 8 | 115 |
| COCO Object Detection | DINO + FAN-S | 960x544x3 | FP16 | 4 | 56 |
| COCO Object Detection | DINO + GC-ViT-T | 960x544x3 | FP16 | 8 | 77 |
| COCO Object Detection | DINO + FAN-L | 960x544x3 | FP16 | 8 | 33.4 |
| Cityscapes Segmentation | SegFormer + FAN-T-H | 224x224x3 | FP16 | 16 | 1098 |
| Cityscapes Segmentation | Segformer + FAN-S-H | 224x224x3 | FP16 | 16 | 834 |
| Cityscapes Segmentation | SegFormer + FAN-B-H | 224x224x3 | FP16 | 16 | 606 |
| Cityscapes Segmentation | SegFormer + FAN-L-H | 224x224x3 | FP16 | 16 | 465 |
| RetailObjectDetection v2.0 - binary | Efficientdet-D5 | 960x544x3 | FP16 | ||
| RetailObjectDetection v2.0 - binary | DINO-FAN_base | 960x544x3 | FP16 | 8 | 44.2 |
| RetailObjectDetection v2.0 - Meta | DINO-FAN_base | 960x544x3 | FP16 | 8 | 44 |
| RetailObjectEmbedding v2.0 | FAN-B-H | 224x224x3 | FP16 | 16 | 734 |
| RetailObjectEmbedding v2.0 | FAN-L-H | 224x224x3 | FP16 | 16 | 522 |
| RetailObjectEmbedding v2.0 | NVCLIP-B | 224x224x3 | FP16 | 16 | 5886 |
| Siamese Optical Inspection | Siamese CNN | 2x512x128x3 | FP16 | 32 | 6318 |
| OCDNet | DCN-RN18 | 640x640x3 | FP16 | 16 | 387 |
| OCDNet | DCN-RN50 | 640x640x3 | FP16 | 8 | 186.6 |
| OCRNet | ResNet50 + Bi-LSTM pruned | 32x100x3 | FP16 | 128 | 12122 |
| OCRNet | ResNet50 + Bi-LSTM unpruned | 32x100x3 | FP16 | 128 | 9656 |
| PCB Inspection | GC-ViT-xxTiny | 224x224x3 | FP16 | 32 | 3221 |
| CitySemSegFormer v2.0 | Segformer + MIT | 1024x1024x3 | FP16 | 4 | 29.3 |
| CitySemSegFormer v2.0 | SegFormer + FAN -B-H | 1024x1024x3 | FP16 | 4 | 23.7 |
| PeopleSemSegFormer v2.0 | SegFormer + FAN-B-H | 512x512x3 | FP16 | 8 | 116.8 |
| Visual ChangeNet Classification | Visual ChangeNet + FAN -S-H | 512x128x3 | FP16 | 16 | 436 |
| Visual ChangeNet Segmentation | Visual ChangeNet + FAN -B-H | 256x256x3 | FP16 | 16 | 204 |
| CenterPose | DLA34 | 512x512x3 | FP16 | 1 | 57.46 |
| CenterPose | FAN-S-H | 512x512x3 | FP16 | 1 | 26.73 |
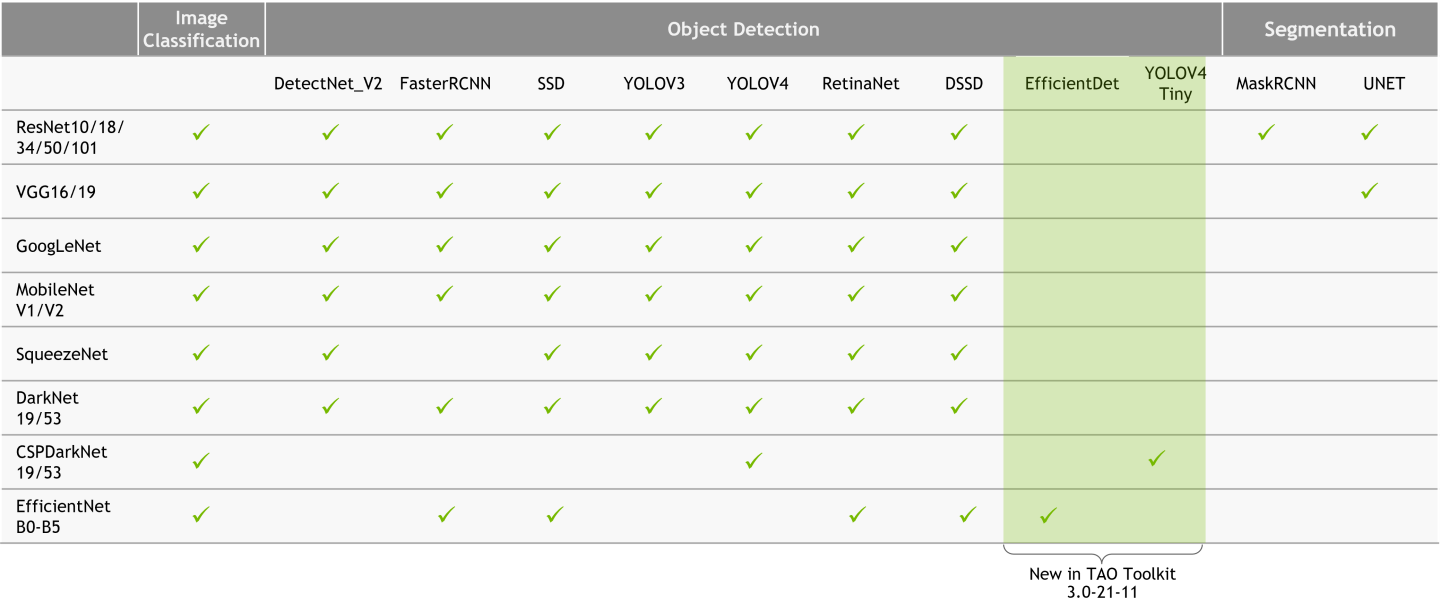
General purpose computer vision models
With general purpose models, you can train an image classification model, object detection model, or an instance segmentation model.
For classification, you can train using one of the available architectures such as ResNet, EfficientNet, VGG, MobileNet, GoogLeNet, SqueezeNet, or DarkNet.
For object detection tasks, you can choose from the popular YOLOv3/v4/v4-tiny, FasterRCNN, SSD, RetinaNet, and DSSD architectures, as well as NVIDIA’s own DetectNet_v2 architecture.
For instance segmentation, you can use MaskRCNN for instance segmentation or UNET for semantic segmentation.
This gives you the flexibility and control to build AI models for any number of applications, from smaller, light-weight models for edge GPUs to larger models for more complex tasks. For all the permutations and combinations, refer to the table below and see the Open Model Architectures section.
TAO Toolkit 3.0-22.05
Computer Vision Feature Summary
The table below summarizes the computer vision models and the features enabled.
CV Task |
Model |
New in 22-05 |
New in TAO 4.0 |
New in TAO 5.0 |
Pruning |
QAT |
AutoML |
REST API |
Channel-wise QAT |
Class weighting |
Visualization (TB) |
MLOPs integration (W&B/ClearML) |
BYOM |
Multi-node |
Multi-GPU |
AMP |
Early Stopping |
Framework |
Annotation Format |
DLA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Classification | ResNet10/18/34/50/101 | No | No | No | yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | VGG16/19 | No | No | No | yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | GoogleNet | No | No | No | yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | MobileNet_v1/v2 | No | No | No | yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | SqueezeNet | No | No | No | yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | DarkNet19/53 | No | No | No | yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | EfficientNet_B0-B7 | No | No | No | yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | CSPDarkNet19/53 | No | No | No | yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | CSPDarkNet-Tiny | No | No | No | Yes | No | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf1 | ImageNet | yes |
| Classification | EfficientNet_B0-B5 | No | No | No | yes | No | yes | yes | yes | no | yes | clearml,wandb | yes | yes | yes | yes | No | tf2 | ImageNet | yes |
| Classification | GcViT | No | No | Yes | No | No | yes | yes | no | yes | no | no | no | yes | yes | yes | No | pyt | ImageNet | no |
| Classification | FAN | No | No | Yes | No | No | yes | yes | no | yes | no | no | no | yes | yes | yes | No | pyt | ImageNet | no |
| Detection | YoloV3 | No | No | No | yes | yes | yes | yes | no | no | no | clearml,wandb | No | yes | yes | yes | No | tf1 | KITTI/COCO | yes |
| Detection | YoloV4 | No | No | No | yes | yes | yes | yes | no | yes | yes | clearml,wandb | No | yes | yes | yes | Yes | tf1 | KITTI/COCO | yes |
| Detection | YoloV4 - Tiny | No | No | No | yes | yes | yes | yes | no | yes | yes | clearml,wandb | No | yes | yes | yes | Yes | tf1 | KITTI/COCO | yes |
| Detection | FasterRCNN | No | No | No | yes | yes | yes | yes | no | no | yes | clearml,wandb | No | yes | yes | yes | yes | tf1 | KITTI/COCO | yes |
| Detection | EfficientDet | No | No | No | yes | no | yes | yes | no | no | no | no | No | yes | yes | yes | no | tf1 | COCO | yes |
| Detection | EfficientDet | No | No | No | yes | no | yes | no | yes | no | yes | clearml,wandb | No | yes | yes | yes | no | tf2 | COCO | yes |
| Detection | RetinaNet | No | No | No | yes | yes | yes | yes | no | yes | yes | clearml,wandb | No | yes | yes | yes | yes | tf1 | KITTI/COCO | yes |
| Detection | DetectNet_v2 | No | No | No | yes | yes | yes | yes | no | yes | yes | clearml,wandb | No | yes | yes | yes | yes | tf1 | KITTI/COCO | yes |
| Detection | SSD | No | No | No | yes | yes | yes | yes | no | no | yes | clearml,wandb | No | yes | yes | yes | yes | tf1 | KITTI/COCO | yes |
| Detection | DSSD | No | No | No | yes | yes | yes | yes | no | no | yes | clearml,wandb | No | yes | yes | yes | yes | tf1 | KITTI/COCO | yes |
| Detection | Deformable DETR | Yes | no | No | no | no | yes | yes | no | no | no | No | No | yes | yes | yes | no | pyt | COCO | no |
| Detection | DINO | No | no | Yes | no | no | yes | yes | no | no | no | No | No | yes | yes | yes | no | pyt | COCO | no |
| Multitask classification | All classification | No | No | No | yes | no | yes | yes | no | no | yes | clearml | No | yes | yes | yes | no | tf1 | Custom | yes |
| Instance Segmentation | MaskRCNN | No | No | No | yes | no | yes | yes | no | no | yes | clearml,wandb | No | yes | yes | yes | no | tf1 | COCO | no |
| Semantic Segmentation | Segformer | Yes | no | No | no | no | yes | yes | no | no | no | no | No | yes | no | no | no | pyt | CityScape - PNG | no |
| Semantic Segmentation | UNET | No | No | No | yes | yes | yes | yes | no | no | yes | clearml,wandb | yes | yes | yes | yes | no | tf1 | CityScape - PNG | no |
| OCR | LPR | No | No | No | no | no | yes | yes | no | no | yes | no | no | yes | yes | yes | yes | tf1 | Custom - txt file | no |
| Key Points | 2D body pose | No | No | No | yes | no, but PTQ | yes | yes | no | no | no | no | no | yes | yes | yes | no | tf1 | COCO | no |
| Key Points | 2D body pose | No | No | No | yes | no, but PTQ | yes | yes | no | no | no | no | no | yes | yes | yes | no | tf1 | COCO | no |
| Point Cloud | PointPillars | Yes | No | No | Yes | no | yes | yes | no | no | no | no | no | yes | yes | yes | no | pyt | KITTI | no |
| Action Recognition | 2D action recognition RGB | No | No | No | no | no | yes | yes | no | no | no | no | no | no | yes | yes | no | pyt | Custom | no |
| Action Recognition | 3D action recognition RGB | No | No | No | no | no | yes | yes | no | no | no | no | no | no | yes | yes | no | pyt | Custom | no |
| Action Recognition | 2D action recognition OF | No | No | No | no | no | yes | yes | no | no | no | no | no | no | yes | yes | no | pyt | Custom | no |
| Action Recognition | 3D action recognition OF | No | No | No | no | no | yes | yes | no | no | no | no | no | no | yes | yes | no | pyt | Custom | no |
| Other | Pose action classification | Yes | No | No | no | no | yes | yes | no | no | no | no | no | no | yes | yes | no | pyt | COCO | no |
| Other | HeartRateNet | No | No | No | no | no | yes | yes | no | no | no | no | no | no | yes | yes | no | tf1 | NVIDIA Defined | no |
| Other | GazeNet | No | No | No | no | no | yes | yes | no | no | no | no | no | no | yes | yes | no | tf1 | NVIDIA Defined | no |
| Other | EmotionNet | No | No | No | no | no | yes | no | no | no | yes | no | no | no | no | yes | no | tf1 | NVIDIA Defined | no |
| Other | GestureNet | No | No | No | no | no | yes | no | no | no | no | no | no | yes | yes | yes | no | tf1 | NVIDIA Defined | no |
| Feature Embedding | ResNet50 | Yes | no | No | no | no | yes | no | no | no | no | no | no | yes | no | no | no | pyt | Market1501 | No |
| Other | OpticalInspection | No | No | Yes | No | No | yes | yes | no | Yes (False Positive Rate Sampling) | yes | no | no | no | yes | no | no | pyt | NVIDIA Defined | Yes |
| Other | Optical Character Detection | No | No | Yes | Yes | No | yes | yes | no | no | no | No | No | Yes | Yes | no | No | pyt | NVDIA defined | no |
| OCR | Optical Character Recognition | No | No | Yes | Yes | No | yes | yes | no | no | no | No | No | yes | Yes | no | No | pyt | NVIDIA Defined | no |